

Hudi第二章:集成Spark
作者:小教学发布时间:2023-10-04分类:程序开发学习浏览:336
系列文章目录
Hudi第一章:编译安装
Hudi第二章:集成Spark
文章目录
- 系列文章目录
- 前言
- 一、安装Spark
- 1、安装Spark
- 2.安装hive
- 二、spark-shell
- 1.启动命令
- 2.插入数据
- 3.查询数据
- 1.转换DF
- 2.查询
- 3.更新
- 4.时间旅行
- 5.增量查询
- 6.指定时间点查询
- 7.删除数据
- 1.获取总行数
- 2.取其中2条用来删除
- 3.将待删除的2条数据构建DF
- 4.执行删除
- 5.统计删除数据后的行数,验证删除是否成功
- 三、Spark-SQL
- 1.启动Spark-sql
- 2.建表
- 1.创建非分区表
- 2.创建分区表
- 3.在已有的hudi表上创建新表
- CTAS
- 2.插入数据
- 3.查询
- 4.时间旅行
- 5.更新数据
- 1.update
- 2.MergeInto
- 5.删除数据
- 6.覆盖表
- 7.修改表
- 8.修改分区
- 总结
前言
Hudi可以使用Spark作为搜索引擎。我们写博客记录一下,不知道一次能不能写完。
一、安装Spark
1、安装Spark
只需要简单的上传解压再添加环境变量即可。不做过多演示,具体可以看我之前的博客。
spark第一章:环境安装
spark版本我选用的是3.2。在这里留一个官方的下载地址。
spark-3.2.2-bin-hadoop3.2.tgz
然后我们从编译好的hudi文件夹中,将spark与hudi连接的jar包放入spark中。
cp /opt/software/hudi-0.12.0/packaging/hudi-spark-bundle/target/hudi-spark3.2-bundle_2.12-0.12.0.jar /opt/module/spark-3.2.2/jars/
然后需要启动hadoop
2.安装hive
后边hudi会依赖hive的Metastore和HiveServer2
Hive3第一章:环境安装
二、spark-shell
其中大部分命令和Spark很接近,建议学过Spark-shell之后再来学习这一部分。
1.启动命令
#针对Spark 3.2
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
2.插入数据
dataGen.generateInserts是hudi提供的测试数据生成api,以下是固定写法
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
说一下这几个参数。
RECORDKEY_FIELD_OPT_KEY:可以理解为MYSQL里的主键。
RECORDKEY_FIELD_OPT_KEY:预聚合字段,当主键相同时,以该字段大小决定,一般用ts字段,也就是时间戳。
PARTITIONPATH_FIELD_OPT_KEY:分区字段
TABLE_NAME:表名称
可以新开一个窗口在本地看一下
3.查询数据
1.转换DF
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
2.查询
spark.sql(“select fare, begin_lon, begin_lat, uuid, ts from hudi_trips_snapshot where fare > 20.0”).show()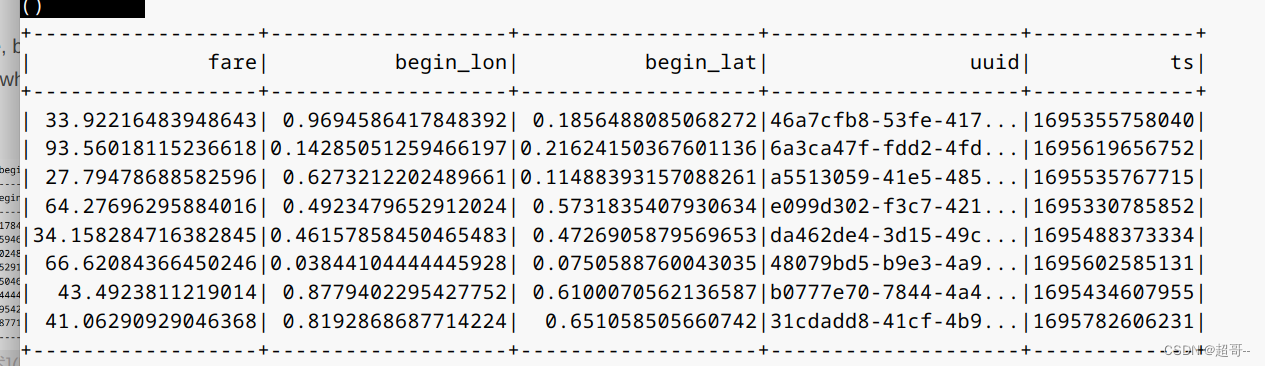
3.更新
和插入数据差不多,但是需要把mode从Overwrite换成Append。将其从覆盖编程追加
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
更新之后我们再次查询。
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select fare, begin_lon, begin_lat, uuid, ts from hudi_trips_snapshot where fare > 20.0").show()
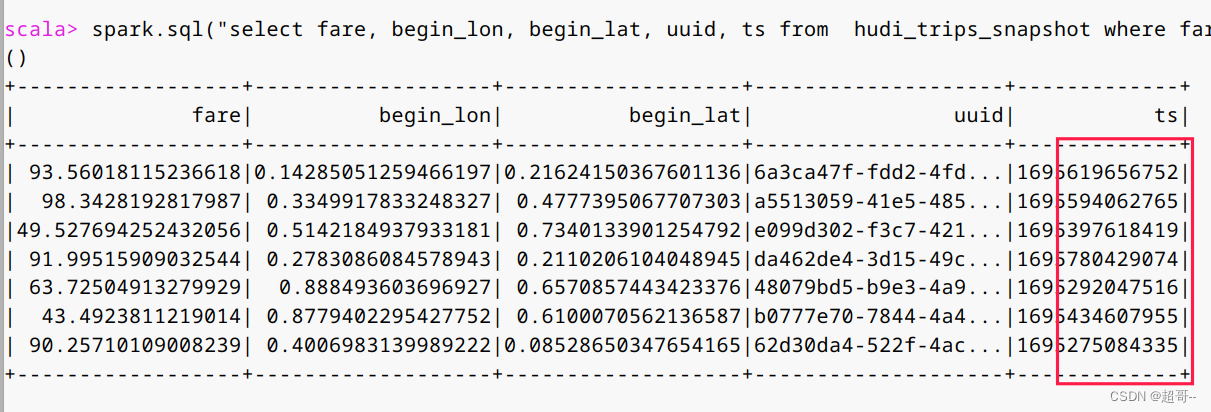
可以看到ts明显增大
4.时间旅行
当数据不断更新时,我们该如何寻找更新前的数据。这个在MYSQL数据库中是没有的,但hudi有,我们只需要找到当初更新数据的时间戳即可。
spark.sql("select _hoodie_commit_time, ts, uuid, fare from hudi_trips_snapshot").show()
因为我们只有两次提交,所以我们只有两种时间戳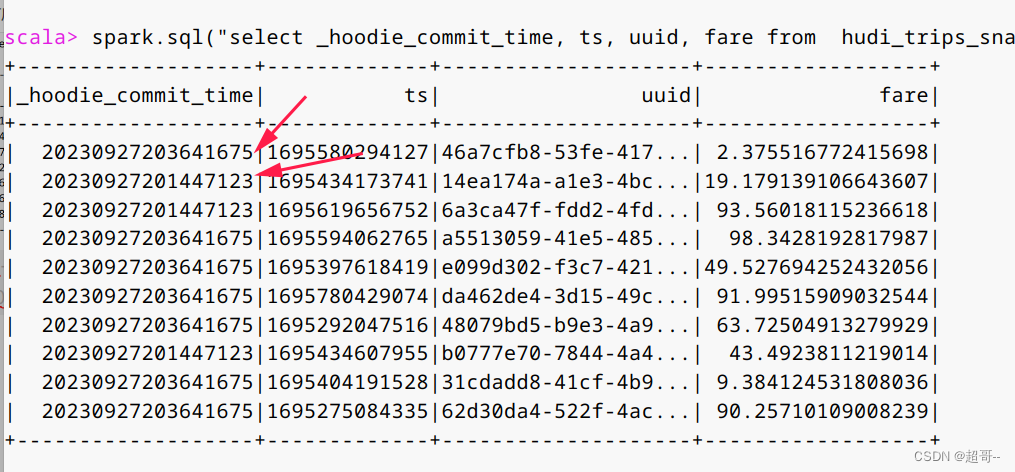
这就是最简单的年月日时分秒。
现在我们回到第一次提交时的数据。
val tripsSnapshotDF1 = spark.read.
format("hudi").
option("as.of.instant", "20230927201447123").
load(basePath)
tripsSnapshotDF1.createOrReplaceTempView("hudi_trips_snapshot1")
现在在新的虚拟表中查询。
spark.sql("select fare, begin_lon, begin_lat, uuid, ts from hudi_trips_snapshot1 where fare > 20.0").show()
随便找一条对比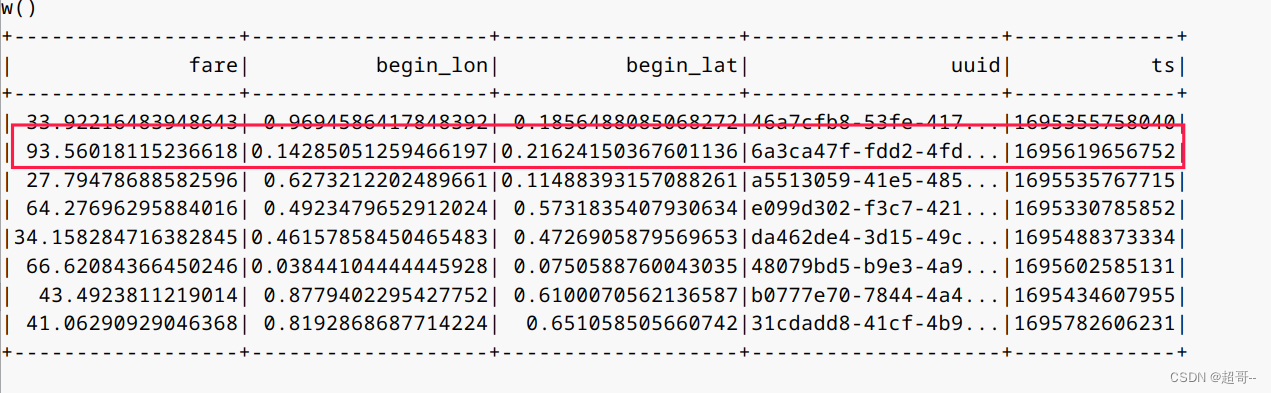
可以看到和之前的第一条是一样的。
时间旅行还可以这样写
spark.read.
format(“hudi”).
option(“as.of.instant”, “2023-09-27 20:14:47:123”).
load(basePath)
效果和上边一样。
5.增量查询
查询某一次提交之后的数据。
现在我在插入三次数据。
重复执行三次
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
然后重新生成虚拟表
spark.
read.
format("hudi").
load(basePath).
createOrReplaceTempView("hudi_trips_snapshot")
因为每次提交,查询时间会被覆盖,所以我们选择从本地获取。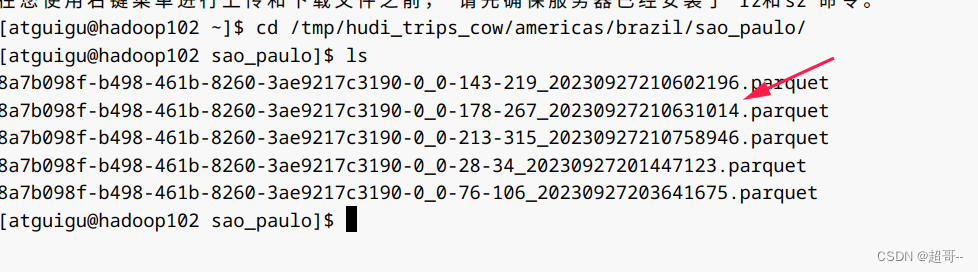
咱们选择第四次之后的数据
val beginTime = "20230927210631014"
# 增量查询表
val tripsIncrementalDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
load(basePath)
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental").show()
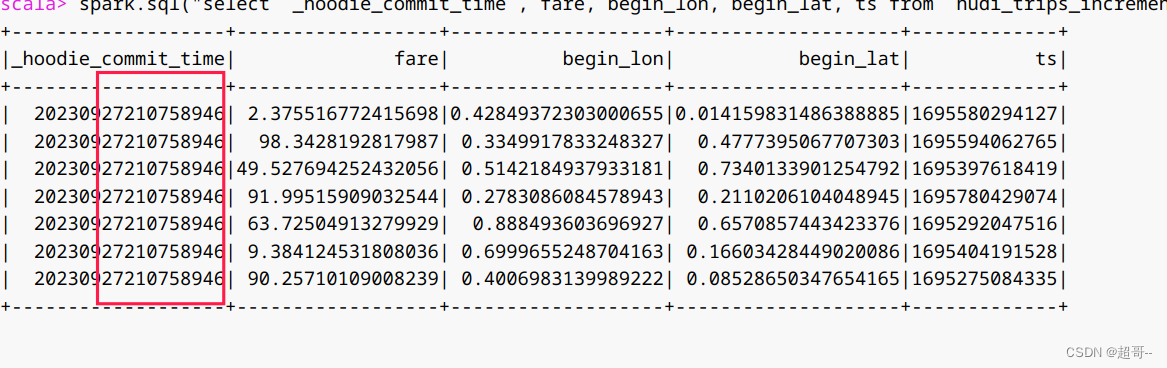
可以看到都是第四次之后的数据。
6.指定时间点查询
增量查询可以查询某一次提交之后的数据,指定时间点查询可以查询,一段时间内的数据。
val beginTime = "000"
val endTime = "20230927210631014"
val tripsPointInTimeDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
option(END_INSTANTTIME_OPT_KEY, endTime).
load(basePath)
tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time")
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where").show()
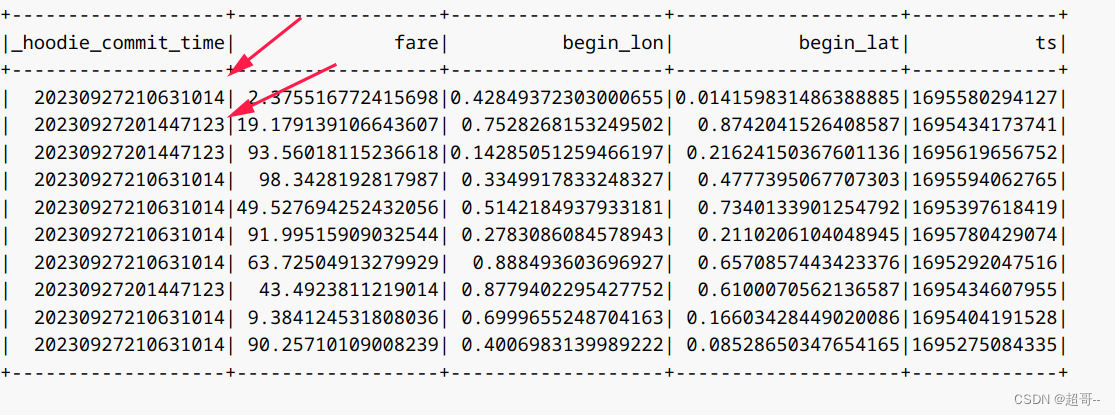
都是endTime之前的。
7.删除数据
1.获取总行数
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()

2.取其中2条用来删除
val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2)
3.将待删除的2条数据构建DF
val deletes = dataGen.generateDeletes(ds.collectAsList())
val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2))
4.执行删除
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY,"delete").
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
5.统计删除数据后的行数,验证删除是否成功
val roAfterDeleteViewDF = spark.
read.
format("hudi").
load(basePath)
roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot")
// 返回的总行数应该比原来少2行
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()

三、Spark-SQL
1.启动Spark-sql
#针对Spark 3.2
spark-sql \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
2.建表
单独创建一个数据库,用作学习。
create database spark_hudi;
use spark_hudi;
1.创建非分区表
hudi中默认分为cow和mor两种表,他们后台的存储方式不太一样,但是前端看起来没区别。
创建一个cow表,默认primaryKey ‘uuid’,不提供preCombineField
create table hudi_cow_nonpcf_tbl (
uuid int,
name string,
price double
) using hudi;
创建一个mor非分区表
create table hudi_mor_tbl (
id int,
name string,
price double,
ts bigint
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'ts'
);
2.创建分区表
创建一个cow分区外部表,指定primaryKey和preCombineField
create table hudi_cow_pt_tbl (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh)
location '/tmp/hudi/hudi_cow_pt_tbl';
3.在已有的hudi表上创建新表
create table hudi_existing_tbl0 using hudi
location 'file:///tmp/hudi/dataframe_hudi_nonpt_table';
create table hudi_existing_tbl1 using hudi
partitioned by (dt, hh)
location 'file:///tmp/hudi/dataframe_hudi_pt_table';
因为实际路径上并没有数据,所以就不创建了。
CTAS
Create Table As Select
为了提高向hudi表加载数据的性能,CTAS使用批量插入作为写操作,所以也可以用来插入数据。
通过CTAS创建cow非分区表,不指定preCombineField
create table hudi_ctas_cow_nonpcf_tbl
using hudi
tblproperties (primaryKey = 'id')
as
select 1 as id, 'a1' as name, 10 as price;

通过CTAS创建cow分区表,指定preCombineField
create table hudi_ctas_cow_pt_tbl
using hudi
tblproperties (type = 'cow', primaryKey = 'id', preCombineField = 'ts')
partitioned by (dt)
as
select 1 as id, 'a1' as name, 10 as price, 1000 as ts, '2021-12-01' as dt;
通过CTAS从其他表加载数据
了解即可
# 创建内部表
create table parquet_mngd using parquet location 'file:///tmp/parquet_dataset/*.parquet';
# 通过CTAS加载数据
create table hudi_ctas_cow_pt_tbl2 using hudi location 'file:/tmp/hudi/hudi_tbl/' options (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (datestr) as select * from parquet_mngd;
2.插入数据
向非分区表插入数据
insert into hudi_cow_nonpcf_tbl select 1, 'a1', 20;
insert into hudi_mor_tbl select 1, 'a1', 20, 1000;
向分区表动态分区插入数据
insert into hudi_cow_pt_tbl partition (dt, hh)
select 1 as id, 'a1' as name, 1000 as ts, '2021-12-09' as dt, '10' as hh;
向分区表静态分区插入数据
insert into hudi_cow_pt_tbl partition(dt = '2021-12-09', hh='11') select 2, 'a2', 1000;
3.查询
和基本的SQL语句一样
select name,price from hudi_cow_nonpcf_tbl;

4.时间旅行
建一张新表
create table hudi_cow_pt_tbl1 (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh)
location '/tmp/hudi/hudi_cow_pt_tbl1';
插入一条数据并查询
insert into hudi_cow_pt_tbl1 select 1, 'a0', 1000, '2023-09-29', '10';
select * from hudi_cow_pt_tbl1;

现在我们更新这条数据再次查询。
insert into hudi_cow_pt_tbl1 select 1, 'a1', 1001, '2023-09-29', '10';
select * from hudi_cow_pt_tbl1;

可以看到第二次的ts更大,所以name已经更新,现在我们进行时间旅行,找到刚刚的时间戳。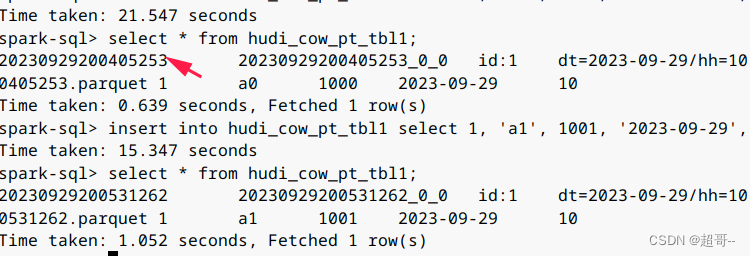
select * from hudi_cow_pt_tbl1 timestamp as of '20230929200405253';

这就可以查询到之前的数据。
5.更新数据
1.update
hudi也是可以使用update更新数据的。
先查看一下
select * from hudi_mor_tbl ;

在更新数据。
update hudi_mor_tbl set price = price * 2, ts = 1111 where id = 1;
select * from hudi_mor_tbl ;

2.MergeInto
这个语法有点类似于join,用于两张表的拼接。
创建一张表,并插入数据。
create table merge_source (id int, name string, price double, ts bigint) using hudi
tblproperties (primaryKey = 'id', preCombineField = 'ts');
insert into merge_source values (1, "old_a1", 22.22, 2900), (2, "new_a2", 33.33, 2000), (3, "new_a3", 44.44, 2000);
我们将新表的内容插入hudi_mor_tbl
merge into hudi_mor_tbl as target
using merge_source as source
on target.id = source.id
when matched then update set *
when not matched then insert *;
查看hudi_mor_tbl。
select * from hudi_mor_tbl ;

5.删除数据
delete from hudi_mor_tbl where id = 1;
select * from hudi_mor_tbl ;

6.覆盖表
insert overwrite hudi_mor_tbl select 99, 'a99', 20.0, 900;
select * from hudi_mor_tbl ;

7.修改表
修改语法
– Alter table name
ALTER TABLE oldTableName RENAME TO newTableName
– Alter table add columns
ALTER TABLE tableIdentifier ADD COLUMNS(colAndType (,colAndType)*)
– Alter table column type
ALTER TABLE tableIdentifier CHANGE COLUMN colName colName colType
– Alter table properties
ALTER TABLE tableIdentifier SET TBLPROPERTIES (key = ‘value’)
这么我们修改表名做个实例。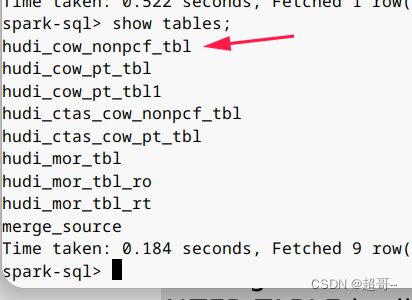
ALTER TABLE hudi_cow_nonpcf_tbl RENAME TO hudi_cow_nonpcf_tbl1;
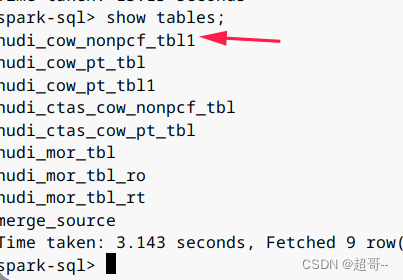
8.修改分区
show partitions hudi_cow_pt_tbl1;
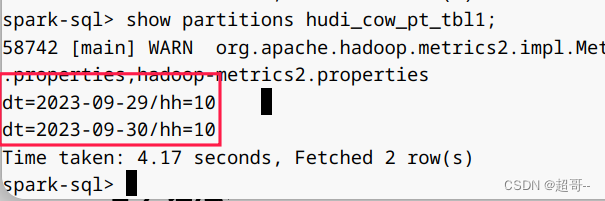
alter table hudi_cow_pt_tbl1 drop partition (dt='2023-09-29', hh='10');
show partitions hudi_cow_pt_tbl1;

总结
这一次就写到这里,东西比较多,关于Spark的东西还要在写一次。
- 上一篇:微服务保护(Sentinel)
- 下一篇:AI赋能的3D资产管理
- 程序开发学习排行
- 最近发表