

【小笔记】fasttext文本分类问题分析
作者:小教学发布时间:2023-09-29分类:程序开发学习浏览:248
【学而不思则罔,思维不学则怠】
2023.9.28
关于fasttext的原理及实战文章很多,我也尝试在自己的任务中进行使用,是一个典型的短文本分类任务,对知识图谱抽取的实体进行校验,判断实体类别是否正确,我构建了27000个样本,3种类别(A,B,C),经过调参,最好的F1只有0.61,感觉这就是它的天花板了,在网上看到很多人在自己的场景中都能达到0.8、0.9之类的,我就在想,为什么我这个提不上去。
可能的原因有一下几个:
1.数据量不够?
比如知乎有个人做7分类的数据量也差不多,但他的性能很不错。
相比较而言,我这边每类样本接近1W,我个人感觉对于这个轻量级模型是够了。
2.类别不均衡导致?
我这边三中类别的数据比例分别是1:1:0.7,应该还好,不算很极端的类别不均衡。
Q:fasttext对类别不均衡敏不敏感?
敏感
3.数据中有噪声?
数据中是有噪声,会有那种错误分类的样本存在,但应该不是很多。
4.F1被平均?
我用过测试发现,算法在我应用场景中,基本上能把错误分类的A给识别出来并进行准确分类,但是会把正确的B给错误分类成A,而且比例比较高。
说明B很容易被分类为A,B这个类别的P应该不高,算法对三种类别的分类性能不一致,0.61是被平均的结果(待验证)
5.文本太长了,N-gram无法准确捕捉语义信息?
网上的一种主流声音是fasttext适合短文本分类,究其原因是fast对于语序特征不能很好的提取,虽然它考虑用n-grams来捕捉一些语序特征(即图中的N-gram特征),但N通常不会太大,如2-3,这样小的一个窗口,是很难捕捉长距离的语义信息的。(多说一点,transformer和bert添加了专门的位置编码来记录语序信息)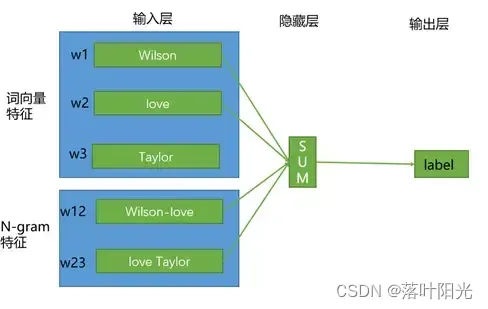
如下面的句子:
- 这电影不是很好看,但我还是很喜欢它
- 这电影是很好看,但我还是不喜欢它
- 我不喜欢这电影,但它还是很好看
其中第1、3句整体极性是positive,但第2句整体极性就是negative。
分析上述例子:
- 在词向量特征层面,三个句子非常接近,很难区分
- 在N-gram特征层面,比如N=3,会发现第2句和第3句也很难区分。
因此,fasttext只是通过简单的取向量的平均来作为s句向量进行分类,很难学出词序对句子语义的影响。
换句话说,fasttext不适合这类对语序特征敏感的场景。
我的场景中有一些比较接近但类别不同的短文本,如“方向盘”为A,“打方向”、“打方向盘”为C,这类文本很可能会导致分类混淆。(待验证)
6.文本太短了,N-Gram特征无法准确用于分类?
我数据中有很多文本的长度比较短,甚至只有一两个字,:“异响”,“亮”,“不亮”,针对这类文本,fast的N-gram有效吗?
(待验证)
- 程序开发学习排行
- 最近发表