

Learning Invariant Representation for Unsupervised Image Restoration
作者:小教学发布时间:2023-10-02分类:程序开发学习浏览:287
Learning Invariant Representation for Unsupervised Image Restoration (Paper reading)
Wenchao Du, Sichuan University, CVPR20, Cited:63, Code, Paper
1. 前言
近年来,跨域传输被应用于无监督图像恢复任务中。但是,直接应用已有的框架,由于缺乏有效的监督,会导致翻译图像出现域漂移问题。相反,我们提出了一种无监督学习方法,该方法明确地从噪声数据中学习不变表示并重建清晰的观察结果。为此,我们将离散解纠缠表示和对抗性领域自适应引入到一般的领域转移框架中,并借助额外的自监督模块(包括背景和语义一致性约束),在双域约束(如特征域和图像域)下学习鲁棒表示。对合成和真实降噪任务的实验表明,该方法的降噪性能可与现有的有监督降噪和无监督降噪方法相媲美,且收敛速度比其他领域自适应方法更快、更稳定。
2. 整体思想
本文提出了一种无监督low-level的方法。主要的思想是将清晰图像和降质图像分别编码到各自的域中,然后从这些域中重建他们。类似于自编码器的思想。
3. 方法
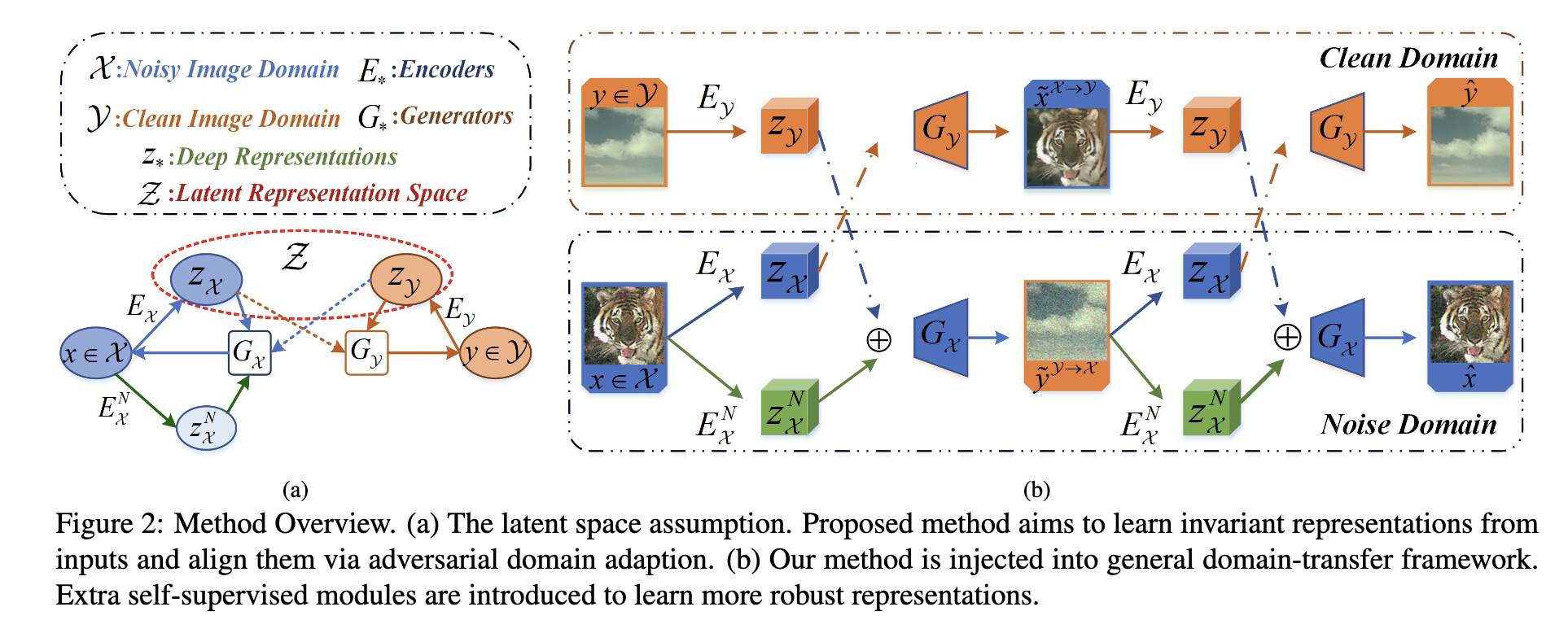
我们的目标是从噪声输入中学习抽象的中间表示,并重建清晰的观察结果。在某种程度上,无监督图像复原可以看作是一个特定的域转移问题,即从噪声域到清晰域。因此,将该方法注入到一般的领域转移架构中,如图2所示。
在监督域转移中,我们得到从联合分布
P
X
,
Y
(
x
,
y
)
P_{X, Y} (x, y)
PX,Y(x,y)中抽取的样本
(
x
,
y
)
(x, y)
(x,y),其中
X
X
X和
y
y
y是两个图像域。对于无监督域翻译,从边缘分布PX (x)和PY (y)中提取样本(x, y)。为了从边缘样本推断联合分布,我们提出了一个共享潜空间假设,即在共享潜空间
Z
Z
Z中存在一个共享潜代码
z
z
z,从而我们可以从这个代码中恢复两幅图像。给定来自联合分布的样本
(
x
,
y
)
(x, y)
(x,y),该过程表示为
z
=
E
X
(
x
)
=
E
Y
(
y
)
,
x
=
G
X
(
z
)
,
y
=
G
Y
(
z
)
z = E_X(x)=E_Y(y), \quad x = G_X(z),y=G_Y(z)
z=EX(x)=EY(y),x=GX(z),y=GY(z)
关键的一步是如何实现这个共享潜在空间假设。为此,一种有效的策略是通过共享权重编码器共享高级表示,该编码器从统一分布中采样特征。然而,对于IR图像来说,潜在表示只包含语义是不合适的,这会导致恢复图像的域偏移,例如细节模糊和背景不一致。因此,我们尝试从输入中学习包含更丰富的纹理和语义特征的更广义的表示,即不变表示。为此,在该方法中引入了基于对抗域自适应的离散表示学习和自监督约束模块。细节将在接下来的小节中描述。
3.1 离散表示学习
离散表示旨在从输入中计算潜在编码,其中 z z z包含尽可能多的纹理和语义信息。为此,我们使用两个自编码器分别对 { E X , G X } \{E_X, G_X\} {EX,GX}和 { E Y , G Y } \{E_Y, G_Y\} {EY,GY}进行建模。给定任意未配对样本 ( x , y ) (x, y) (x,y),其中 x ∈ X x∈X x∈X切 y ∈ Y y∈Y y∈Y分别表示来自不同域的噪声样本和干净样本,将Eq. 1重新表述为 z X = E X ( x ) z_X = E_X (x) zX=EX(x)和 z Y = E Y ( y ) z_Y = E_Y (y) zY=EY(y)。进一步,IR可以表示为$ F x → y ( x ) = G Y ( z X ) F^{x→y}(x) = G_Y(z_X) Fx→y(x)=GY(zX)。然而,由于噪声总是附着在高频信号上,由于噪声水平和类型的变化,直接重建干净图像是很困难的,这需要强大的域发生器和鉴别器。因此,我们将解缠表示引入到我们的架构中。
解缠表示。对于噪声样本 x x x,使用额外的噪声编码器 E X N E^N_X EXN来对变化的噪声水平和类型进行建模。自重构由 x = G X ( z X , z X N ) x=G_X(z_X,z^N_X) x=GX(zX,zXN)表示,其中 z X = E X ( x ) z_X=E_X(x) zX=EX(x)和 z X N = E X N ( x ) z^N_X=E^N_X(x) zXN=EXN(x)。假设潜在码 z X z_X zX和 z Y z_Y zY在共享空间中服从相同的分布, { z X , z Y } ∈ Z \{z_X,z_Y\}∈Z {zX,zY}∈Z,类似于图像平移,无监督图像恢复可以分为两个阶段:前向平移和后向重建。
前向平移。我们首先从
(
x
,
y
)
(x,y)
(x,y)和额外噪声码
z
X
N
z^N_X
zXN中提取表示
{
z
X
,
z
Y
}
\{z_X,z_Y\}
{zX,zY}。恢复和退化可以表示为:
x
~
X
→
Y
=
G
y
(
z
X
)
y
~
Y
→
X
=
G
X
(
z
y
+
z
X
N
)
\tilde x^{X \to Y} = G_y(z_X) \\ \quad \\ \tilde y^{Y\to X}= G_X(z_y + z_X^N)
x~X→Y=Gy(zX)y~Y→X=GX(zy+zXN)
其中
X
→
Y
X→Y
X→Y表示复原的清晰样本,
Y
→
X
Y→X
Y→X表示退化的噪声样本。
G
X
G_X
GX和
G
Y
G_Y
GY被视为特定的域生成器。
反向交叉重建。在执行第一次平移后,可以通过交换输入来实现重建
x
~
X
→
Y
\tilde x^{X \to Y}
x~X→Y和
y
~
Y
→
X
\tilde y^{Y \to X}
y~Y→X表示:
x
^
=
G
X
(
E
y
(
x
~
X
→
Y
)
+
E
x
N
(
y
~
Y
→
X
)
)
y
^
=
G
y
(
E
X
(
y
~
Y
→
X
)
)
\hat x = G_X(E_y(\tilde x^{X \to Y})+ E_x^N(\tilde y^{Y \to X})) \\ \quad \\ \hat y = G_y(E_X(\tilde y^{Y \to X}))
x^=GX(Ey(x~X→Y)+ExN(y~Y→X))y^=Gy(EX(y~Y→X))
其中,
x
^
\hat x
x^和
y
^
\hat y
y^表示重构输入。为了加强这一约束,我们为X和Y域添加了交叉周期一致性损失
L
C
C
L^{CC}
LCC:
L
X
C
C
(
G
X
,
G
Y
,
E
X
,
E
Y
,
E
X
N
)
=
E
X
(
∣
∣
G
X
(
E
y
(
x
~
X
→
Y
)
+
E
X
N
(
y
~
Y
→
X
)
)
−
x
∣
∣
1
)
L
Y
C
C
(
G
X
,
G
Y
,
E
X
,
E
Y
,
E
X
N
)
=
E
Y
(
∣
∣
G
Y
(
E
y
(
y
~
Y
→
X
)
)
−
y
∣
∣
1
)
L^{CC}_X(G_X,G_Y,E_X,E_Y,E^N_X) = \mathbb{E}_X(||G_X(E_y(\tilde x^{X\to Y})+E^N_X(\tilde y^{Y\to X}))-x||_1)\\ \quad \\ L^{CC}_Y(G_X,G_Y,E_X,E_Y,E^N_X) = \mathbb{E}_Y(||G_Y(E_y(\tilde y^{Y\to X}))-y||_1)\\
LXCC(GX,GY,EX,EY,EXN)=EX(∣∣GX(Ey(x~X→Y)+EXN(y~Y→X))−x∣∣1)LYCC(GX,GY,EX,EY,EXN)=EY(∣∣GY(Ey(y~Y→X))−y∣∣1)
对抗性领域适应。另一个因素是如何将潜在表示
z
X
z_X
zX和
z
Y
z_Y
zY嵌入到共享空间中。受无监督域自适应的启发,我们通过对抗性学习而不是共享权重编码器来实现它。我们的目标是促进服从相似分布的输入的表示,同时保留输入的更丰富的纹理和语义信息。因此,在我们的体系结构中使用了表示判别器
D
R
D_R
DR。我们将这一特征表示为对抗损失
L
a
d
v
R
L^R_{adv}
LadvR:
L
a
d
v
R
(
E
X
,
E
Y
,
D
R
)
=
E
X
[
1
2
l
o
g
D
R
(
z
X
)
+
1
2
l
o
g
(
1
−
D
R
(
z
X
)
)
]
+
E
Y
[
1
2
l
o
g
D
R
(
z
Y
)
+
1
2
l
o
g
(
1
−
D
R
(
z
Y
)
)
]
L_{adv}^R(E_X,E_Y,D_R) = \mathbb{E}_X\left[\frac{1}{2}logD_R(z_X)+\frac{1}{2}log(1-D_R(z_X))\right]+ \mathbb{E}_Y\left[\frac{1}{2}logD_R(z_Y)+\frac{1}{2}log(1-D_R(z_Y))\right]
LadvR(EX,EY,DR)=EX[21logDR(zX)+21log(1−DR(zX))]+EY[21logDR(zY)+21log(1−DR(zY))]
3.2 自监督限制
由于转移后的图像缺乏有效的监督信号,仅依靠特征域判别约束将不可避免地导致生成图像的域移位问题。为了加快收敛速度,同时学习更鲁棒的表示,引入了自监督模块,包括背景一致性模块(BCM)和语义一致性模块(SCM),以提供更合理和可靠的监督。
BCM的目的是保持转移图像和输入图像之间的背景一致性。类似的策略也被应用于自监督图像重建任务。这些方法利用梯度误差约束重构图像,通过模糊算子对输入和输出图像进行平滑处理,如高斯模糊核和制导滤波。与之不同的是,在我们的模块中,对恢复的图像直接使用L1损失,而不是梯度误差损失,如图3所示,在我们的实验中,这是一种简单而有效的方法,可以在保持背景一致性的同时恢复更精细的纹理。具体来说,采用多尺度高斯模糊算子分别获得多尺度特征。因此,背景一致性损失可表示为:
L
B
C
=
∑
σ
=
5
,
9
,
15
λ
σ
∣
∣
(
B
σ
(
X
)
−
B
σ
(
X
~
)
)
∣
∣
1
L_{BC} = \sum_{\sigma=5,9,15} \lambda_\sigma||(B_\sigma(X)-B_\sigma(\tilde X))||_1
LBC=σ=5,9,15∑λσ∣∣(Bσ(X)−Bσ(X~))∣∣1
其中,
B
σ
(
⋅
)
B_σ(·)
Bσ(⋅)为模糊核为
σ
σ
σ的高斯模糊算子,
λ
σ
λ_σ
λσ为平衡不同高斯模糊水平误差的超参数。
X
X
X和
X
~
\tilde X
X~表示原始输入和转移后的输出,即
{
x
,
x
~
X
→
Y
}
\{x, \tilde x^{X→Y}\}
{x,x~X→Y}和
{
Y
,
y
~
Y
→
X
}
\{Y, \tilde y^{Y→X}\}
{Y,y~Y→X}。基于对图像去噪的实验尝试,当σ ={5,9,15}时,我们将
λ
σ
λ_σ
λσ分别设置为{0.25,0.5,1.0}。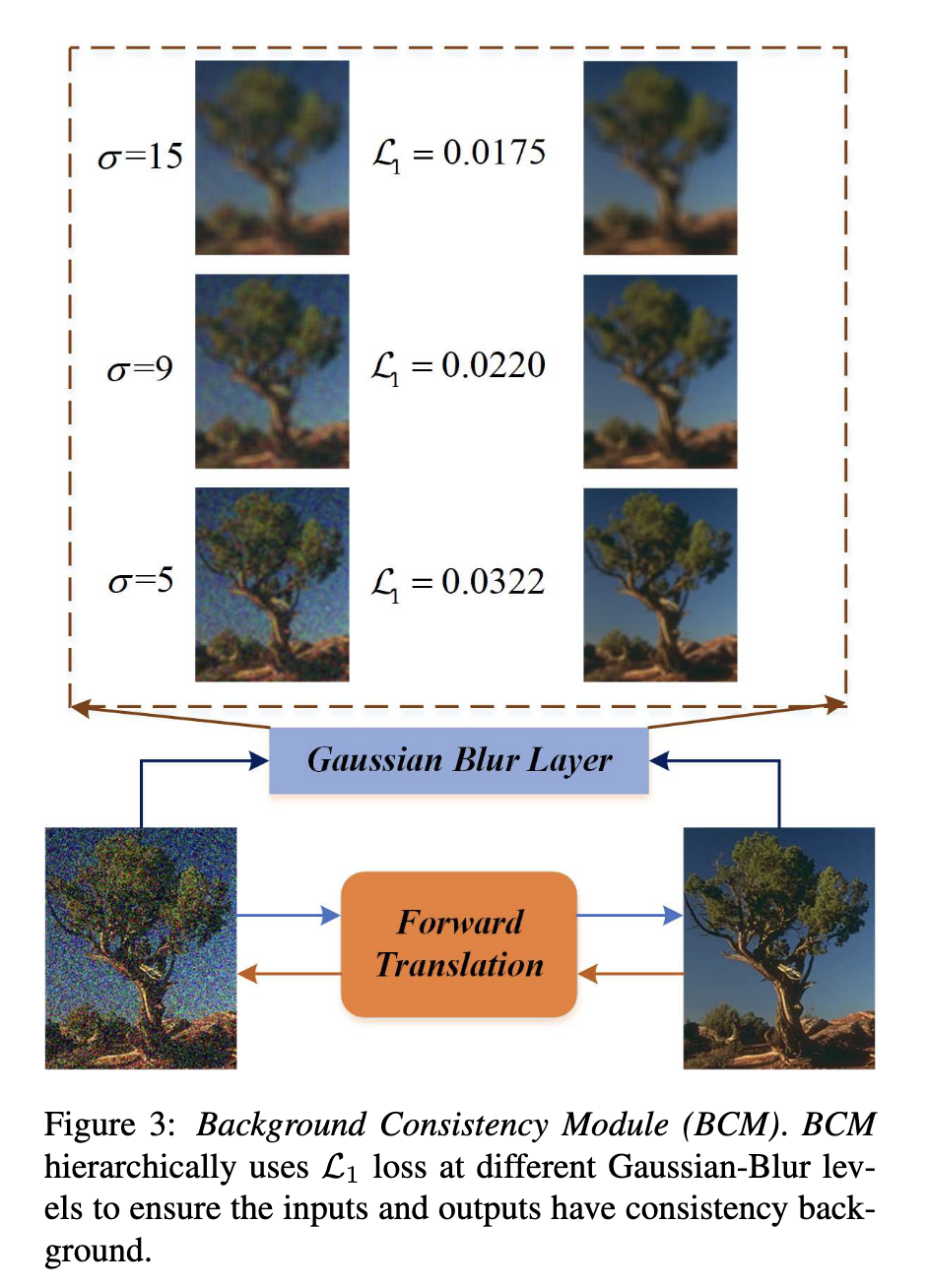
此外,受感知损失的启发,预训练模型的深层特征只包含语义含义,这些语义含义是无噪声的或噪声很小的。因此,与一般的特征损失是通过浅层特征之间的相似性来恢复更精细的图像纹理细节不同,我们只从损坏和恢复的图像中提取更深层的特征作为语义表示来保持一致性,称为语义一致性损失
L
S
C
L_{SC}
LSC。它可以被表示为
L
S
C
=
∣
∣
ϕ
l
(
X
)
−
ϕ
l
(
X
~
)
∣
∣
2
2
L_{SC} = ||\phi_l(X)-\phi_l(\tilde X)||^2_2
LSC=∣∣ϕl(X)−ϕl(X~)∣∣22
其中
ϕ
(
⋅
)
\phi(·)
ϕ(⋅)表示预训练模型的
l
l
l层特征。在我们的实验中,我们在ImageNet上使用了VGG-19预训练网络的conv5-1层。
4. 实验
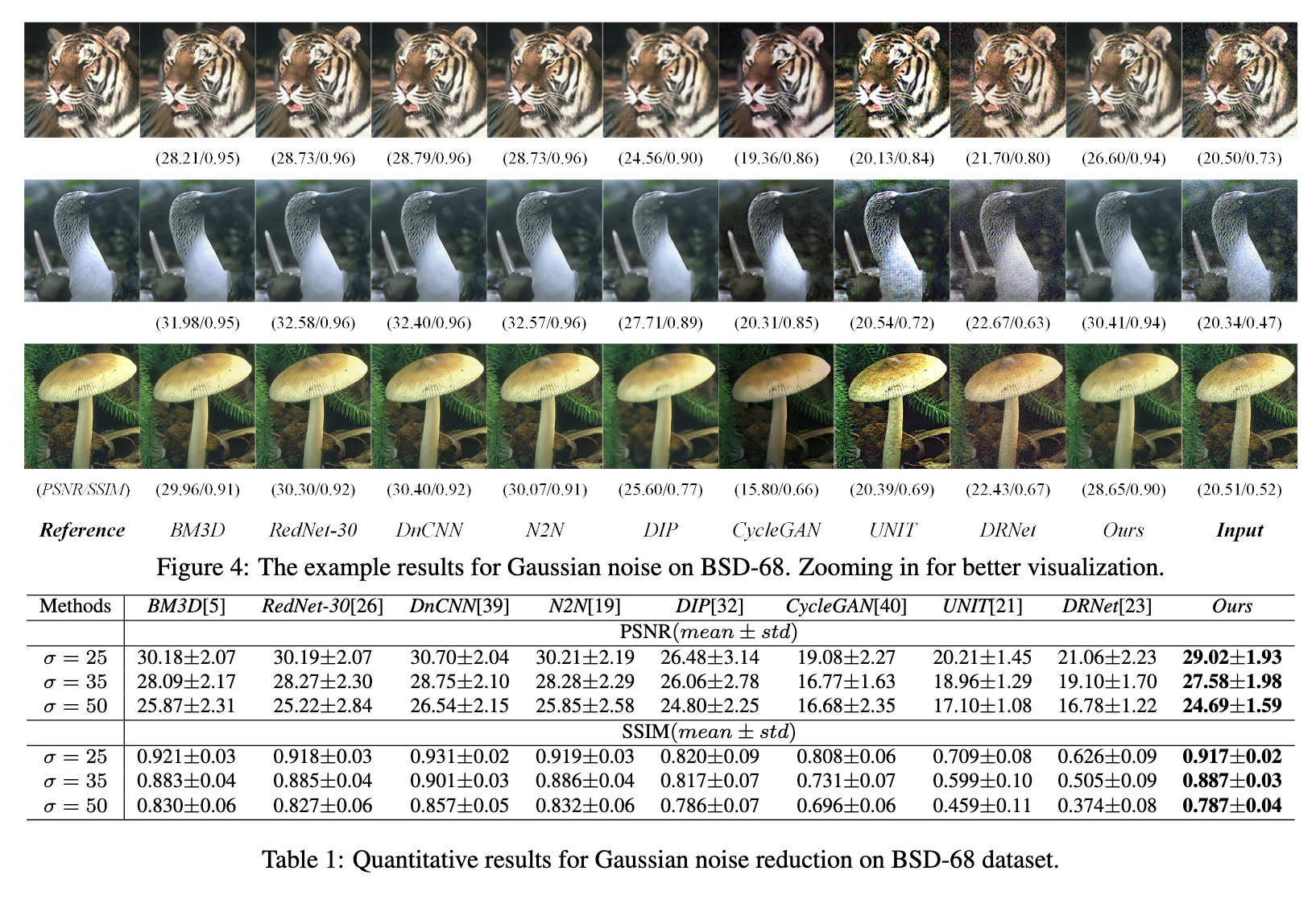
测试的时候,直接用图2中的 E X E_X EX和 G Y G_Y GY进行图像复原。其实可以看到,一些指标甚至不如DnCNN。但这个不是问题~

标签:Learning Invariant Representation for Unsupervised Image Restoration
- 程序开发学习排行
- 最近发表