

搭建全连接网络进行分类(糖尿病为例)
作者:小教学发布时间:2023-10-04分类:程序开发学习浏览:327
导读:拿来练手,大神请绕道。1.网上的代码大多都写在一个函数里,但是其实很多好论文都是把网络,数据训练等分开写的。2.分开写就是有一个需要注意的事情,就是要import要用...
拿来练手,大神请绕道。
1.网上的代码大多都写在一个函数里,但是其实很多好论文都是把网络,数据训练等分开写的。
2.分开写就是有一个需要注意的事情,就是要import 要用到的文件中的模型或者变量等。
3.全连接的回归也写了,有空再上传吧。
4.一般都是先写data或者model
import torch
import torch.nn as nn
import torch.nn.functional as F
#nn.func这个里面很多功能其实nn里就有,可以不导入,而且后面新的版本的torch也取消了cc.functional里面的部分函数
#定义网络,需要定义两部分,一部分就是初始化,另一部分就是数据流
class FCNet(nn.Module):
def __init__(self):
super(FCNet,self).__init__()
self.fc1 = nn.Linear(8,16)
#初始的这个8,要和你的数据的特征数一样才行,后面的数可以随意设置,但是不要太多,容易过拟合
# self.fc2 = nn.Linear(50,20)
self.fc3 = nn.Linear(16,2)#二分类,输出2,其实1也可以的
#最后的就是分类数,因为用的sigmod和交叉熵损失,就不用额外加softmax了,多分类要用softmax
self.sig = nn.Sigmoid()
# self.drop = nn.Dropout(0.3)
#可以把用到的放在这里,也可以用nn.Sequential()放在一起,这样后面的话就可以直接用这个,不用写那么多了
def forward(self,x):
x = self.sig(self.fc1(x))
# x = self.sig(self.fc2(x))
x = self.sig(self.fc3(x))
return x
#就是x要怎么在网络中走,要写一遍
#可以自己输出测试一下看看网络是不是自己想的那样,在真的调用的时候再屏蔽掉
# net= FCNet()
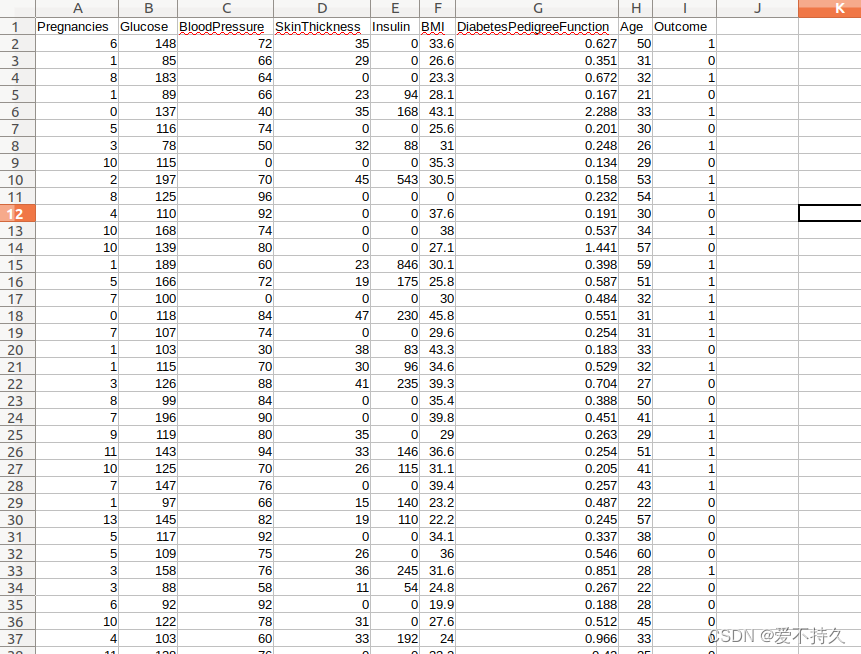
# print(net)首先看看数据是是啥样,outcome就是有没有糖尿病
其实可以手动把csv分成train和test
import pandas as pd
from sklearn.model_selection import train_test_split
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import numpy as np
#导入pands是为了读数据,当然使用numpy也可以读得,sklearn是为了把训练数据分为训练和验证集
data = pd.read_csv('./train.csv')
#就是把对应的数据哪出来,x代表的是feature上的data,y代表的是label,因为pd可以读到最上面的标签,所以从第2行(i=1)开始读就行
x = data.iloc[1:,:-1]
y = data.iloc[1:,[-1]]
#可以输出看看数据对不对,x中不应该包含labels
# print(x)
# print(y)
#test_size就是划分的比例,后面的是种子,意思是每次运行这个函数时候,0.8就是那些,0.2也还是每次一样,如果想要不一样,只要每次运行这个函数时候换个值就行
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=0)
#print(x_train,y_test)
# print(x_test,y_test)
#给数据进行归一化,可以用很多方法,我用最简单的归一到-1到1
x_train = x_train.apply(lambda x: (x - x.mean()) / (x.std()))
x_test = x_test.apply(lambda x: (x - x.mean()) / (x.std()))
#写dataset可以用两种方法,第一种就是 每一个数据自己单独处理,第二个就是要自己重写dataset类
#1.
# 可以使用分别的处理,把数据(首先转换为tensor,或者把dataframe.valus拿出来才能转换为tensor)转换为tensor并且数据类型转换为float32,如果测试没有真值,需要单独转换
# x_train = torch.tensor(np.array(x_train),dtype=torch.float32)
# y_train = torch.tensor(np.array(y_train),dtype=torch.float32)
# x_test = torch.tensor(np.array(x_test),dtype=torch.float32)
# y_test = torch.tensor(np.array(x_test),dtype=torch.float32)
# train_dataset = torch.utils.data.TensorDataset(x_train,y_train)
# test_dataset = torch.utils.data.TensorDataset(x_test,y_test)
#2.也可以直接重写dataset
class dataset(Dataset):
def __init__(self, x, y):
#把值拿出来或者变为np类型才能转换为tensor
# self.data = torch.tensor(x.values,dtype=torch.float32)
# self.labels = torch.tensor(y.values,dtype=torch.float32)
self.data = torch.tensor(np.array(x),dtype=torch.float32)
self.labels = torch.tensor(np.array(y),dtype=torch.float32)
def __len__(self):
return len(self.data)
def __getitem__(self,idx):
return self.data[idx],self.labels[idx]
#应该返回的是list类型,不是字典也不是set
BATCH_SIZE = 64
#验证集一般不用shuffle
train_dataset = dataset(x_train,y_train)
test_dataset = dataset(x_test,y_test)
# print(train_dataset)
train_loader = DataLoader(train_dataset,batch_size=BATCH_SIZE,shuffle=True)
test_lodaer = DataLoader(test_dataset,batch_size=BATCH_SIZE,shuffle=False)
# print(train_loader)然后就可以写train或者test了,其实test和train一样
from Model import FCNet
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import data
#导入要调用的net和data,也可以from data import xxx 这样可以直接用xxx,现在的这个需要用data.xxx
#看自己的设备,最好用gpu来跑
if (torch.cuda.is_available()):
my_device = torch.device('cuda')
else:
my_device = torch.device('cpu')
print(my_device)
#实例化一个net,并且放到gpu上,需要放到gpu上的有inputs,labels,net,loss
net = FCNet().to(my_device)
# print(net)
#定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
#一开始是不需要weight_decay(也就是l2正则化),可以等出现过拟合在用,也可以先用上
optimizer = optim.Adam(net.parameters(),lr=0.001,weight_decay=0.01)
epochs = 600
#定义train,因为一边训练一边验证,所有就把两个loader都放进去了,不过写法很多,也可以不放dataloader,放epoches也可以
def train(dataloader,valloader):
losses = []
acces = []
losses_val = []
for epoch in range(epochs):
loss_batch = 0
for i,data in enumerate(dataloader):
#需要注意的,这里的inputs和labels和之前定义的dataset相关,需要是list类型才可以
inputs,labels = data
#print(data)可以打印出来查看一下
inputs,labels = inputs.to(my_device),labels.to(my_device)
optimizer.zero_grad()#每次要梯度清零
outputs = net(inputs)
#print(outputs)
#model的最后一层是sigmod
#labels的格式需要注意,因为现在是[[1],[0],[1],[1]..]这样得格式,无法放到交叉熵了,需要时[0,1,1,1...]这样得格式才行
loss = criterion(outputs,labels.squeeze(1).long()).to(my_device)
#print(labels.squeeze(1).long())
loss.backward()
optimizer.step()
loss_batch += loss.item()
length = i
#验证的时候不用反向传播和梯度下降这些
net.eval()
count = 0
right = 0
loss_batch_val =0
with torch.no_grad():
for j,data2 in enumerate(valloader):
val_inputs,val_labels = data2
val_inputs,val_labels = val_inputs.to(my_device),val_labels.squeeze(1).long().to(my_device)
val_outputs = net(val_inputs)
loss_val = criterion(val_outputs,val_labels)
#因为net的最后一层是2,所以输出的是2维的【0.6,0.4】这种,但是这个可以直接放到交叉熵中
#——中放的是概率,pred中放的是预测的类别,算损失还是要用outputs,但是算准确率就是用pred和真实labels相比了
_,pred = torch.max(val_outputs,1)
#print(pred)
right = (pred == val_labels).sum().item()
count = len(val_labels)
acc = right/count
loss_batch_val += loss_val.item()
length2 = j
if epoch % 10 == 9:
print('train_epoch:',epoch+1,'train_loss:',loss_batch/length,'val_loss:',loss_batch_val/length2,'acc:',acc)
losses.append(loss_batch/length)
acces.append(acc)
losses_val.append(loss_batch_val/length2)
#可以画一些曲线,输出一些值
plt.plot(range(60),losses,color ='blue',label ='train_loss')
plt.plot(range(60),acces, color ='red',label ='val_acc')
plt.plot(range(60),losses_val,color ='yellow',label ='val_loss')
plt.legend()
plt.show()
torch.save(net.state_dict(),'./weights_epoch1000.pth')
#保存参数
train(data.train_loader,data.test_lodaer)最后看一下结果,最后的准确率在85%左右,还可以,毕竟数据不多,也是简单的全连接。

在这个结果之前出现了很多问题,比如波动很大,损失先降后升等问题,找个有问题的图
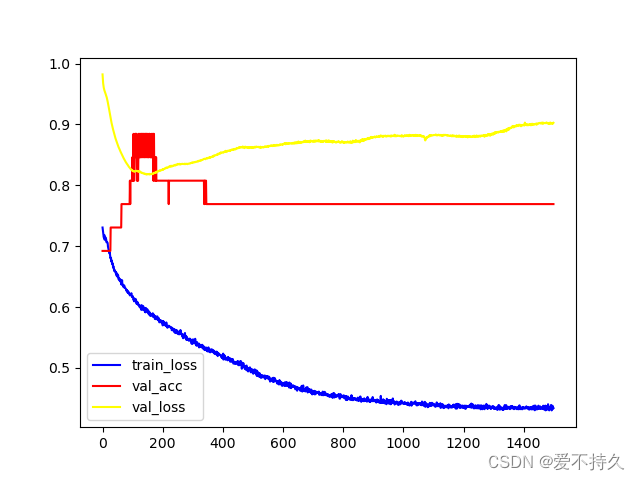
下面是一些总结:
1.跳跃很大,波动:增大batch_size,减小lr。
2.降低过拟合:
a.降低模型的复杂程度,但是修改具体的神经元个数,因为这个网络本身就不大,所有没啥用,模型非常大没准会有用。
b.batchsize增大,lr减小是有效的。
c.输入数据进行归一化是有用的,归一化之后lr可以调大一点,收敛变快了。
d.L2正则化是有用的,很有用。dropout应该也有用,但是模型本来就很小,我试了试没啥差别。而且有正则化之后可以加速收敛,lr可以稍微调大一点,较少的epoches也可以收敛了,而已acc也会更高一点,稳定一点。
- 上一篇:百度搜索逐步恢复优质网站权限
- 下一篇:Matlab随机数的产生
- 程序开发学习排行
- 最近发表