

Redis代码实践总结(一)
作者:小教学发布时间:2023-09-28分类:程序开发学习浏览:253
一、背景: redis从安装到实践,做一些具体的记录。
1.1 Redis和 RedisStack和Redis Enterprise
redis简介
Redis 是一种开源(BSD 许可)内存中数据结构存储,用作数据库、缓存、消息代理和流引擎。
Redis 提供数据结构,例如 字符串、散列、列表、集合、带范围查询的排序集、位图、超级日志、地理空间索引和流。
Redis 具有内置复制、Lua 脚本、LRU 驱逐、事务和不同级别的磁盘持久性,并通过Redis Sentinel和Redis Cluster自动分区提供高可用性。
您可以对这些类型运行原子操作 ,例如附加到字符串; 增加哈希中的值;将元素推入列表;计算集合的交、 并、差;或获取排序集中排名最高的成员。
为了实现最佳性能,Redis 使用 内存数据集。
根据您的使用案例,Redis 可以通过定期将数据集转储到磁盘 或将每个命令附加到基于磁盘的日志来持久保存您的数据。如果您只需要功能丰富的网络内存缓存,您还可以禁用持久性。
Redis 支持异步复制,具有快速非阻塞同步和自动重新连接以及网络分割上的部分重新同步。
Redis 还包括:
交易
发布/订阅
Lua脚本
密钥的生存时间有限
LRU 驱逐键
自动故障转移
总结:
1. 这是从官网摘抄的介绍,实际上点明了redis的用处和使用场景。换句话说,如果我们能知道简介里的这些功能是如何使用的,那redis也就掌握了。
2.一般我称呼redis叫内存数据库。
redisStack简介
除了Redis OSS的所有功能之外,Redis Stack还支持:
1、概率数据结构 ; 2、可查询的 JSON 文档;3、 跨哈希和 JSON 文档查询; 4、时间序列数据支持(摄取和查询),包括全文搜索
Redis Stack 的创建是为了让开发人员能够使用后端数据平台构建实时应用程序,该平台可以在毫秒或更短的时间内可靠地处理请求。
开始使用 Redis Stack 的最佳方法是使用RedisInsight,这是一个用于理解和优化 Redis 数据的可视化工具。
RedisInsight 允许您:
使用浏览器工具直观地查看数据结构,并根据名称空间对键进行分组。
在大多数 Redis Stack 数据结构上使用 CRUD。
利用 Workbench,这是一种高级命令行界面,具有智能命令自动完成功能和复杂的数据可视化功能。
使用 Profiler 工具实时分析 Redis 的流量。
随时使用嵌入式 Redis CLI。
使用内存分析工具分析内存使用情况。
使用 Slowlog 工具识别并排除瓶颈。
总结: 看介绍,这是给我们提供了一个可见页面和更多工具用来观测和使用redis的桌面UI工具。从运维的角度来说, 看起来不错。但我还没用过。试过后会补充一些介绍的。
Redis Enterprise
企业级 Redis,可在本地和云中(在 AWS、Google Cloud 或 Azure 上)使用。Redis Enterprise 简化了操作、扩展和多租户,包括许多集成(例如 Kubernetes),并提供多层支持。
总结: 看起来不错,但也许你在跨国外企工作时,才有必要使用它。毫无疑问。它和阿里的redis内存数据库Tair一样,都是收费的。当你作为项目经理时,你才需要考虑这两者的收费标准。
二、开始使用 Redis
2.1 安装和调试
学习在linux上安装就可以了。
- 安装包下载。
你可以在redis官网( https://redis.io/download/)或者github(https://github.com/redis/redis)上下载最新版本。 建议选择tar.gz压缩格式的版本包。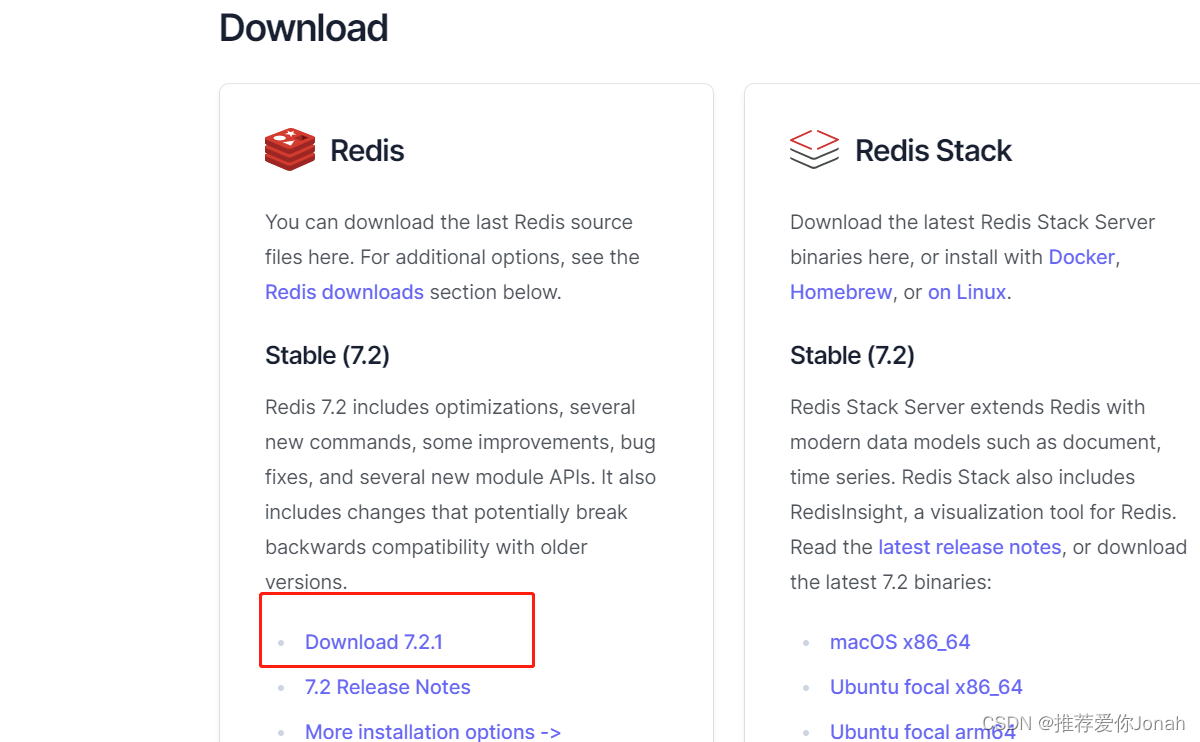
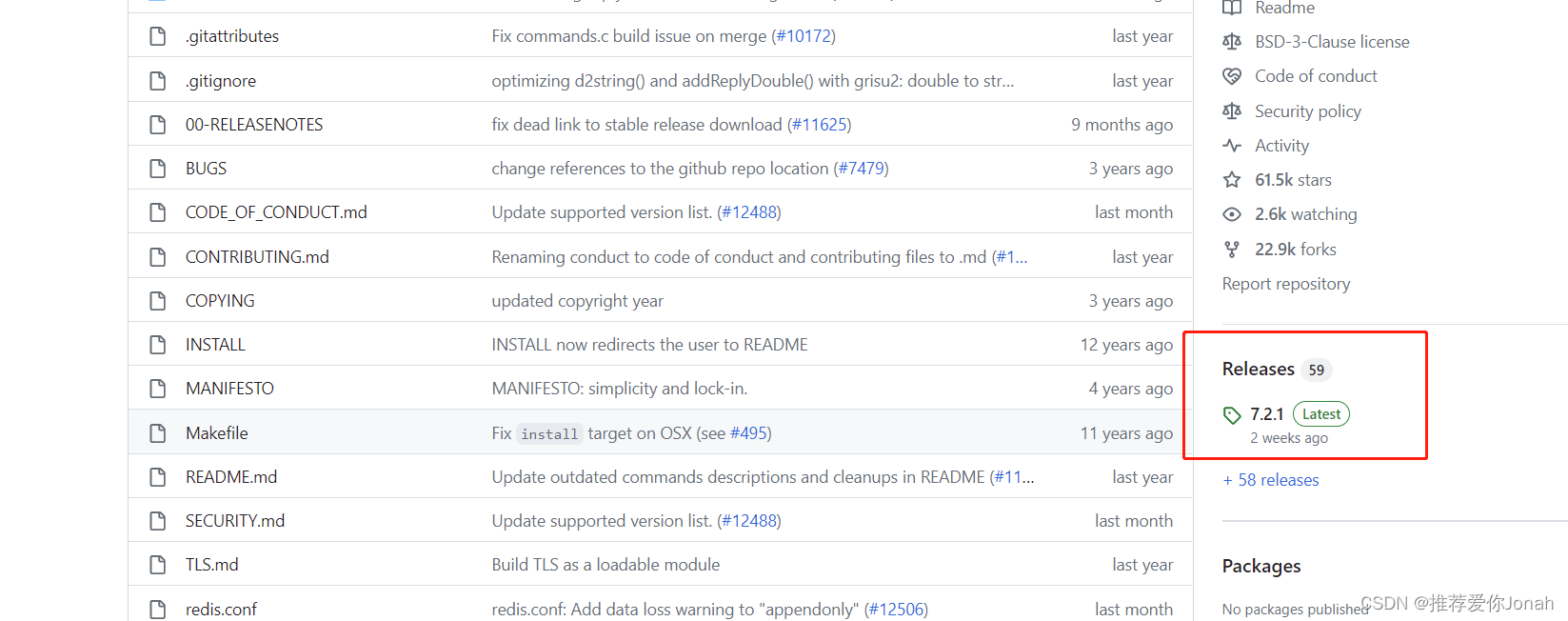
二、选择一个服务器,把包放上去解压,然后运行,最后查看结果。
推荐在/usr/local目录下解压。 解压命令是
tar -xzvf redis-7.2.1.tar.gz
这样你就会有一个redis-7.2.1的文件夹出现了
接下来是进入redis目录,执行make命令,会有很多编译过程的输出,等几分钟,让它执行完。
cd redis-7.2.1
make
make install
如果编译成功,您将在src目录中找到几个Redis二进制文件,包括:
- redis-server:Redis 服务器本身
- redis-cli是与 Redis 交互的命令行界面实用程序。
启动和停止
#前台启动
redis-server
#后台启动
redis-server&
Ctrl-c可以停止redis
或者这样停止Redis
$ redis-cli shutdown
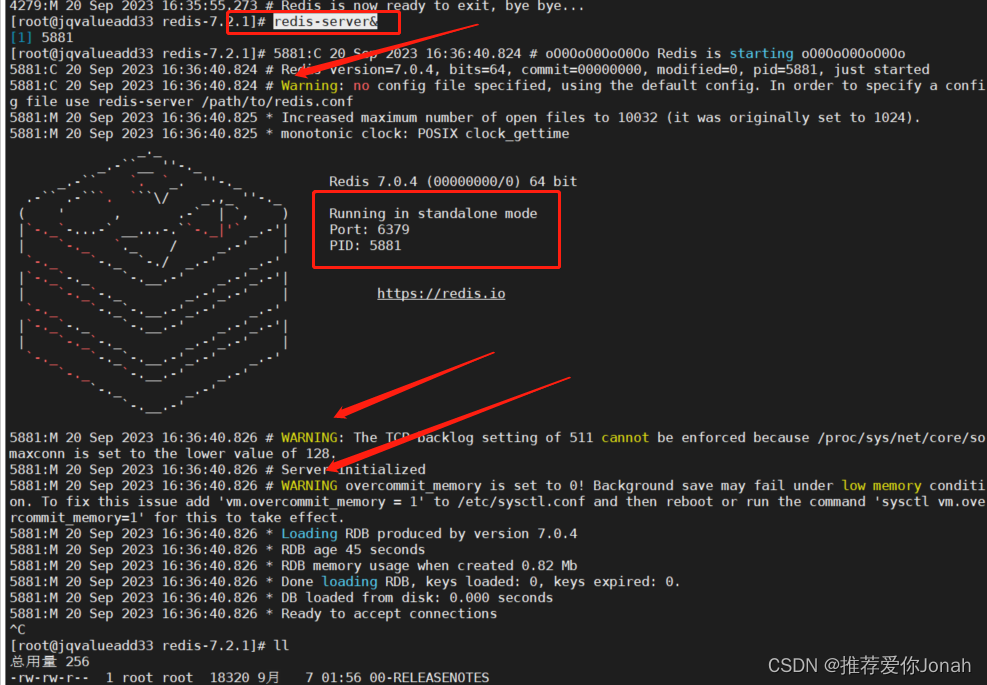
总结: 上面的操作可以对照官网执行,一般这样就可以得到一个启动的redis了。下面是一些多的实践部分。上面图片执行redis-server启动命令后,启动日志里出现了三个warning,下面是解析:
Waring1: 警告表示没有指定配置文件,所以Redis使用默认配置。要使用特定的配置文件,可以使用这个命令指定。
[root@jqvalueadd33 src]# ./redis-server ../redis.conf
redis.conf文件很重要,有很多参数配置,有的配置我们需要做一些修改。准备在后面文章分析配置文件
waring2: 警告表示,尽管Redis试图将TCP的backlog设置为511,但由于系统的/proc/sys/net/core/somaxconn值为128,所以这个设置无法生效。
waring3:警告表示overcommit_memory设置为0可能会在低内存情况下导致背景保存失败。
实际使用中,我建议是忽略掉这个警告。当然,如果你想多了解一些,你可以往下看,不然建议跳过这一部分。
为了修复这个问题,建议在/etc/sysctl.conf中设置vm.overcommit_memory = 1,然后重启或执行指定的命令。
redis官网对这个问题有一些描述,摘抄如下:
Linux 上的后台保存失败并出现 fork() 错误?
简短的回答:echo 1 > /proc/sys/vm/overcommit_memory:)
现在是长篇: forkRedis 后台保存模式依赖于现代操作系统中系统调用的写时复制语义:Redis fork(创建子进程),它是父进程的精确副本。子进程将数据库转储到磁盘上并最终退出。理论上,子进程应该使用与作为副本的父进程一样多的内存,但实际上,由于大多数现代操作系统实现的写时复制语义,父进程和子进程将共享公共内存页面。仅当子页面或父页面发生更改时,页面才会被复制。由于理论上在子进程保存时所有页面都可能发生变化,Linux无法提前知道子进程将占用多少内存,因此如果overcommit_memory如果设置为零,则 fork 将失败,除非有足够多的可用 RAM 来真正复制所有父内存页面。如果您有 3 GB 的 Redis 数据集并且只有 2 GB 的可用内存,它将失败。
设置overcommit_memory为 1 告诉 Linux 放松并以更乐观
下面是我的一些理解:
当我们需要把redis的数据fork到磁盘时,生成一个RDB(Redis数据库快照)文件。 而fork动作会需要linux分配父进程一样多的内存。但实际上使用过程中,父进程和子进程会共享很大一部分内存,而单独使用少部分内存。
overcommit_memory如果设置为零,当物理内存和交换空间不足以分配,那么fork会直接失败,数据持久化到磁盘失败。
overcommit_memory如果设置为1,当物理内存和交换空间不足以分配,会允许fork,持久化会成功,但也有OOM的风险。
overcommit_memory设置:overcommit_memory是Linux内核参数之一,用于控制内存分配策略。它有三个可能的值::
0:表示严格模式,内核将拒绝分配超过物理内存和交换空间总和的内存。这是默认设置。
1:表示按需分配模式,内核允许分配超过物理内存和交换空间总和的内存,但在实际使用时可能会导致OOM(Out of Memory)错误。
2:表示总是允许内存分配,无论物理内存和交换空间的状态如何。
解决方法:为了避免Redis后台保存操作中的fork错误,通常会建议将overcommit_memory设置为1。这允许操作系统更宽松地分配内存,从而更容易执行fork。您可以使用以下命令将overcommit_memory设置为1
fork()动作生成RDB文件的好处:
持久化数据:Redis是一个内存数据库,它将数据存储在内存中以提供高速读写访问。然而,为了确保数据在断电或服务器重启时不会丢失,需要将数据持久化到磁盘上。后台保存是一种将内存中的数据保存到硬盘上的方式,以便在需要时能够恢复数据。
备份数据:后台保存操作的结果是生成一个RDB(Redis数据库快照)文件,该文件包含了Redis数据库的当前状态。这个RDB文件可以用于数据备份和恢复。它提供了一种简单的方法来创建数据库的点对点备份,以防止数据丢失或损坏。
性能优化:由于将数据写入磁盘通常比写入内存慢得多,如果在主线程中执行保存操作,它可能会阻塞Redis服务器的正常响应请求。通过使用后台保存操作,Redis可以将数据保存到磁盘而不会阻塞主进程,从而保持了响应性能。
节省资源:后台保存操作通常是在一个单独的子进程中执行的,这个子进程是通过fork从父进程创建的。由于父进程和子进程共享相同的内存,子进程可以利用写时复制(Copy-On-Write)技术,只有在需要修改数据时才会复制内存页面,因此在保存期间节省了内存资源。
总之,Redis使用fork创建子进程来执行后台保存操作的主要目的是确保数据的持久性、提供备份和恢复功能、优化性能以及节省内存资源。这使得Redis在内存数据库的同时,也具备了数据持久性和可靠性的特性。
- 程序开发学习排行
- 最近发表