

【大数据存储与处理】1. hadoop单机伪分布安装和集群安装
作者:小教学发布时间:2023-10-04分类:程序开发学习浏览:298
0. 写在前面
0.1 软件版本
hadoop2.10.2
ubuntu20.04
openjdk-8-jdk
0.2 hadoop介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 .—百度词条hadoop
1. 创建hadoop用户
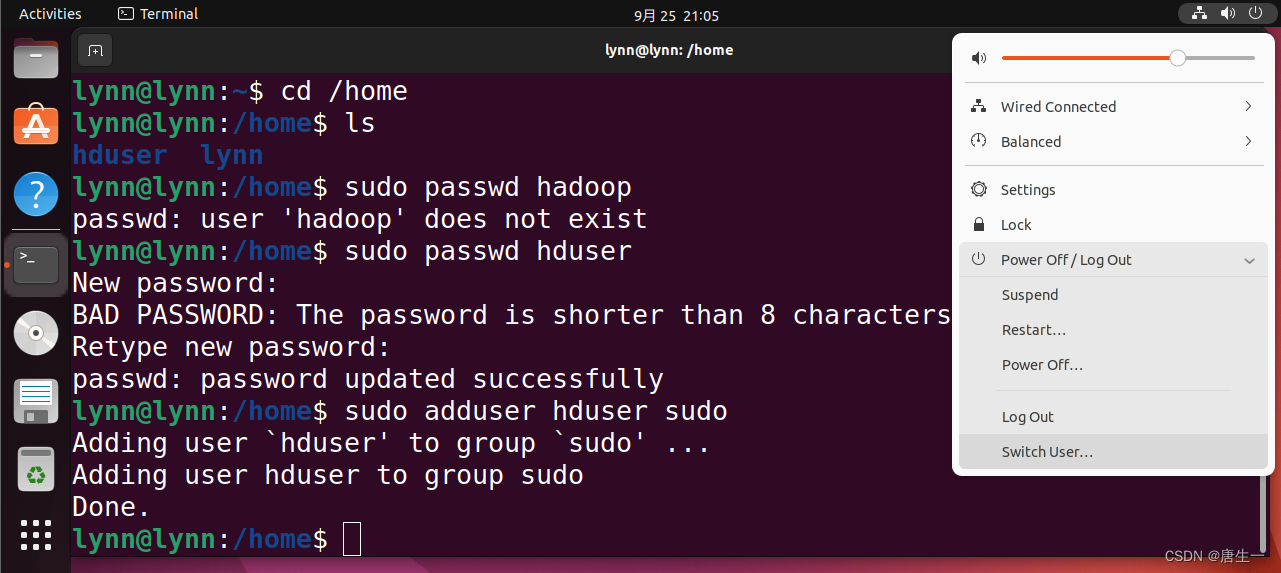
lynn@lynn:~$ sudo useradd -m hduser -s /bin/bash # 创建用户hduser 并指定使用bash终端作为shell
lynn@lynn:~$ cd /home
lynn@lynn:~$ ls
hduser lynn # 代表用户创建成功
lynn@lynn:~$ sudo passwd hduser # 设置密码
lynn@lynn:~$ sudo adduser hduser sudo # 为hduser增加管理员权限
Adding user `hduser' to group `sudo' ...
Adding user hduser to group sudo
Done.
# 然后切换用户登录
2. 安装java
注意,已经切换到了hduser用户,lynn主机下
hduser@lynn:~$ sudo apt-get update # 更新包
# The "unable to lock directory /var/lib/apt/lists/" error on Ubuntu typically occurs when the APT package management system is already running or has crashed.如果出现unable to lock,多数是因为APT包管理系统正在运行或崩溃,可尝试重启
# hduser@lynn:~$ ps aux | grep -i apt # 可使用此命令查看哪些安装在使用apt,如果有则等待这些安装完成
# The error in Ubuntu may be displayed below:
# /var/lib/dpkg/lock
# /var/lib/dpkg/lock-frontend
# /var/lib/apt/lists/lock
# /var/cache/apt/archives/lock
# These are lock files, which could prevent two instances of apt or dpkg from using the same files simultaneously.
# This could occur if an installation is needed or did not finish. Just remove the lock files.
# To delete or erase the lock files, use the rm command:
# sudo rm /var/lib/dpkg/lock
# sudo rm /var/lib/apt/lists/lock
# sudo rm /var/cache/apt/archives/lock
hduser@lynn:~$ sudo apt search jdk # 查找jdk包,也可以直接运行下一条命令
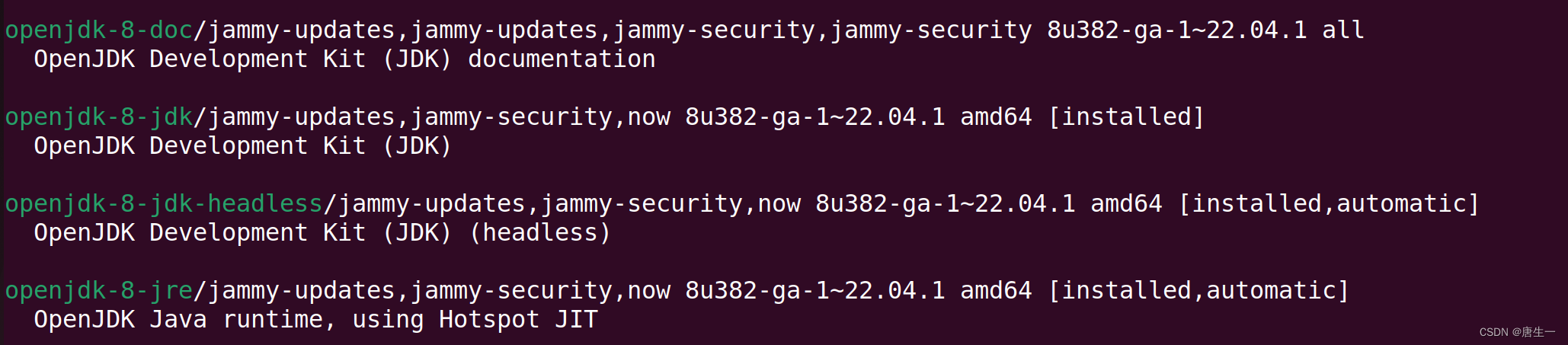
# 安装openjdk-8-jdk版本
hduser@lynn:~$ sudo apt install openjdk-8-jdk
# 安装完成之后查看一下版本号,确认安装成功
hduser@lynn:~$ java -version
hduser@lynn:~$ javac -version
hduser@lynn:~$ update-alternatives --display java # 查看已安装的java版本列表
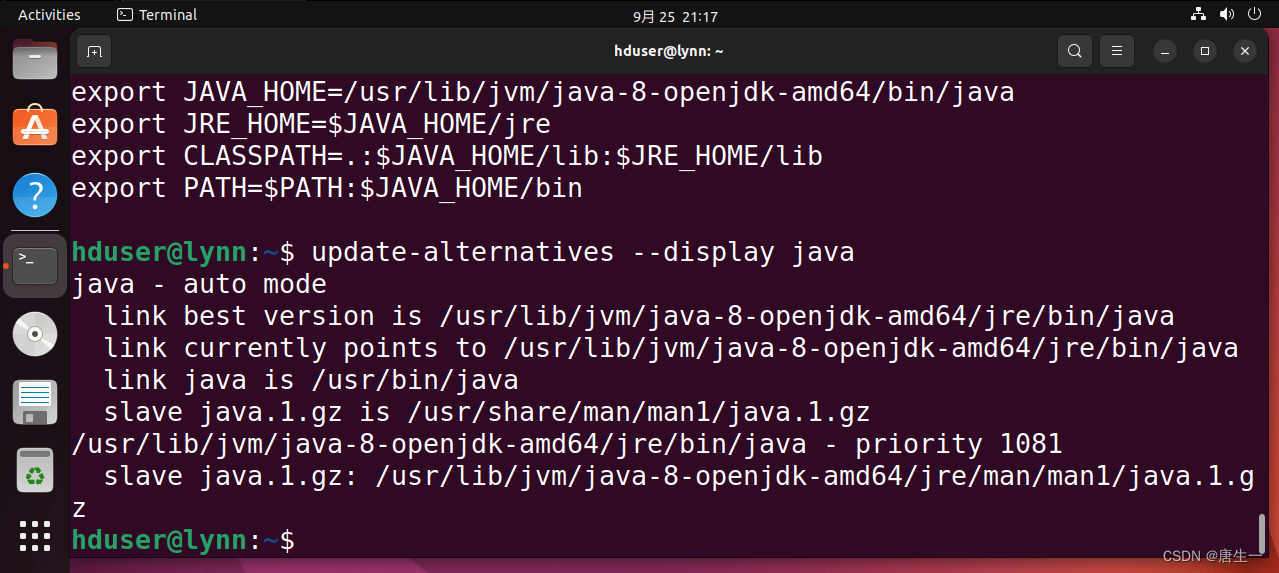
hduser@lynn:~$ sudo gedit .bashrc # 设置环境变量
# 在弹出的窗口最后增加如下语句:
# export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/bin/java # 设置Java的运行程序
# export JRE_HOME=$JAVA_HOME/jre
# export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
# export PATH=$PATH:$JAVA_HOME/bin
hduser@lynn:~$ source .bashrc # 使环境变量生效
3. 安装hadoop
从清华镜像源网站下载hadoop2.10.2版本
hduser@lynn:~$ sudo tar -zxvf hadoop-2.10.2.tar.gz
hduser@lynn:~$ sudo mv hadoop-2.10.2 /usr/local/hadoop
hduser@lynn:~$ sudo gedit ~/.bashrc # 设置hadoop环境变量,如果gedit打开失败,试试重启终端
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
hduser@lynn:~$ source ~/.bashrc # 使环境变量生效
3.0 配置SSH
# 安装ssh
hduser@lynn:~$ sudo apt-get install ssh
hduser@lynn:~$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# -t 指定要生成的密钥类型
# -P 表示密码,''表示不指定密码进行连接
# -f 是密钥生成之后保存的位置
hduser@lynn:~$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys # 拷贝公钥到要进行免密登录的机器上
hduser@lynn:~$ ssh localhost # 登录本机
hduser@lynn:~$ ll ~/.ssh # 查看相关文件
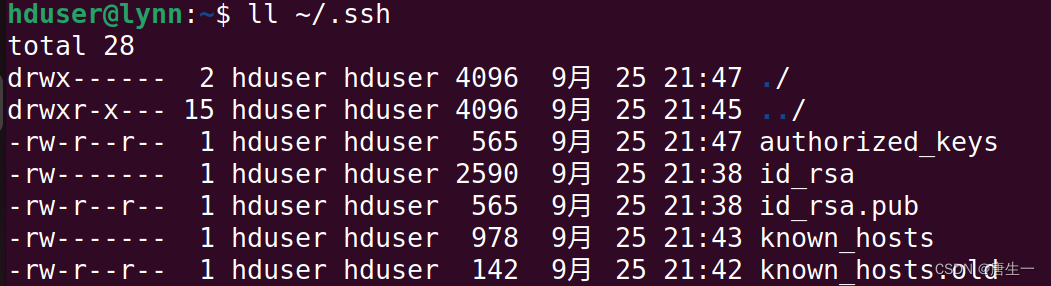
3.1 单机伪分布模式
在一台运行linux的单机上,用伪分布方式,用不同的进程模拟分布运行下的NameNode、DataNode、JobTracker、TaskTracker等各类节点。
3.1.1 配置hadoop-env
hduser@lynn:~$ sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
修改JAVA_HOME:
原来是:export JAVA_HOME=${JAVA_HOME}
修改为:export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd65
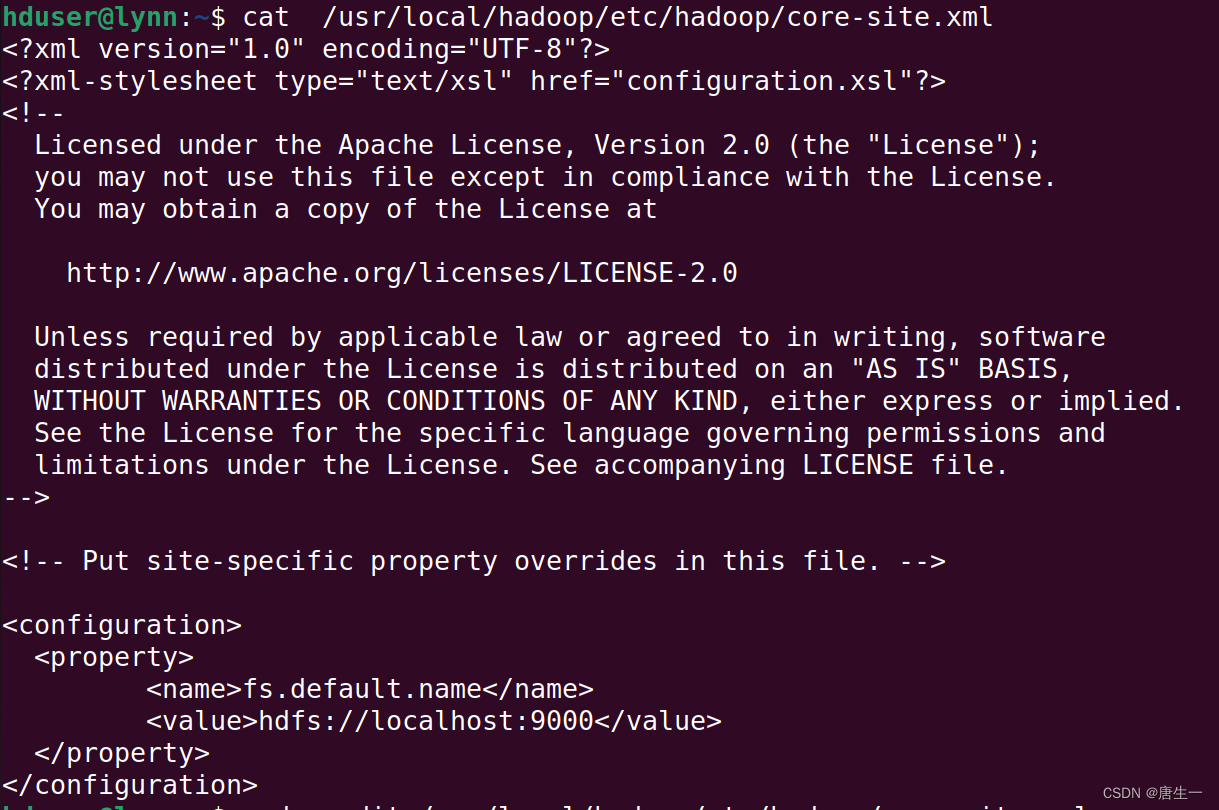
3.1.2 配置core-site.xml
设置HDFS的默认名称
hduser@lynn:~$ sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
3.1.3 设置yarn-site.xml
hduser@lynn:~$ sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
3.1.4 编辑mapred-site.xml
hduser@lynn:~$ sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
hduser@lynn:~$ sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.1.5 设置hdfs-site.xml
hdfs-site.xml 用于设置HDFS分布式文件系统的相关配置。Single Node Cluster中只有一台服务器,所以需要身兼NameNode和DataNode.
hduser@lynn:~$ sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<!--设置备份数量为3-->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
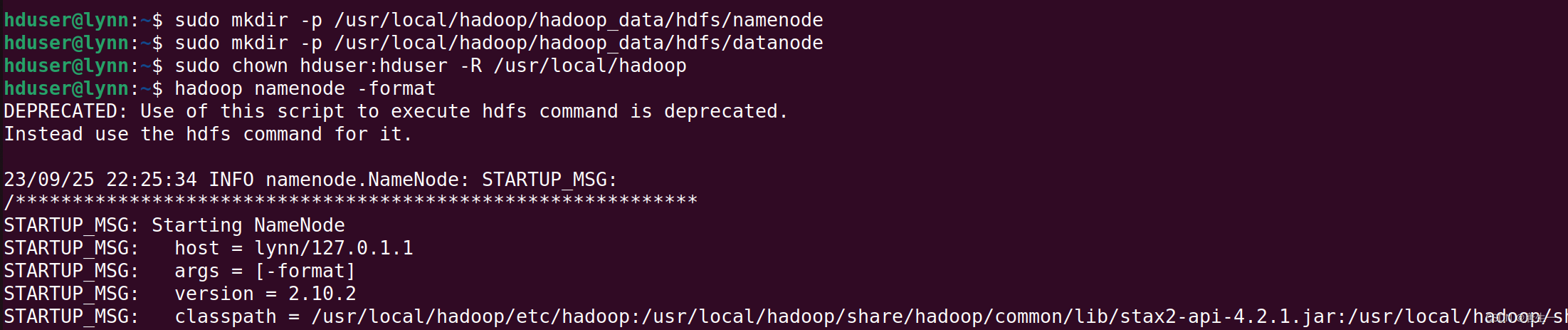
3.1.6 创建hdfs目录并格式化HDFS文件系统
# 创建NameNode数据存储目录
hduser@lynn:~$ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
# 创建DataNode数据存储目录
hduser@lynn:~$ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
# 将hadoop目录的所有者更改为hduser
hduser@lynn:~$ sudo chown hduser:hduser -R /usr/local/hadoop
# 格式化namenode-将HDFS格式化
hduser@lynn:~$ hadoop namenode -format
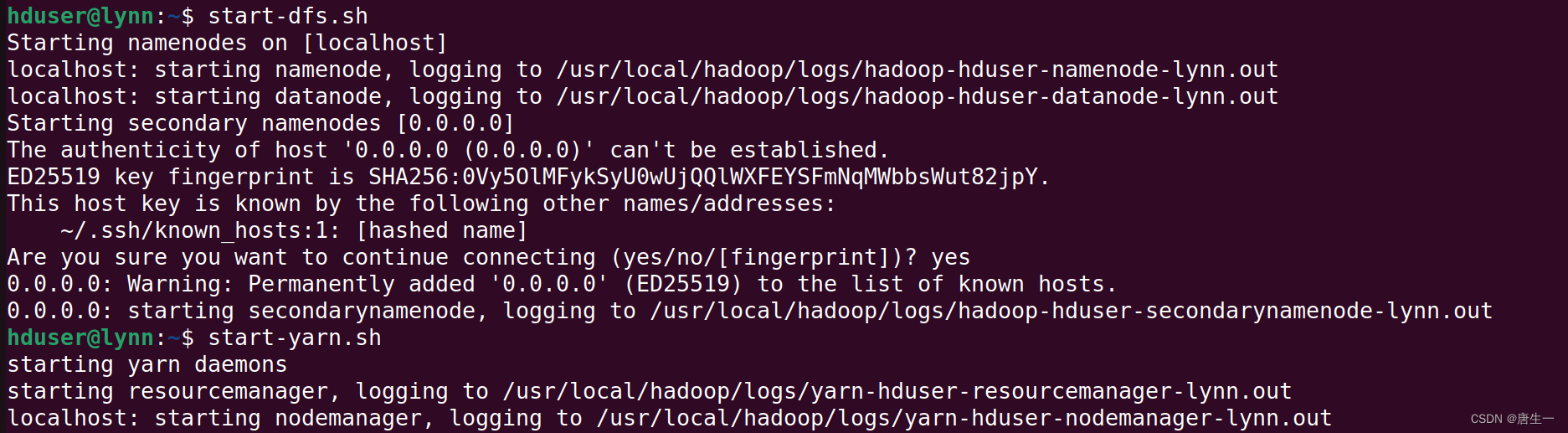
3.1.7 启动HDFS
# 启动hdfs
hduser@lynn:~$ start-dfs.sh
# 启动YARN
hduser@lynn:~$ start-yarn.sh
# jps可以列出运行的所有java虚拟机进程
hduser@lynn:~$ jps

3.1.8 查看集群状态
http://localhost:8088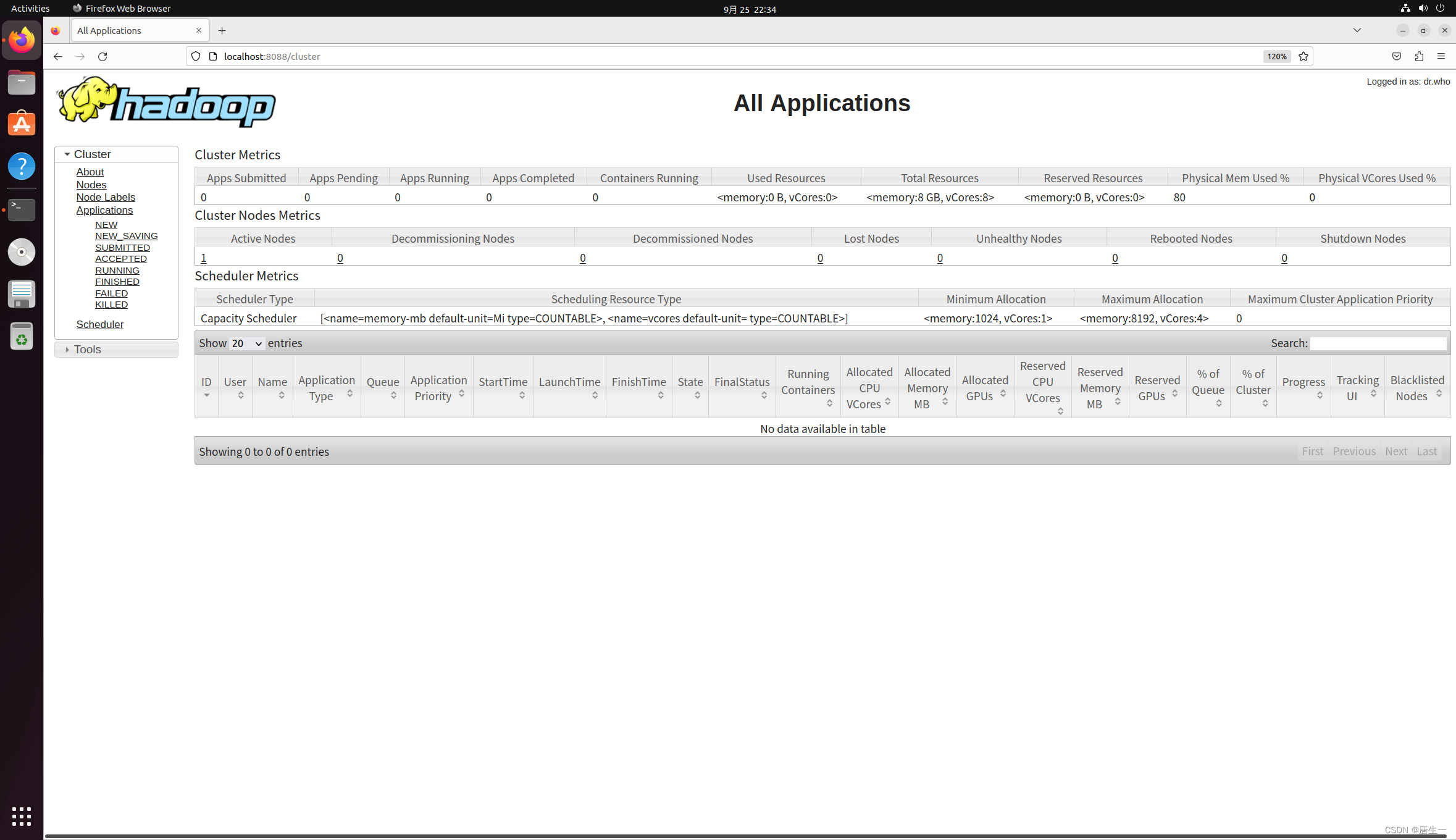 http://localhost:50070
http://localhost:50070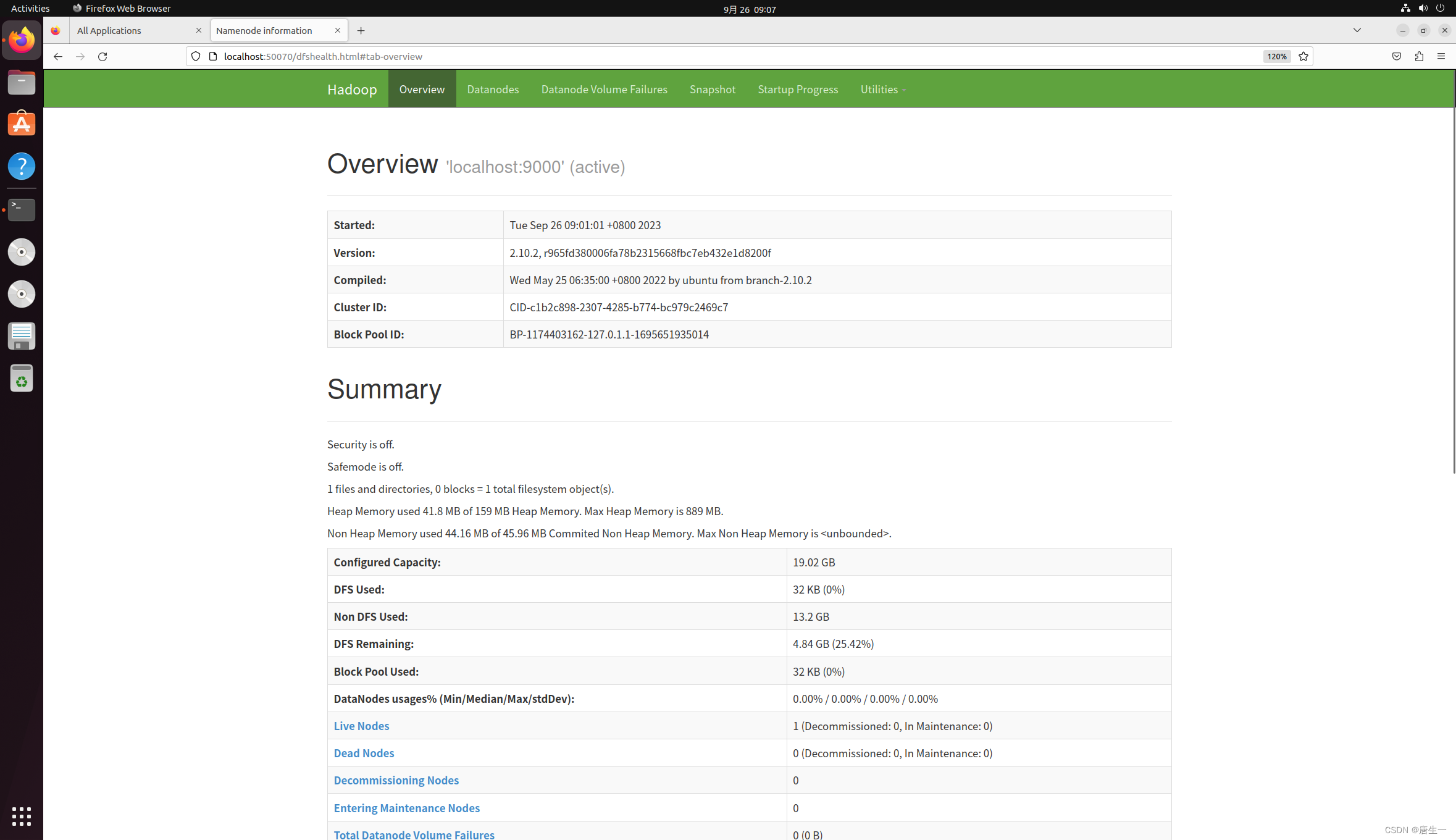
3.2 集群分布方式
在真实的集群环境下安装运行hadoop系统,集群的每个节点可以运行linux.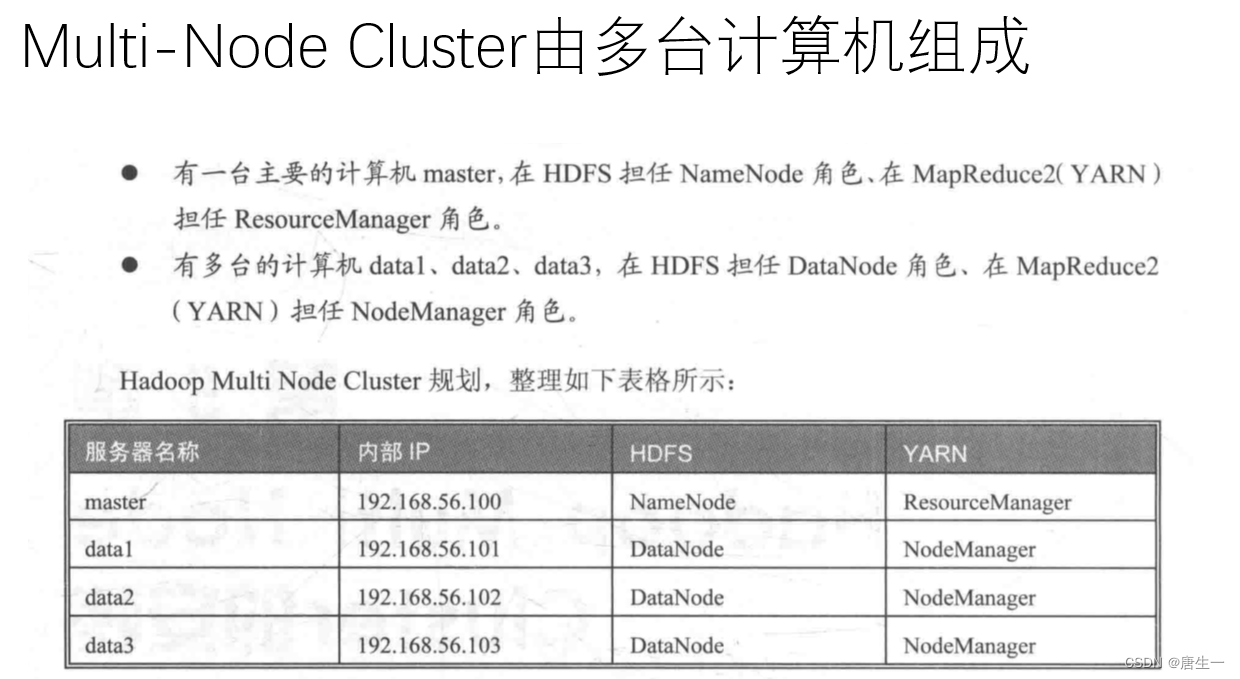
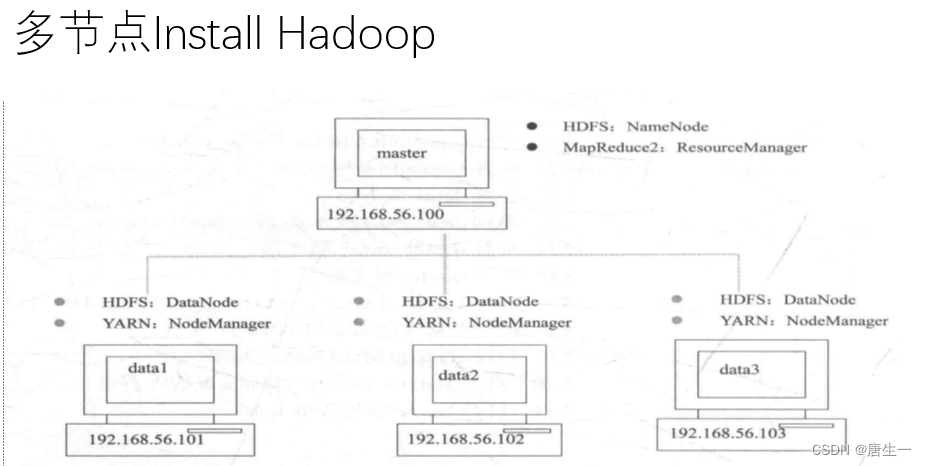
将在VMware上创建4台虚拟机,分别是master,data1,data2,data3
将在每一台虚拟机设置两张网卡:
- 网卡1:设置为NAT网卡,可以通过host主机连接到外部网络internet
- 网卡2:设置为“仅主机模式”,用于创建内部网络,内部网络连接4台虚拟主机与Host主机
- IP地址:master 192.168.56.100
data1 192.168.56.101
data2 192.168.56.102
data3 192.168.56.103
3.2.1 创建data1节点
从刚才创建的Single node clutch节点克隆出data1节点。选择创建完整克隆,命名为data1.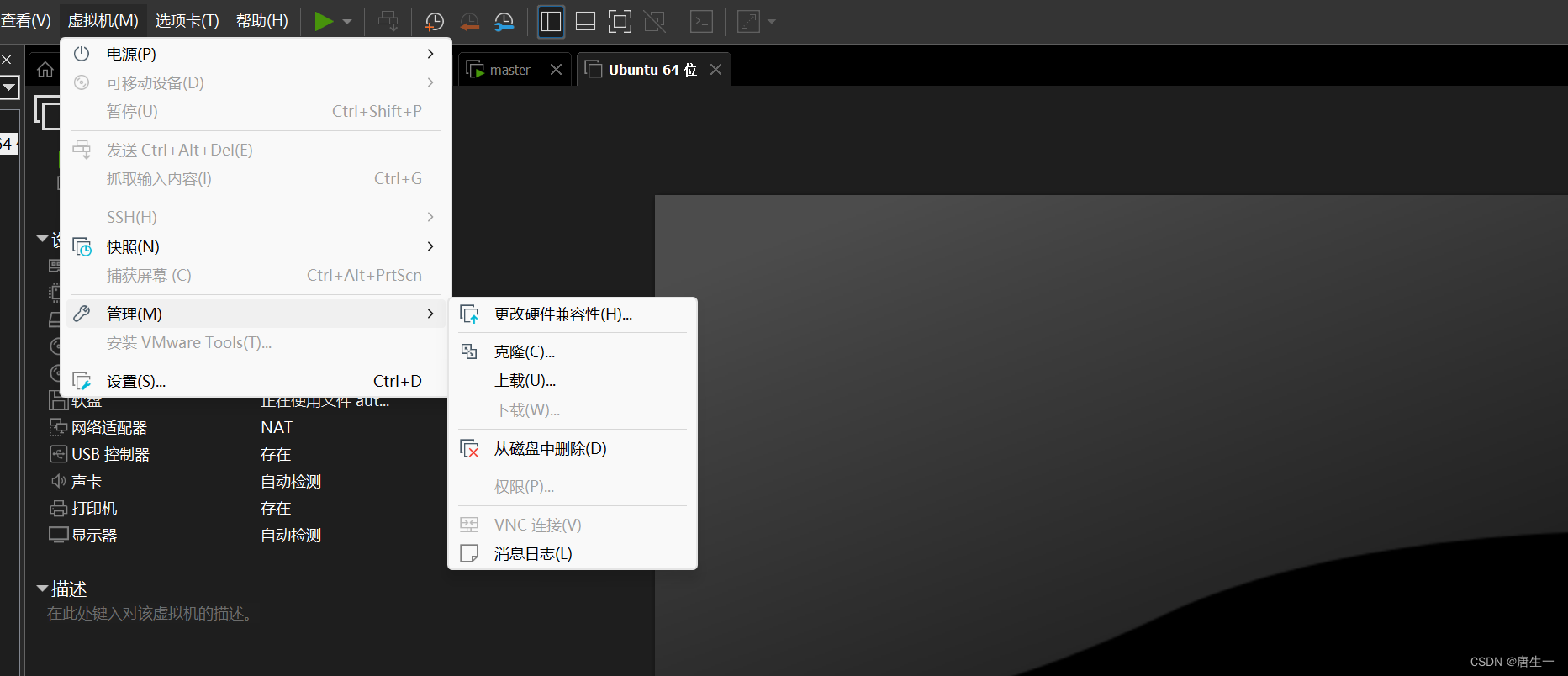
添加网卡
3.2.1.1 设置固定IP
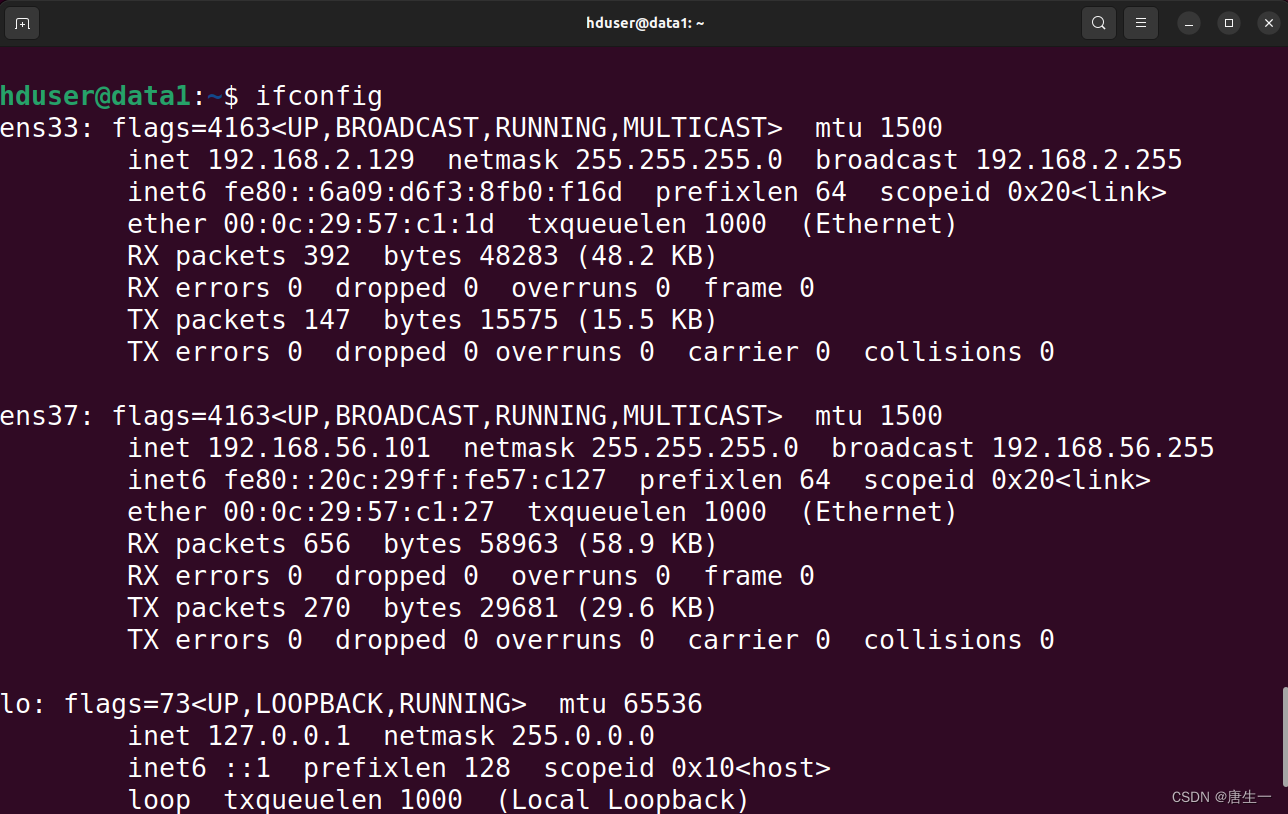
# 查看data1中的网卡
hduser@lynn:/$ ifconfig
# 显示分别是ens33,ens37
# ens33是ubuntu默认的NAT的网卡
# 对应我们集群使用的网卡为ens37
# 配置静态IP
hduser@lynn:/$ sudo gedit /etc/netplan/01-network-manager-all.yaml
network:
ethernets:
ens37:
addresses: [192.168.56.101/24] # 注意冒号后面需要有空格
dhcp4: no
optional: true
gateway4: 192.168.56.1
nameservers:
addresses: [192.168.56.1,114.114.114.114] # 114.114.114.114是电信的
version: 2
renderer: NetworkManager
hduser@lynn:/$ sudo netplan apply
hduser@lynn:/$ ifconfig
3.2.1.2 编辑主机名和hosts文件
# 编辑hostname主机名 设置data1
hduser@lynn:/$ sudo gedit /etc/hostname
data1
# 编辑hosts文件
hduser@lynn:/$ sudo gedit /etc/hosts
192.168.56.100 master
192.168.56.101 data1
192.168.56.102 data2
192.168.56.103 data3
3.2.1.3 编辑core-site.xml,yarn-site.xml,mapred-site.xml,hdfs-site.xml
hduser@lynn:/$ sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
hduser@lynn:/$ sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!--设置ResouceManager主机与NodeManager的连接地址,NodeManager通过这个地址向ResourceManager汇报运行情况-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<!--设置ResourceManager与ApplicationMaster的连接地址,ApplicationMaster通过这个地址向ResourceManager申请资源、释放资源等-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<!--设置ResourceManager与客户端的连接地址,客户端通过该地址ResourceManger注册应用程序、删除程序等-->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8050</value>
</property>
</configuration>
hduser@lynn:/$ sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
# mapred-site.xml用于设置监控Map与Reduce程序的JobTracker任务分配情况,以及TaskTracker任务运行状况
# 修改设置mapreduce.job.tracker的连接地址为master:54311
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:54311</value>
</property>
</configuration>
hduser@lynn:/$ sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
3.2.2 创建data2,data3,master节点
克隆data1到data2,data3,master
3.2.2.1 分别设置每个主机的固定IP
hduser@data1:/$ sudo gedit /etc/netplan/01-network-manager-all.yaml
ens37:
# 只需要更改此处的IP地址,data2为192.168.56.102
# data3为192.168.56.103
# master为192.168.56.100
addresses: [192.168.56.102/24]
dhcp4: no
optional: true
# 使设置生效
hduser@data1:/$ sudo netplan apply
# 查看网卡信息,确认ip地址无误
hduser@data1:/$ ifconfig
3.2.2.2 设置每个主机的主机名
# data2设置为data2;data3设置为data3,master设置为master
hduser@data1:/$ sudo gedit /etc/hostname
3.2.3 设置master服务器
3.2.3.1 设置hdfs-site.xml
因为master现在只是单纯的NameNode,删除DataNode的HDFS设置
hduser@master:~$ sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
</configuration>
3.2.3.2 编辑masters文件和slaves文件
masters文件主要是告诉hadoop系统哪一台服务器是NameNode.
slaves文件主要是告诉hadoop系统哪些服务器是DataNode.
hduser@master:~$ sudo gedit /usr/local/hadoop/etc/hadoop/masters
master
hduser@master:~$ sudo gedit /usr/local/hadoop/etc/hadoop/slaves
data1
data2
data3
3.2.4 测试
- 启动master,data1,data2,data3四个节点
- 从master主机连接到data1
hduser@master:~$ ssh data1
- 创建HDFS目录datanode,对data2及data3重复此操作.
hduser@data1:~$ sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs/
[sudo] password for hduser:
hduser@data1:~$ mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
hduser@data1:~$ sudo chown -R hduser:hduser /usr/local/hadoop
hduser@data1:~$ exit
logout
Connection to data1 closed.
- 重新创建并格式化NameNode HDFS目录
# 创建NameNode目录
hduser@master:~$ sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
[sudo] password for hduser:
hduser@master:~$ mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
hduser@master:~$ sudo chown -R hduser:hduser /usr/local/hadoop
# 格式化
hduser@master:~$ hdfs namenode -format
- 启动hadoop multinode cluster
hduser@master:~$ start-dfs.sh
hduser@master:~$ start-yarn.sh
hduser@master:~$ jps
- 可以看见master服务器的状态:
HDFS功能:Namenode,SecondaryNameNode
MapReduce2(YARN): ResourceManager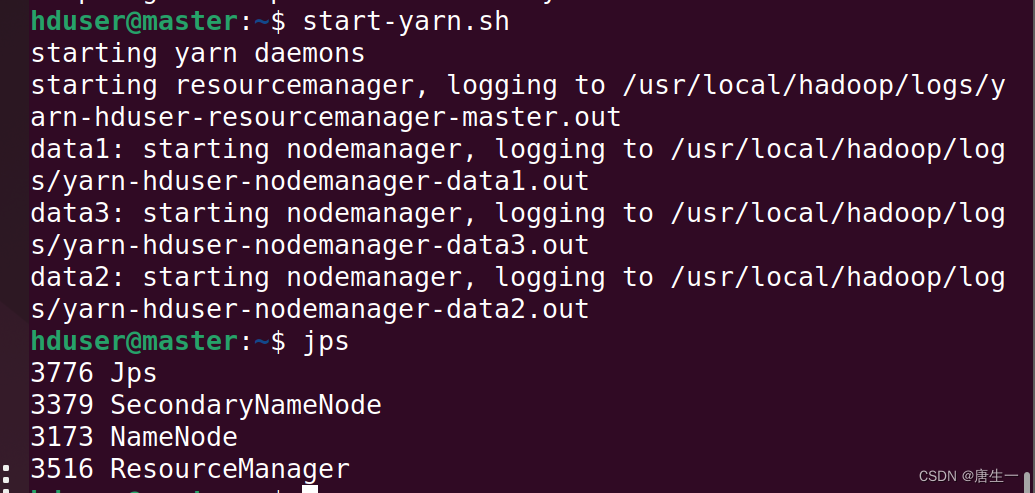
- 查看数据服务器节点data1(DataNode)进程的状态
在data1的终端上输入jps
HDFS:DataNode
MapReduce2(YARN
: NodeManager
- 打开Hadoop ResouceManager Web界面 http://master:8088
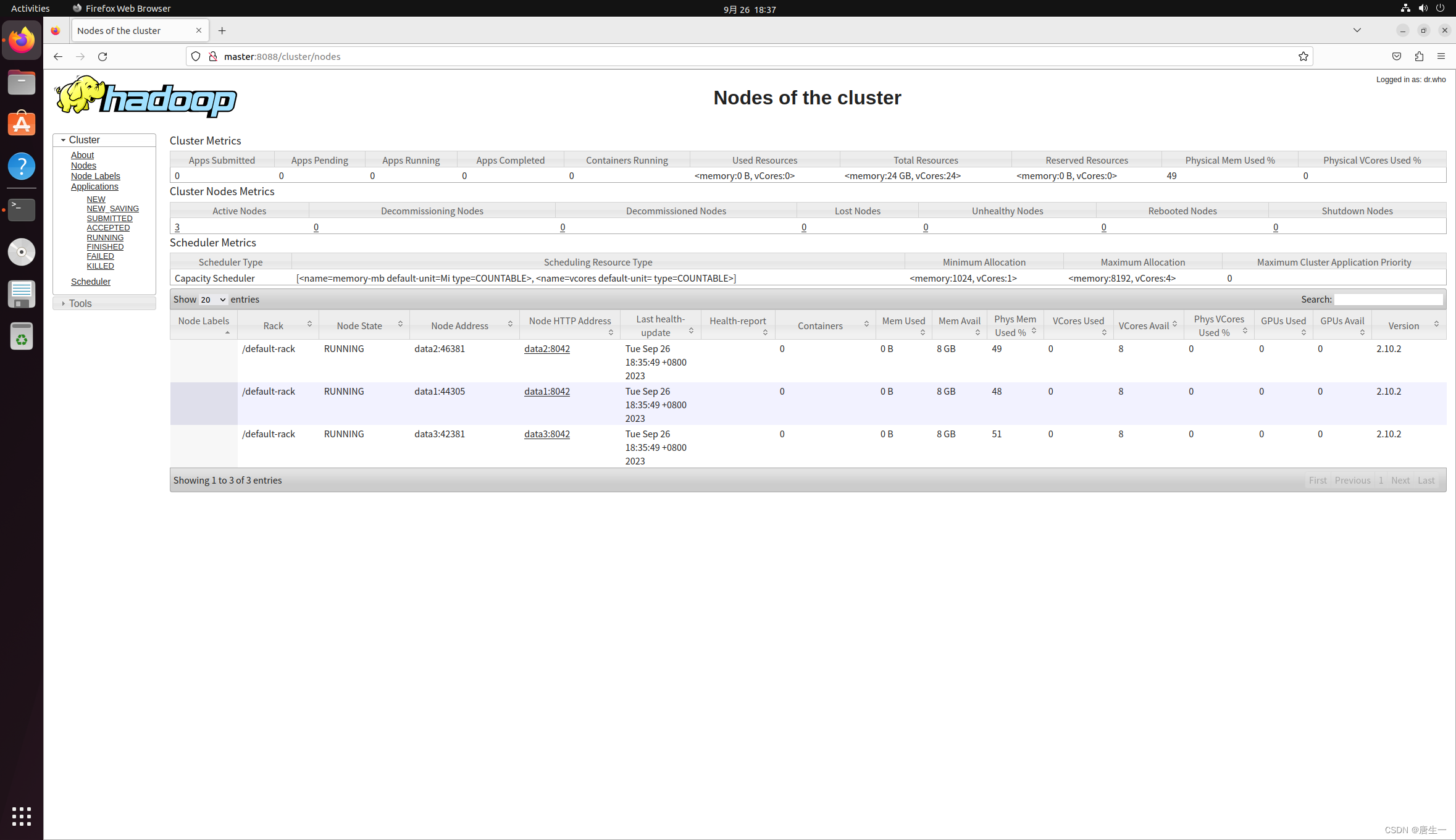
- 打开NameNode Web界面 http://master:50070/
- 程序开发学习排行
- 最近发表