

Hudi第二章:集成Spark(二)
作者:小教学发布时间:2023-10-03分类:程序开发学习浏览:273
系列文章目录
Hudi第一章:编译安装
Hudi第二章:集成Spark
Hudi第二章:集成Spark(二)
文章目录
- 系列文章目录
- 前言
- 一、IDEA
- 1.环境准备
- 2.代码编写
- 1.插入数据
- 2.查询数据
- 3.更新数据
- 4.指定时间点查询
- 5.增量查询
- 6.删除数据
- 7.覆盖数据
- 二、DeltaStreamer
- 1.安装Kafka
- 2.准备数据源
- 3.编写配置文件
- 4.运行代码
- 三、并发控制
- 1.Spark DataFrame写入
- 2.elta Streamer
- 总结
前言
这次我们将hudi集成Spark补充完整。
一、IDEA
之前我们使用了spark-shell和spark-sql进行操作,现在我们使用IDEA进行数据处理。
1.环境准备
创建项目啥的不说了
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu.hudi</groupId>
<artifactId>spark-hudi-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.12.10</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>3.2.2</spark.version>
<hadoop.version>3.1.3</hadoop.version>
<hudi.version>0.12.0</hudi.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!-- 依赖Scala语言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<!-- Spark SQL 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<!-- Hadoop Client 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
<!-- hudi-spark3.2 -->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark3.2-bundle_${scala.binary.version}</artifactId>
<version>${hudi.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- assembly打包插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
<configuration>
<archive>
<manifest>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
<!--Maven编译scala所需依赖-->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
2.代码编写
因为idea编写方法和spark-shell几乎一样,所以就做一个最简单的例子。
1.插入数据
package com.atguigu.hudi.spark
import org.apache.hudi.QuickstartUtils._
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
object InsertDemo {
def main( args: Array[String] ): Unit = {
// 创建 SparkSession
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkSession = SparkSession.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
val tableName = "hudi_trips_cow"
val basePath = "hdfs://hadoop1:8020/tmp/hudi_trips_cow"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = sparkSession.read.json(sparkSession.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD.key(), "ts").
option(RECORDKEY_FIELD.key(), "uuid").
option(PARTITIONPATH_FIELD.key(), "partitionpath").
option(TBL_NAME.key(), tableName).
mode(Overwrite).
save(basePath)
}
}
如果出现这个错误,需要对idea做一些设置。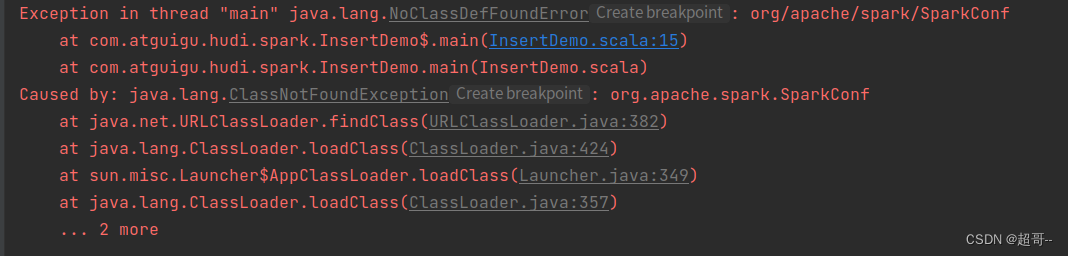
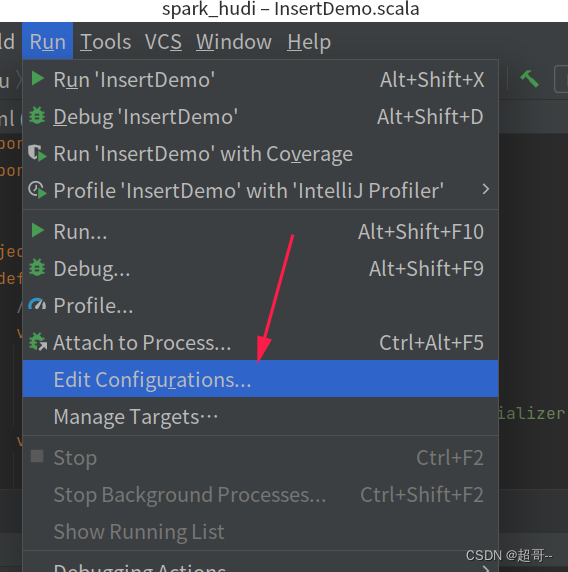
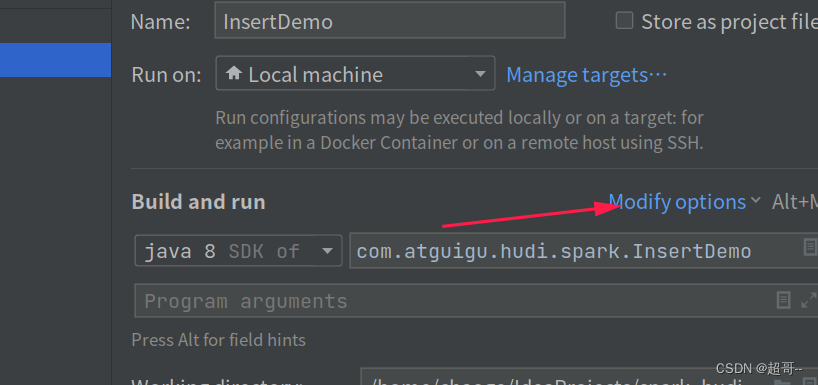
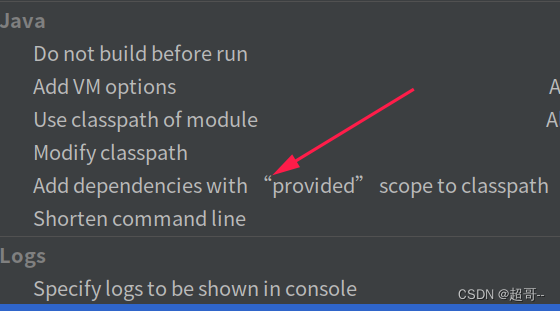
我得版本比较新,其它版本可能不太一样。
如果出现这个问题,是因为我们在idea链接集群用的是本地的用户名,我们需要更改一下
加一行代码
System.setProperty("HADOOP_USER_NAME", "atguigu")
执行成功后,我们在hdfs路径查看一下有没有新表。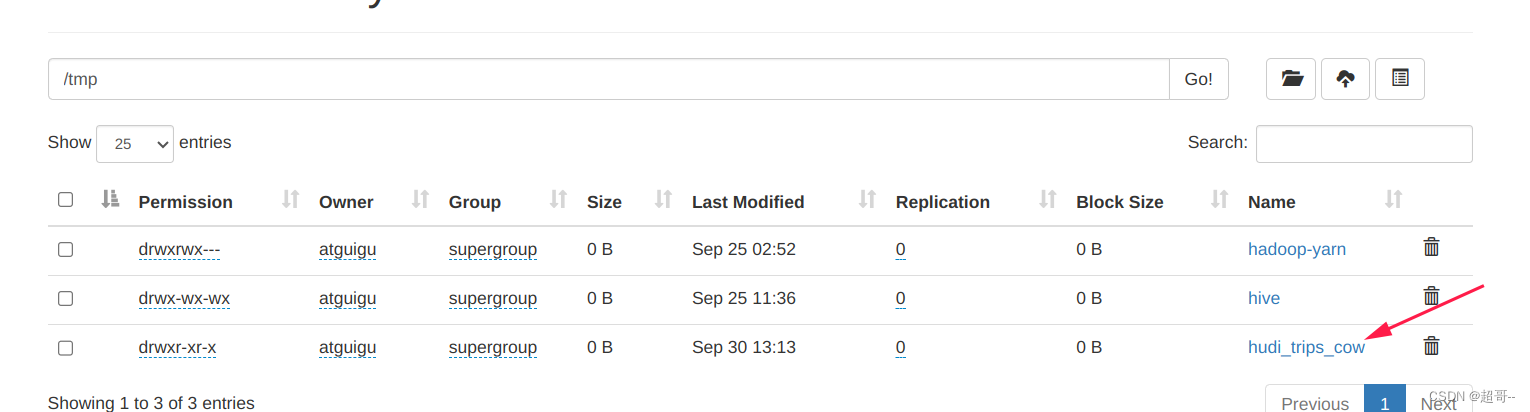
其它的都类似,所以只放代码,不运行了。
2.查询数据
package com.atguigu.hudi.spark
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object QueryDemo {
def main( args: Array[String] ): Unit = {
// 创建 SparkSession
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkSession = SparkSession.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
val basePath = "hdfs://hadoop1:8020/tmp/hudi_trips_cow"
val tripsSnapshotDF = sparkSession.
read.
format("hudi").
load(basePath)
// 时间旅行查询写法一
// sparkSession.read.
// format("hudi").
// option("as.of.instant", "20210728141108100").
// load(basePath)
//
// 时间旅行查询写法二
// sparkSession.read.
// format("hudi").
// option("as.of.instant", "2021-07-28 14:11:08.200").
// load(basePath)
//
// 时间旅行查询写法三:等价于"as.of.instant = 2021-07-28 00:00:00"
// sparkSession.read.
// format("hudi").
// option("as.of.instant", "2021-07-28").
// load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
sparkSession
.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0")
.show()
}
}
3.更新数据
package com.atguigu.hudi.spark
import org.apache.hudi.QuickstartUtils._
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
object UpdateDemo {
def main( args: Array[String] ): Unit = {
// 创建 SparkSession
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkSession = SparkSession.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
val tableName = "hudi_trips_cow"
val basePath = "hdfs://hadoop1:8020/tmp/hudi_trips_cow"
val dataGen = new DataGenerator
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = sparkSession.read.json(sparkSession.sparkContext.parallelize(updates, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD.key(), "ts").
option(RECORDKEY_FIELD.key(), "uuid").
option(PARTITIONPATH_FIELD.key(), "partitionpath").
option(TBL_NAME.key(), tableName).
mode(Append).
save(basePath)
// val tripsSnapshotDF = sparkSession.
// read.
// format("hudi").
// load(basePath)
// tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
//
// sparkSession
// .sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0")
// .show()
}
}
4.指定时间点查询
package com.atguigu.hudi.spark
import org.apache.hudi.DataSourceReadOptions._
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object PointInTimeQueryDemo {
def main( args: Array[String] ): Unit = {
// 创建 SparkSession
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkSession = SparkSession.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
val basePath = "hdfs://hadoop1:8020/tmp/hudi_trips_cow"
import sparkSession.implicits._
val commits = sparkSession.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
val beginTime = "000"
val endTime = commits(commits.length - 2)
val tripsIncrementalDF = sparkSession.read.format("hudi").
option(QUERY_TYPE.key(), QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME.key(), beginTime).
option(END_INSTANTTIME.key(), endTime).
load(basePath)
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_point_in_time")
sparkSession.
sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where fare > 20.0").
show()
}
}
5.增量查询
package com.atguigu.hudi.spark
import org.apache.hudi.DataSourceReadOptions._
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object IncrementalQueryDemo {
def main( args: Array[String] ): Unit = {
// 创建 SparkSession
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkSession = SparkSession.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
val basePath = "hdfs://hadoop1:8020/tmp/hudi_trips_cow"
import sparkSession.implicits._
val commits = sparkSession.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
val beginTime = commits(commits.length - 2)
val tripsIncrementalDF = sparkSession.read.format("hudi").
option(QUERY_TYPE.key(), QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME.key(), beginTime).
load(basePath)
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
sparkSession.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare > 20.0").show()
}
}
6.删除数据
package com.atguigu.hudi.spark
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.QuickstartUtils._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.spark.SparkConf
import org.apache.spark.sql.SaveMode._
import org.apache.spark.sql._
import scala.collection.JavaConversions._
object DeleteDemo {
def main( args: Array[String] ): Unit = {
// 创建 SparkSession
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkSession = SparkSession.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
val tableName = "hudi_trips_cow"
val basePath = "hdfs://hadoop1:8020/tmp/hudi_trips_cow"
val dataGen = new DataGenerator
sparkSession.
read.
format("hudi").
load(basePath).
createOrReplaceTempView("hudi_trips_snapshot")
sparkSession.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
val ds = sparkSession.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2)
val deletes = dataGen.generateDeletes(ds.collectAsList())
val df = sparkSession.read.json(sparkSession.sparkContext.parallelize(deletes, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION.key(),"delete").
option(PRECOMBINE_FIELD.key(), "ts").
option(RECORDKEY_FIELD.key(), "uuid").
option(PARTITIONPATH_FIELD.key(), "partitionpath").
option(TBL_NAME.key(), tableName).
mode(Append).
save(basePath)
val roAfterDeleteViewDF = sparkSession.
read.
format("hudi").
load(basePath)
roAfterDeleteViewDF.createOrReplaceTempView("hudi_trips_snapshot")
// 返回的总行数应该比原来少2行
sparkSession.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
}
}
7.覆盖数据
package com.atguigu.hudi.spark
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.QuickstartUtils._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.spark.SparkConf
import org.apache.spark.sql.SaveMode._
import org.apache.spark.sql._
import scala.collection.JavaConversions._
object InsertOverwriteDemo {
def main( args: Array[String] ): Unit = {
// 创建 SparkSession
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkSession = SparkSession.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
val tableName = "hudi_trips_cow"
val basePath = "hdfs://hadoop1:8020/tmp/hudi_trips_cow"
val dataGen = new DataGenerator
sparkSession.
read.format("hudi").
load(basePath).
select("uuid","partitionpath").
sort("partitionpath","uuid").
show(100, false)
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = sparkSession.read.json(sparkSession.sparkContext.parallelize(inserts, 2)).
filter("partitionpath = 'americas/united_states/san_francisco'")
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION.key(),"insert_overwrite").
option(PRECOMBINE_FIELD.key(), "ts").
option(RECORDKEY_FIELD.key(), "uuid").
option(PARTITIONPATH_FIELD.key(), "partitionpath").
option(TBL_NAME.key(), tableName).
mode(Append).
save(basePath)
sparkSession.
read.format("hudi").
load(basePath).
select("uuid","partitionpath").
sort("partitionpath","uuid").
show(100, false)
}
}
二、DeltaStreamer
这是一个hudi自带的导入工具,可以从一些数据源将数据快速导入hudi,这里我们用kafka做数据源。
1.安装Kafka
zk安装
kafka安装
2.准备数据源
我们可以新创建任务,也可以直接在之前的idea项目上编写。
pom.xml
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<!--fastjson <= 1.2.80 存在安全漏洞,-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
TestKafkaProducer.java
package com.atguigu.util;
import com.alibaba.fastjson.JSONObject;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.Random;
public class TestKafkaProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
props.put("acks", "-1");
props.put("batch.size", "1048576");
props.put("linger.ms", "5");
props.put("compression.type", "snappy");
props.put("buffer.memory", "33554432");
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
Random random = new Random();
for (int i = 0; i < 1000; i++) {
JSONObject model = new JSONObject();
model.put("userid", i);
model.put("username", "name" + i);
model.put("age", 18);
model.put("partition", random.nextInt(100));
producer.send(new ProducerRecord<String, String>("hudi_test", model.toJSONString()));
}
producer.flush();
producer.close();
}
}
启动zk和kafka
然后创建一个消费者,要与代码中对应。
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --topic hudi_test
然后先消费数据。
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic hudi_test
因为我们还没有生产数据,所以现在应该什么都没有。
运行idea里的代码。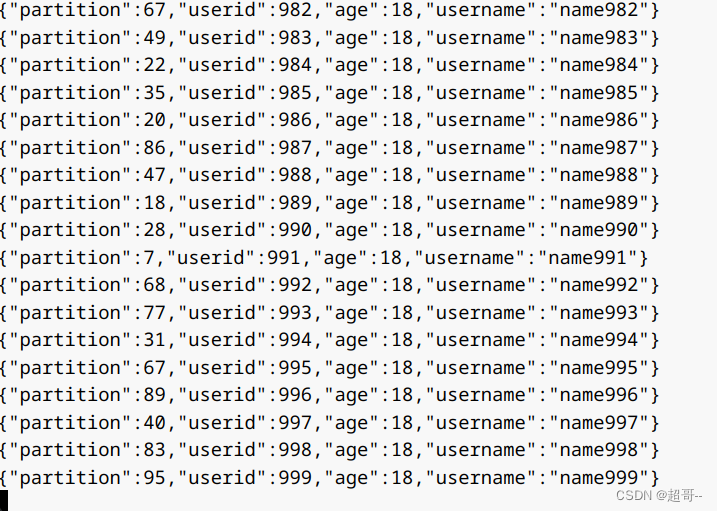
当Kafka消费到数据时,我们的数据源准备完成。
3.编写配置文件
我们为其创建一个单独的文件夹。
mkdir /opt/module/hudi-props
cp /opt/software/hudi-0.12.0/hudi-utilities/src/test/resources/delta-streamer-config/kafka-source.properties /opt/module/hudi-props/
cp /opt/software/hudi-0.12.0/hudi-utilities/src/test/resources/delta-streamer-config/base.properties /opt/module/hudi-props/
touch /opt/module/hudi-props/source-schema-json.avsc
编写source-schema-json.avsc
{
"type": "record",
"name": "Profiles",
"fields": [
{
"name": "userid",
"type": [ "null", "string" ],
"default": null
},
{
"name": "username",
"type": [ "null", "string" ],
"default": null
},
{
"name": "age",
"type": [ "null", "string" ],
"default": null
},
{
"name": "partition",
"type": [ "null", "string" ],
"default": null
}
]
}
然后复制一份
cp source-schema-json.avsc target-schema-json.avsc
编写kafka-source.properties
include=hdfs://hadoop102:8020/hudi-props/base.properties
# Key fields, for kafka example
hoodie.datasource.write.recordkey.field=userid
hoodie.datasource.write.partitionpath.field=partition
# schema provider configs
#hoodie.deltastreamer.schemaprovider.registry.url=http://localhost:8081/subjects/impressions-value/versions/latest
hoodie.deltastreamer.schemaprovider.source.schema.file=hdfs://hadoop102:8020/hudi-props/source-schema-json.avsc
hoodie.deltastreamer.schemaprovider.target.schema.file=hdfs://hadoop102:8020/hudi-props/target-schema-json.avsc
# Kafka Source
#hoodie.deltastreamer.source.kafka.topic=uber_trips
hoodie.deltastreamer.source.kafka.topic=hudi_test
#Kafka props
bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
auto.offset.reset=earliest
schema.registry.url=http://localhost:8081
group.id=test-group
我把要修改的地方都画出来。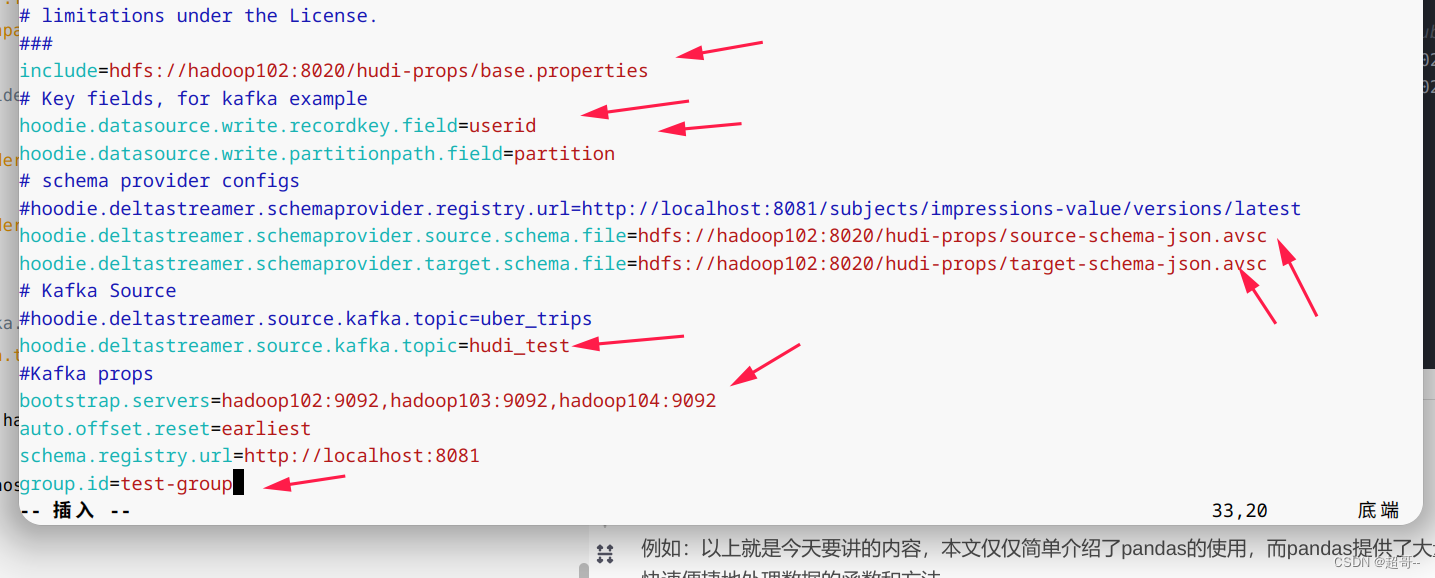
然后将其上传到hdfs
hadoop fs -put /opt/module/hudi-props/ /
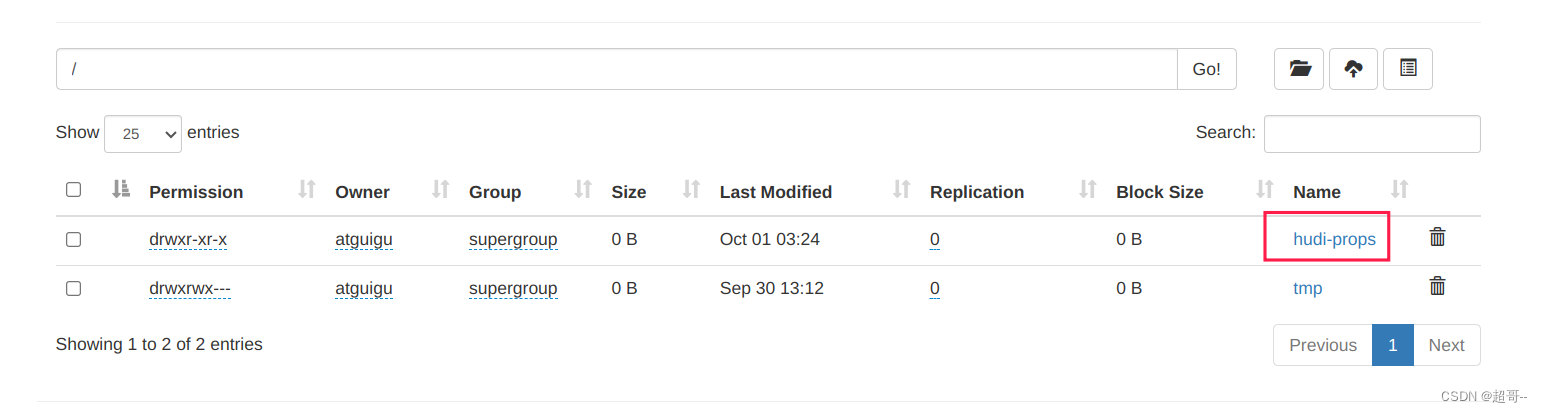
将需要的jar包拷入spark
cp /opt/software/hudi-0.12.0/packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.12-0.12.0.jar /opt/module/spark-3.2.2/jars/
4.运行代码
spark-submit \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
/opt/module/spark-3.2.2/jars/hudi-utilities-bundle_2.12-0.12.0.jar \
--props hdfs://hadoop102:8020/hudi-props/kafka-source.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \
--source-class org.apache.hudi.utilities.sources.JsonKafkaSource \
--source-ordering-field userid \
--target-base-path hdfs://hadoop102:8020/tmp/hudi/hudi_test \
--target-table hudi_test \
--op BULK_INSERT \
--table-type MERGE_ON_READ
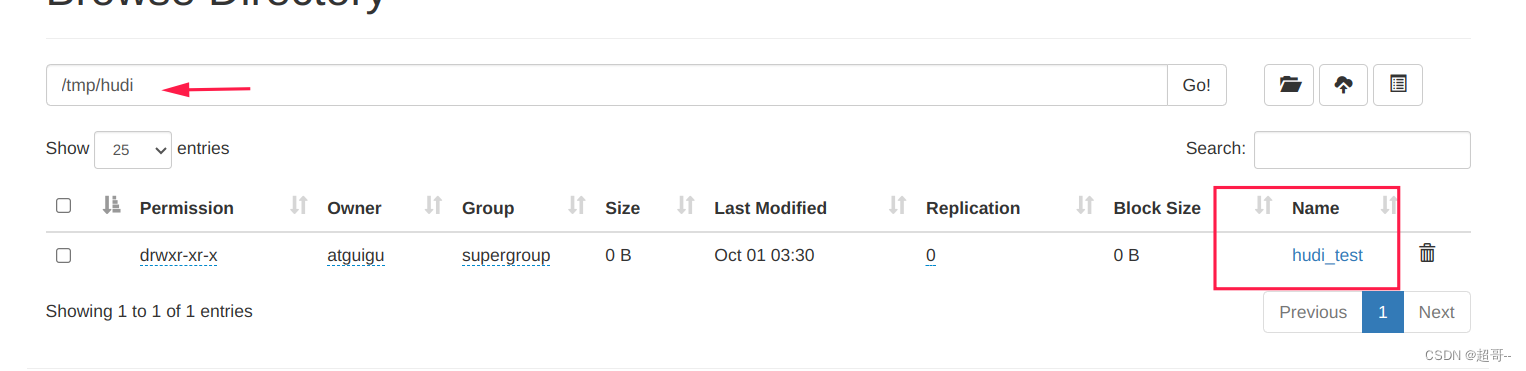
可以看到hdfs上已经出现了表信息。
现在我们用spark-sql验证一下内容。
spark-sql \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
use spark_hudi;
create table hudi_test using hudi
location 'hdfs://hadoop102:8020/tmp/hudi/hudi_test';
select * from hudi_test;
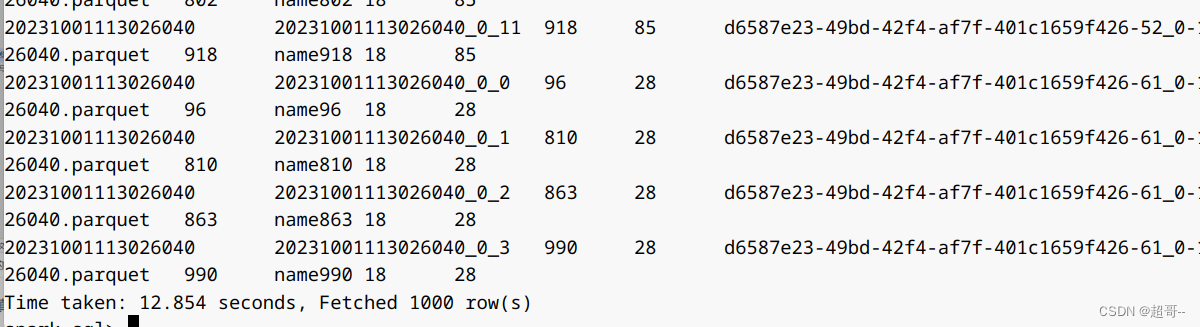
三、并发控制
之前我们都是用单个用户来写入,这很明显不符合生产环境,所以下边说一下并发写入。
当并发写入的时候,我们就需要使用到锁,这里我们选择zk来进行辅助。
1.Spark DataFrame写入
先登录spark-shell
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
创建并发表
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option("hoodie.write.concurrency.mode", "optimistic_concurrency_control").
option("hoodie.cleaner.policy.failed.writes", "LAZY").
option("hoodie.write.lock.provider", "org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider").
option("hoodie.write.lock.zookeeper.url", "hadoop102,hadoop103,hadoop104").
option("hoodie.write.lock.zookeeper.port", "2181").
option("hoodie.write.lock.zookeeper.lock_key", "test_table").
option("hoodie.write.lock.zookeeper.base_path", "/multiwriter_test").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
在这里我把和之前不同的地方单独隔离了出来。
因为我们这里会用到zk,所以提前先打开一个zk窗口
bin/zkCli.sh

当数据导入时,zk生成一个新节点作为锁,结束后,自动释放,所以要快一点。
开始导入数据,并在zk查看。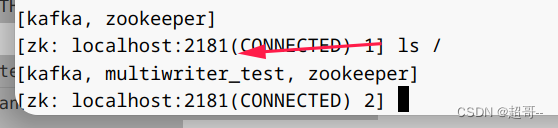

结束后,锁会被释放。
2.elta Streamer
elta Streamer使用kafka作为数据源,所以要先把kafka打开。
创建kafka-multiwriter-source.propertis文件,直接kafka-source.properties上复制一份然后修改。
cp kafka-source.properties kafka-multiwriter-source.propertis
修改内容,在后边追加即可。
hoodie.write.concurrency.mode=optimistic_concurrency_control
hoodie.cleaner.policy.failed.writes=LAZY
hoodie.write.lock.provider=org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider
hoodie.write.lock.zookeeper.url=hadoop102,hadoop103,hadoop104
hoodie.write.lock.zookeeper.port=2181
hoodie.write.lock.zookeeper.lock_key=test_table2
hoodie.write.lock.zookeeper.base_path=/multiwriter_test2
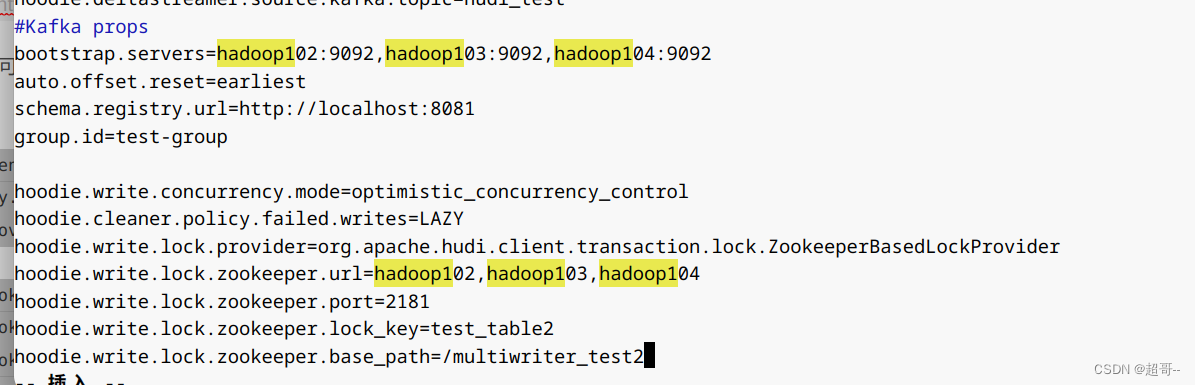
然后上传到hdfs
hadoop fs -put /opt/module/hudi-props/kafka-multiwriter-source.propertis /hudi-props
然后提前打开zk,之后进行数据插入。
spark-submit \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
/opt/module/spark-3.2.2/jars/hudi-utilities-bundle_2.12-0.12.0.jar \
--props hdfs://hadoop102:8020/hudi-props/kafka-multiwriter-source.propertis \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \
--source-class org.apache.hudi.utilities.sources.JsonKafkaSource \
--source-ordering-field userid \
--target-base-path hdfs://hadoop102:8020/tmp/hudi/hudi_test_multi \
--target-table hudi_test_multi \
--op INSERT \
--table-type MERGE_ON_READ


总结
课程后边其实还有一些调优的内容,想了想还是没有写下了,用的时候再说吧。
- 程序开发学习排行
- 最近发表