

怒刷LeetCode的第17天(Java版)
作者:小教学发布时间:2023-10-01分类:程序开发学习浏览:258
目录
第一题
题目来源
题目内容
解决方法
方法一:过滤和排序
方法二:迭代
第二题
题目来源
题目内容
解决方法
方法一:回溯算法
方法二:动态规划
方法三:DFS+剪枝
方法四:动态规划+状态压缩
方法五:广度优先搜索(BFS)
第三题
题目来源
题目内容
解决方法
方法一:回溯算法
方法二:记忆化搜索
方法三:递归加剪枝
第一题
题目来源
1333. 餐厅过滤器 - 力扣(LeetCode)
题目内容

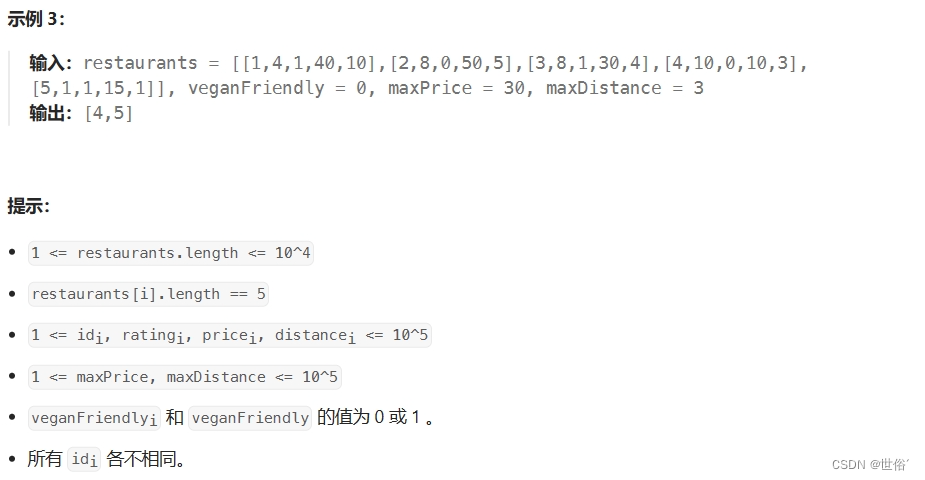
解决方法
方法一:过滤和排序
这道题的思路和算法如下:
-
首先,将二维数组 restaurants 转换为餐馆对象列表。每个餐馆对象包含 id、rating、veganFriendly、price 和 distance 五个属性。
-
使用过滤器条件对餐馆列表进行过滤:
- 如果 veganFriendly 为 1,那么只保留 veganFriendly 属性为 1 的餐馆;
- 如果 maxPrice 不为 0,那么只保留价格小于等于 maxPrice 的餐馆;
- 如果 maxDistance 不为 0,那么只保留距离小于等于 maxDistance 的餐馆。
-
对过滤后的餐馆列表进行排序:
- 首先按照 rating 从高到低排序;
- 如果 rating 相同,那么按照 id 从高到低排序。
-
返回排序后的餐馆id列表。
import java.util.*;
class Restaurant {
int id;
int rating;
int veganFriendly;
int price;
int distance;
public Restaurant(int id, int rating, int veganFriendly, int price, int distance) {
this.id = id;
this.rating = rating;
this.veganFriendly = veganFriendly;
this.price = price;
this.distance = distance;
}
}
class Solution {
public List<Integer> filterRestaurants(int[][] restaurants, int veganFriendly, int maxPrice, int maxDistance) {
List<Restaurant> restaurantList = new ArrayList<>();
// 将二维数组转换为餐馆对象列表
for (int[] res : restaurants) {
restaurantList.add(new Restaurant(res[0], res[1], res[2], res[3], res[4]));
}
// 使用过滤器条件进行过滤
return restaurantList.stream()
.filter(r -> veganFriendly == 0 || r.veganFriendly == veganFriendly)
.filter(r -> r.price <= maxPrice && r.distance <= maxDistance)
.sorted((r1, r2) -> {
if (r1.rating == r2.rating) {
return r2.id - r1.id;
} else {
return r2.rating - r1.rating;
}
})
.map(r -> r.id)
.collect(Collectors.toList());
}
}复杂度分析:
- 餐馆列表转换为餐馆对象列表的时间复杂度为 O(n),其中 n 是餐馆的数量。
- 过滤器操作的时间复杂度为 O(n),需要遍历整个餐馆列表。
- 排序操作的时间复杂度为 O(nlogn),其中 n 是过滤后的餐馆列表的数量。在排序过程中,比较函数的时间复杂度可以忽略不计。
因此,总的时间复杂度为 O(nlogn)。
空间复杂度方面,需要额外使用一个餐馆对象列表来存储转换后的餐馆信息,所以空间复杂度为 O(n),其中 n 是餐馆的数量。
综上所述,该算法的时间复杂度为 O(nlogn),空间复杂度为 O(n)。
LeetCode运行结果:
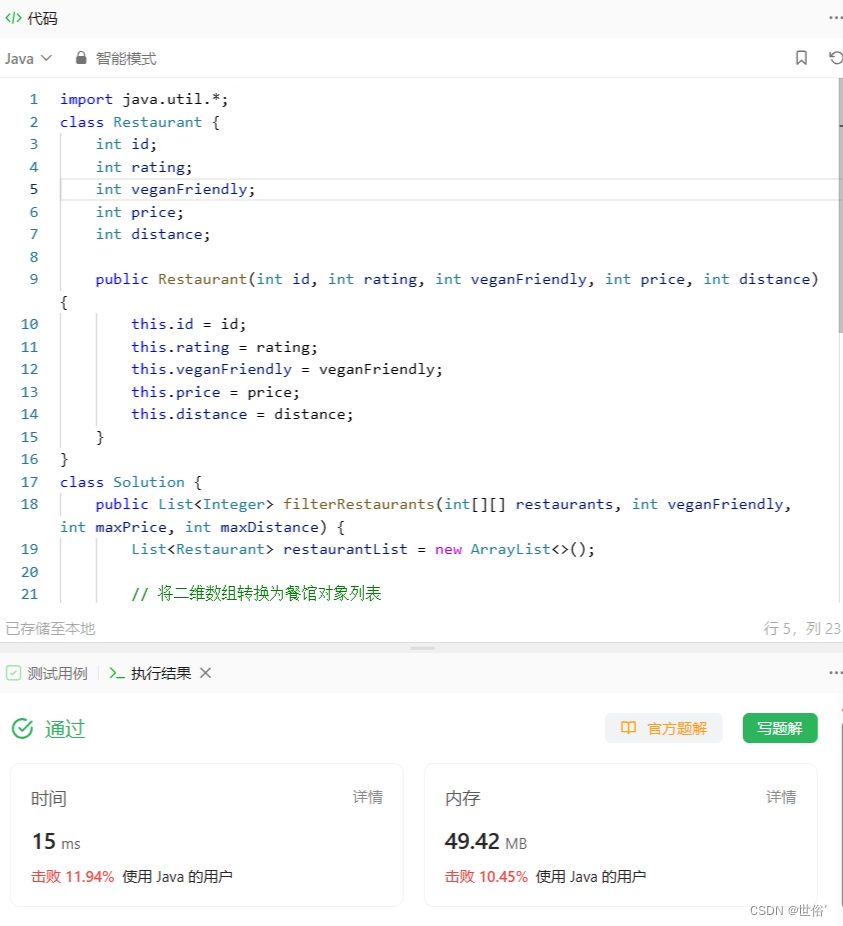
方法二:迭代
思路和算法如下:
- 遍历 restaurants 数组,对每个餐馆进行判断和过滤。
- 根据 veganFriendly、maxPrice 和 maxDistance 的条件进行过滤:
- 如果 veganFriendly = 1,则只选择 veganFriendly = 1 的餐馆;否则,不考虑 veganFriendly 条件。
- 只选择价格不超过 maxPrice 的餐馆。
- 只选择距离不超过 maxDistance 的餐馆。
- 使用一个辅助数据结构(例如优先队列或者链表)存储符合条件的餐馆信息,并按照评分和 id 进行排序:
- 如果两个餐馆的评分相等,则根据 id 进行降序排序。
- 如果两个餐馆的评分不等,则根据评分进行降序排序。
- 遍历辅助数据结构,提取餐馆的 id,并返回作为结果列表。
import java.util.ArrayList;
import java.util.List;
public class Solution {
public List<Integer> filterRestaurants(int[][] restaurants, int veganFriendly, int maxPrice, int maxDistance) {
List<int[]> filtered = new ArrayList<>();
// 过滤符合条件的整型数组
for (int[] res : restaurants) {
if ((veganFriendly == 1 && res[2] == 0) || res[3] > maxPrice || res[4] > maxDistance) {
continue;
}
filtered.add(res);
}
// 根据评分和 id 进行排序
filtered.sort((r1, r2) -> {
if (r1[1] == r2[1]) {
return r2[0] - r1[0];
} else {
return r2[1] - r1[1];
}
});
// 提取餐馆 id 并返回
List<Integer> result = new ArrayList<>();
for (int[] res : filtered) {
result.add(res[0]);
}
return result;
}
}
复杂度分析:
假设 restaurants 数组的长度为 n。
- 遍历 restaurants 数组并进行过滤,时间复杂度为 O(n)。
- 在过滤后的餐馆中进行排序。最坏情况下,需要对 n 个餐馆进行排序,时间复杂度为 O(nlogn)。
- 遍历排序后的列表,提取餐馆的 id。时间复杂度为 O(n)。
综上所述,该算法的时间复杂度为 O(nlogn)。
对于空间复杂度,主要取决于存储过程中的辅助数据结构的大小。在这种情况下,使用一个辅助数据结构(例如优先队列或链表)来存储过滤和排序后的餐馆信息。假设过滤后符合条件的餐馆数量为 m,则辅助数据结构的大小为 O(m)。因此,算法的空间复杂度为 O(m)。
LeetCode运行结果:
第二题
题目来源
39. 组合总和 - 力扣(LeetCode)
题目内容

解决方法
方法一:回溯算法
这个问题可以使用回溯算法来解决。回溯算法是一种通过不断尝试所有可能的选择,并在遇到不满足条件的情况时进行回退,继续尝试其他选择的算法。具体的思路如下:
- 首先对候选数组进行排序,以便后续剪枝操作。
- 创建一个结果集和一个临时列表,用于保存满足条件的组合和当前正在构建的组合。
- 定义一个回溯函数,参数包括当前目标值、当前位置、候选数组、临时列表和结果集。
- 在回溯函数中,首先判断当前目标值是否等于0,如果是,则表示找到了一个满足条件的组合,将临时列表加入到结果集中。
- 如果当前目标值小于0,则表示当前组合不满足条件,直接返回。
- 如果当前目标值大于0,则需要继续尝试其他选择。从当前位置开始遍历候选数组,每次选择一个元素,将其加入到临时列表中,并将当前目标值减去该元素。然后递归调用回溯函数,传入新的目标值、下一个位置、候选数组、临时列表和结果集。
- 在递归调用完成后,需要回溯(撤销选择),即将临时列表中的最后一个元素删除,目标值加上该元素,继续循环下一个元素进行尝试。
- 在主函数中,调用回溯函数并传入初始参数,最后返回结果集。
这样,就可以找到所有满足条件的组合了。注意,为了避免重复的组合出现,我们在每次递归调用时,从当前位置开始选择元素,而不是从0开始选择。这样可以保证每个元素只能使用一次,避免重复的组合。另外,对于给定的输入,保证和为目标值的不同组合数少于150个,所以回溯算法是可行的,不会超时。
import java.util.ArrayList;
import java.util.List;
class Solution {
public List<List<Integer>> combinationSum(int[] candidates, int target) {
List<List<Integer>> result = new ArrayList<>();
List<Integer> path = new ArrayList<>();
backtrack(candidates, target, 0, path, result);
return result;
}
private void backtrack(int[] candidates, int target, int start, List<Integer> path, List<List<Integer>> result) {
if (target < 0) {
return;
}
if (target == 0) {
result.add(new ArrayList<>(path));
return;
}
for (int i = start; i < candidates.length; i++) {
path.add(candidates[i]);
backtrack(candidates, target - candidates[i], i, path, result);
path.remove(path.size() - 1);
}
}
}
复杂度分析:
回溯算法的时间复杂度和空间复杂度通常是难以精确计算的,因为它涉及到了所有可能的组合情况。但可以从一个大致的角度进行分析。
设候选数组的长度为 n,目标值为 target。
时间复杂度:
- 最坏情况下,需要遍历所有可能的组合情况。每个位置有 n 种选择(候选数组中的元素),而最多需要递归 target 次。因此,时间复杂度为 O(n^target)。
- 平均情况下,由于回溯算法会进行剪枝操作,减少无效的搜索路径,所以平均时间复杂度会小于最坏情况。但具体的平均时间复杂度难以准确计算。
空间复杂度:
- 回溯算法需要使用额外的空间来保存临时列表和结果集。临时列表的长度最多为 target,结果集中的每个组合的平均长度也为 target。因此,空间复杂度为 O(target)。
- 递归调用过程中,系统的函数调用栈深度最多为 target,所以空间复杂度也可以表示为 O(target)。
综上所述,回溯算法的时间复杂度为 O(n^target),空间复杂度为 O(target)。在实际应用中,需要根据具体问题规模和约束条件综合考虑算法的效率和可用性。
LeetCode运行结果:

方法二:动态规划
除了回溯算法,也可以使用动态规划来解决这个问题。
在动态规划方法中,我们使用一个二维数组dp来保存每个目标值对应的所有组合。dp[i]中存储的是目标值为i时的所有组合。
- 首先对候选数组进行排序,然后遍历每个目标值,内层循环遍历候选数字。
- 如果候选数字等于目标值,说明找到了一种组合,将其加入combinations列表中。 否则,遍历dp[i - candidates[j]]中的每个组合,如果当前候选数字不大于已选择的数字中的最小值,说明可以将当前候选数字加入到组合中,形成新的组合。将新的组合加入combinations列表中。
- 最后,将combinations赋值给dp[i],完成当前目标值的计算。 最终,返回dp[target]即可得到所有满足条件的组合。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
class Solution {
public List<List<Integer>> combinationSum(int[] candidates, int target) {
Arrays.sort(candidates); // 对数组进行排序
List<List<List<Integer>>> dp = new ArrayList<>();
// 初始化dp数组
for (int i = 0; i <= target; i++) {
dp.add(new ArrayList<>());
}
// 遍历每个目标值
for (int i = 1; i <= target; i++) {
List<List<Integer>> combinations = new ArrayList<>();
// 遍历每个候选数字
for (int j = 0; j < candidates.length && candidates[j] <= i; j++) {
if (candidates[j] == i) {
combinations.add(Arrays.asList(candidates[j]));
} else {
for (List<Integer> prev : dp.get(i - candidates[j])) {
if (candidates[j] <= prev.get(0)) {
List<Integer> combination = new ArrayList<>();
combination.add(candidates[j]);
combination.addAll(prev);
combinations.add(combination);
}
}
}
}
dp.set(i, combinations);
}
return dp.get(target);
}
}
复杂度分析:
- 时间复杂度:排序候选数组的时间复杂度为O(nlogn),遍历每个目标值和候选数字的时间复杂度为O(target * n),在内层循环中可能还会遍历已选择数字的组合,因此总体时间复杂度为O(nlogn + target * n^2)。
- 空间复杂度:除了存储结果集的空间外,动态规划解法使用了一个二维数组dp来保存所有的组合,其大小为O(target * k),其中k为平均每个目标值能够找到的组合数量。因此,空间复杂度为O(target * k)。
LeetCode运行结果:
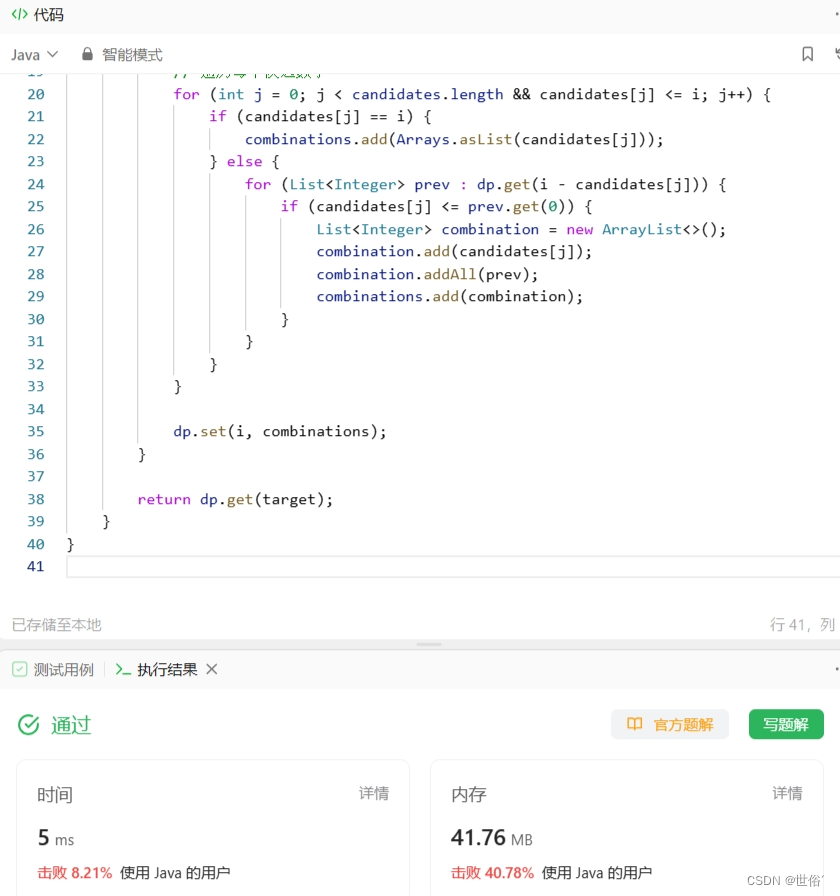
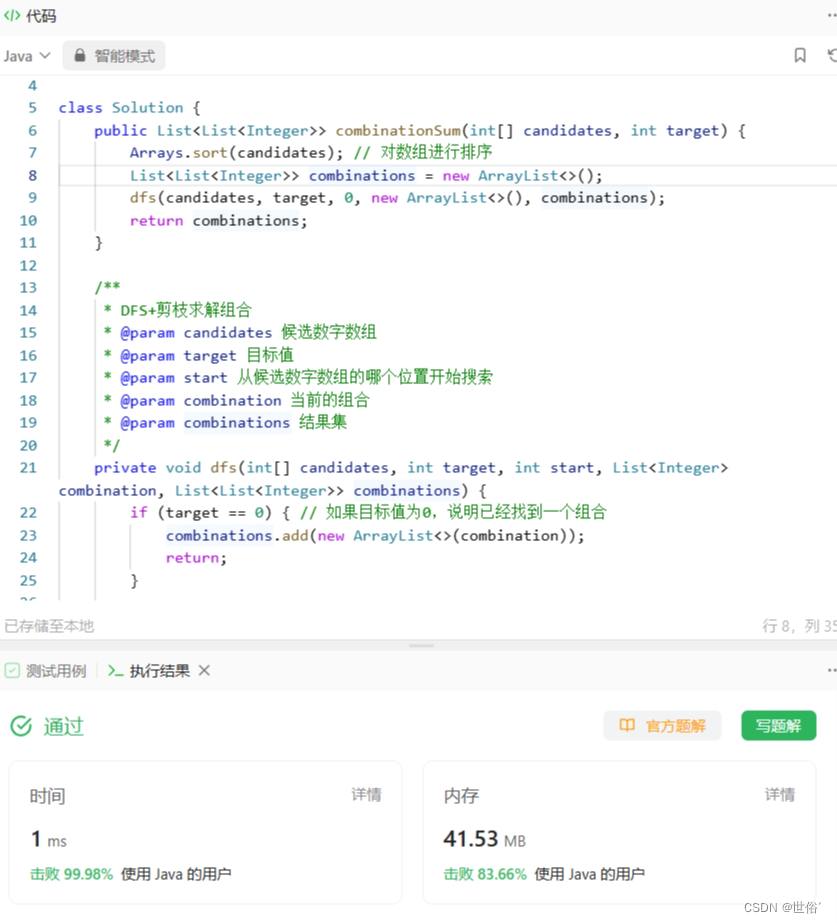
方法三:DFS+剪枝
除了回溯算法和动态规划之外,还可以使用DFS+剪枝的方法来解决这个问题。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
class Solution {
public List<List<Integer>> combinationSum(int[] candidates, int target) {
Arrays.sort(candidates); // 对数组进行排序
List<List<Integer>> combinations = new ArrayList<>();
dfs(candidates, target, 0, new ArrayList<>(), combinations);
return combinations;
}
/**
* DFS+剪枝求解组合
* @param candidates 候选数字数组
* @param target 目标值
* @param start 从候选数字数组的哪个位置开始搜索
* @param combination 当前的组合
* @param combinations 结果集
*/
private void dfs(int[] candidates, int target, int start, List<Integer> combination, List<List<Integer>> combinations) {
if (target == 0) { // 如果目标值为0,说明已经找到一个组合
combinations.add(new ArrayList<>(combination));
return;
}
for (int i = start; i < candidates.length && candidates[i] <= target; i++) {
// 剪枝操作:如果当前候选数字已经比目标值大了,就没有继续搜索的必要了
if (candidates[i] > target) {
break;
}
combination.add(candidates[i]); // 将当前候选数字加入到组合中
dfs(candidates, target - candidates[i], i, combination, combinations); // 继续搜索,从当前候选数字开始搜索
combination.remove(combination.size() - 1); // 回溯操作:将当前候选数字移除组合
}
}
}
在DFS+剪枝方法中,我们使用一个dfs函数来实现搜索。首先对候选数字进行排序,然后从0位置开始搜索。遍历候选数字数组,如果当前候选数字不大于目标值,将其加入到组合中。然后,将目标值减去当前候选数字,继续从当前位置开始搜索,直到目标值为0。如果目标值为0,说明已经找到一个组合,将其加入到combinations列表中。 回溯操作时,将当前候选数字从组合中移除,继续搜索下一个候选数字。
可以看出,与回溯算法相比,DFS+剪枝方法会在搜索过程中进行一些剪枝操作,从而减少了不必要的递归调用,提高了效率。
复杂度分析:
- 时间复杂度:在最坏情况下,每个数字都可以选择无限次,因此可以看作有n层的完全二叉树,每层的节点数减半。所以时间复杂度为O(2^n)。
- 空间复杂度:除了存储结果集的空间外,DFS过程中需要使用递归调用栈的空间,最坏情况下递归栈的深度为n。因此,空间复杂度为O(n)。
需要注意的是,虽然DFS+剪枝方法可以在搜索过程中减少不必要的递归调用,但在最坏情况下,仍然需要遍历所有可能的组合,因此其时间复杂度与回溯算法相同。空间复杂度方面,DFS+剪枝方法与回溯算法相比,由于没有维护二维数组dp,所以空间复杂度略低一些。
LeetCode运行结果:
方法四:动态规划+状态压缩
使用Java的动态规划+状态压缩方法来解决组合总和问题。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class Solution {
public List<List<Integer>> combinationSum(int[] candidates, int target) {
Arrays.sort(candidates); // 对数组进行排序
int[] dp = new int[target + 1]; // 动态规划数组
List<List<Integer>> combinations = new ArrayList<>();
dp[0] = 1; // 初始化dp[0]为1
for (int candidate : candidates) {
for (int i = candidate; i <= target; i++) {
if (dp[i - candidate] > 0) {
// 如果dp[i - candidate]不为0,说明可以通过当前候选数字得到目标值i
dp[i] += dp[i - candidate]; // 更新dp[i]
}
}
}
if (dp[target] == 0) {
// 如果dp[target]为0,说明无法得到目标值target,直接返回空列表
return combinations;
}
dfs(candidates, target, 0, new ArrayList<>(), combinations, dp); // 使用DFS搜索符合条件的组合
return combinations;
}
private void dfs(int[] candidates, int target, int start, List<Integer> combination, List<List<Integer>> combinations, int[] dp) {
if (target == 0) { // 如果目标值为0,说明已经找到一个组合
combinations.add(new ArrayList<>(combination));
return;
}
for (int i = start; i < candidates.length && target >= candidates[i]; i++) {
if (dp[target - candidates[i]] > 0) {
combination.add(candidates[i]); // 将当前候选数字加入到组合中
dfs(candidates, target - candidates[i], i, combination, combinations, dp); // 继续搜索,从当前候选数字开始搜索
combination.remove(combination.size() - 1); // 回溯操作:将当前候选数字移除组合
}
}
}
}
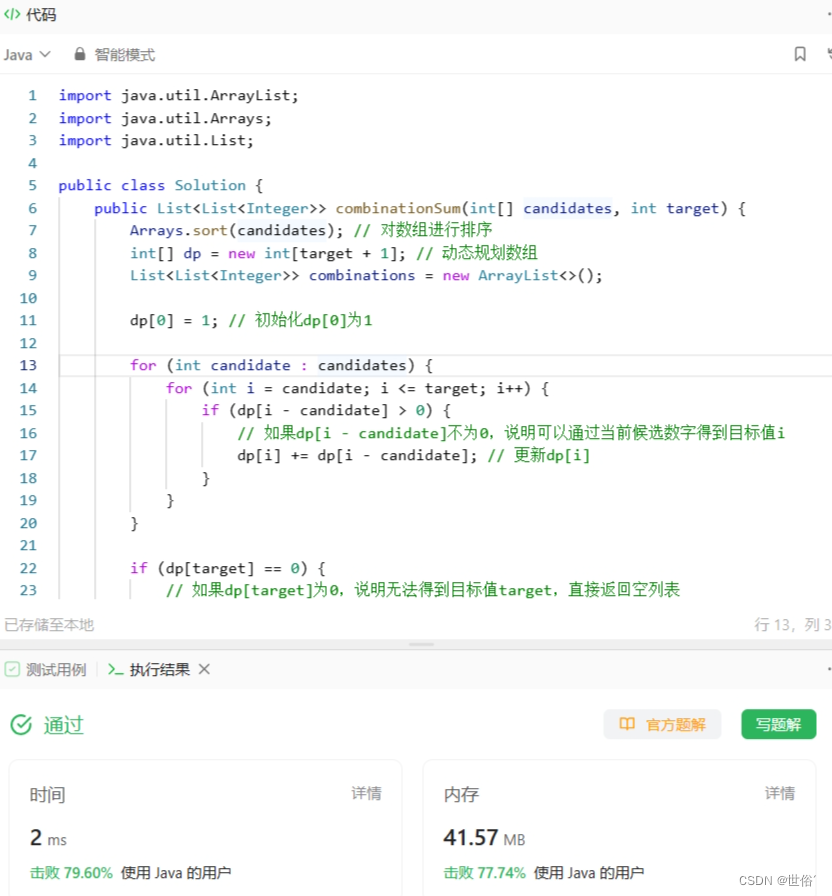
该方法的核心思想是使用动态规划数组dp记录每个目标值对应的组合数。首先初始化dp[0]为1,表示目标值为0时有一种组合方式。然后,按照候选数字的顺序更新dp数组,遍历候选数字数组,并从候选数字开始更新dp数组中的对应位置。如果dp[i - candidate]不为0,则说明可以通过当前候选数字得到目标值i,因此更新dp[i] += dp[i - candidate]。
在DFS过程中,我们根据dp数组进行剪枝操作,只选择能够达到目标值的候选数字进行搜索。如果dp[target]为0,说明无法得到目标值target,直接返回空列表。否则,继续使用DFS搜索符合条件的组合。
复杂度分析:
时间复杂度:
- 排序数组的时间复杂度为O(nlogn),其中n为候选数字数组的长度。
- 初始化dp数组的时间复杂度为O(target),遍历候选数字数组的时间复杂度为O(n)。
- 动态规划的更新过程需要遍历候选数字数组,并对每个目标值进行更新,因此总时间复杂度为O(target * n)。
空间复杂度:
- 动态规划数组dp的长度为target+1,因此其空间复杂度为O(target)。
- 递归调用时的栈空间取决于目标值和候选数字的组合情况,在最坏情况下可能达到O(target)。
综上所述,使用动态规划+状态压缩方法解决组合总和问题的时间复杂度为O(target * n),空间复杂度为O(target)。在实际应用中,如果目标值较大,则算法的效率会受到限制。因此,对于较大的目标值,可能需要考虑其他优化方法或策略来提高算法效率。
LeetCode运行结果:
方法五:广度优先搜索(BFS)
使用Java的广度优先搜索(BFS)方法来解决组合总和问题。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
public class Solution {
public List<List<Integer>> combinationSum(int[] candidates, int target) {
Arrays.sort(candidates); // 对数组进行排序
List<List<Integer>> combinations = new ArrayList<>();
Queue<State> queue = new LinkedList<>(); // 使用队列保存搜索状态
// 初始化队列,将初始状态(目标值、路径、起始位置)加入队列
queue.offer(new State(target, new ArrayList<>(), 0));
while (!queue.isEmpty()) {
State state = queue.poll(); // 取出当前状态
if (state.target == 0) { // 如果目标值为0,说明已经找到一个符合条件的组合
combinations.add(state.path);
continue;
}
for (int i = state.start; i < candidates.length && candidates[i] <= state.target; i++) {
List<Integer> newPath = new ArrayList<>(state.path);
newPath.add(candidates[i]); // 将当前候选数字加入到路径中
// 将更新后的状态(目标值、路径、起始位置)加入队列
queue.offer(new State(state.target - candidates[i], newPath, i));
}
}
return combinations;
}
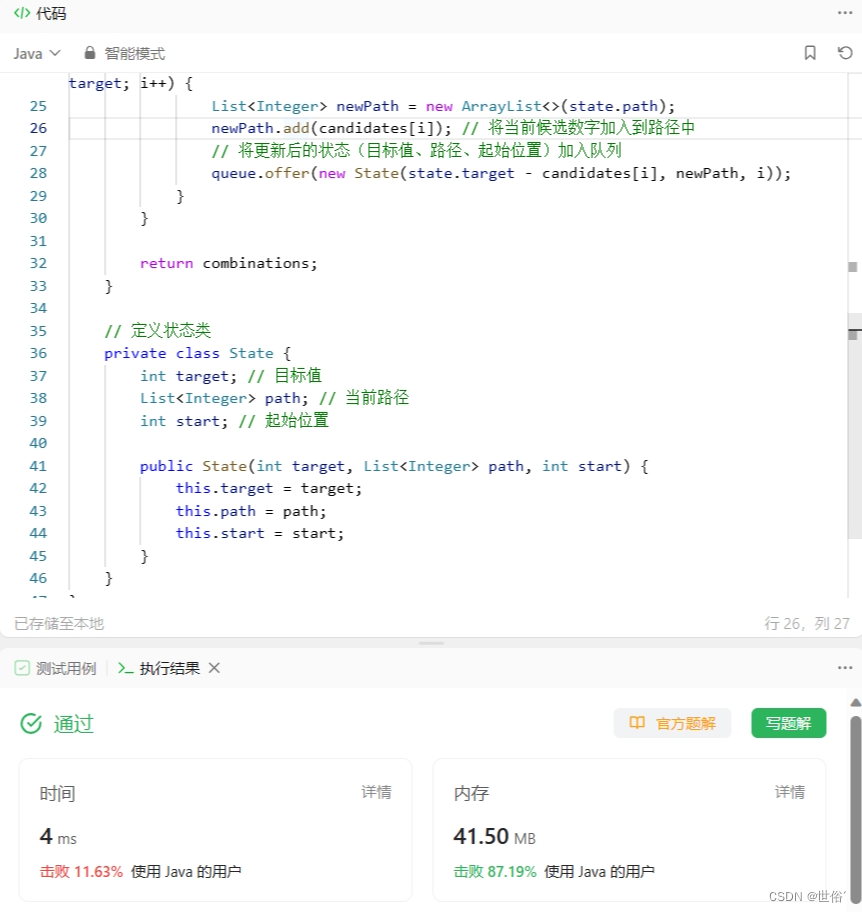
// 定义状态类
private class State {
int target; // 目标值
List<Integer> path; // 当前路径
int start; // 起始位置
public State(int target, List<Integer> path, int start) {
this.target = target;
this.path = path;
this.start = start;
}
}
}
该方法使用广度优先搜索(BFS)进行搜索。使用队列保存搜索状态,每次从队列中取出一个状态进行拓展,直到队列为空。
在每一次拓展过程中,依次选择候选数字,并判断是否满足以下条件:
- 如果目标值为0,说明已经找到一个符合条件的组合,将其添加到结果列表中。
- 否则,将更新后的状态(目标值、路径、起始位置)加入队列。起始位置为当前候选数字的位置,以确保不会重复选择之前的数字。
由于每个位置的数字可以重复使用,因此每次拓展时仍可以选择当前候选数字及之后的数字。这样可以保证得到所有可能的组合。
复杂度分析:
设 n 为候选数字数组 candidates 的长度,m 为目标值 target 的大小,k 为结果列表 combinations 的平均长度(即每个组合的平均元素个数)。
-
时间复杂度:
- 排序候选数字数组的时间复杂度为 O(nlogn)。
- 在广度优先搜索过程中,最坏情况下可能需要遍历所有可能的组合。每次拓展时,需要对候选数字进行遍历,时间复杂度为 O(n)。共有 k 个组合,因此总的时间复杂度为 O(kn)。
- 综上所述,算法的总时间复杂度为 O(nlogn + kn)。
-
空间复杂度:
- 需要额外的空间存储排序后的候选数字数组,空间复杂度为 O(n)。
- 记录搜索状态需要的空间为 O(m)。
- 结果列表 combinations 最多会包含 k 个组合,每个组合的平均长度为 k。因此,结果列表的空间复杂度为 O(k^2)。
- 综上所述,算法的总空间复杂度为 O(n + m + k^2)。
总结起来,使用广度优先搜索(BFS)的组合总和问题算法的时间复杂度为 O(nlogn + kn),空间复杂度为 O(n + m + k^2)。
LeetCode运行结果:
第三题
题目来源
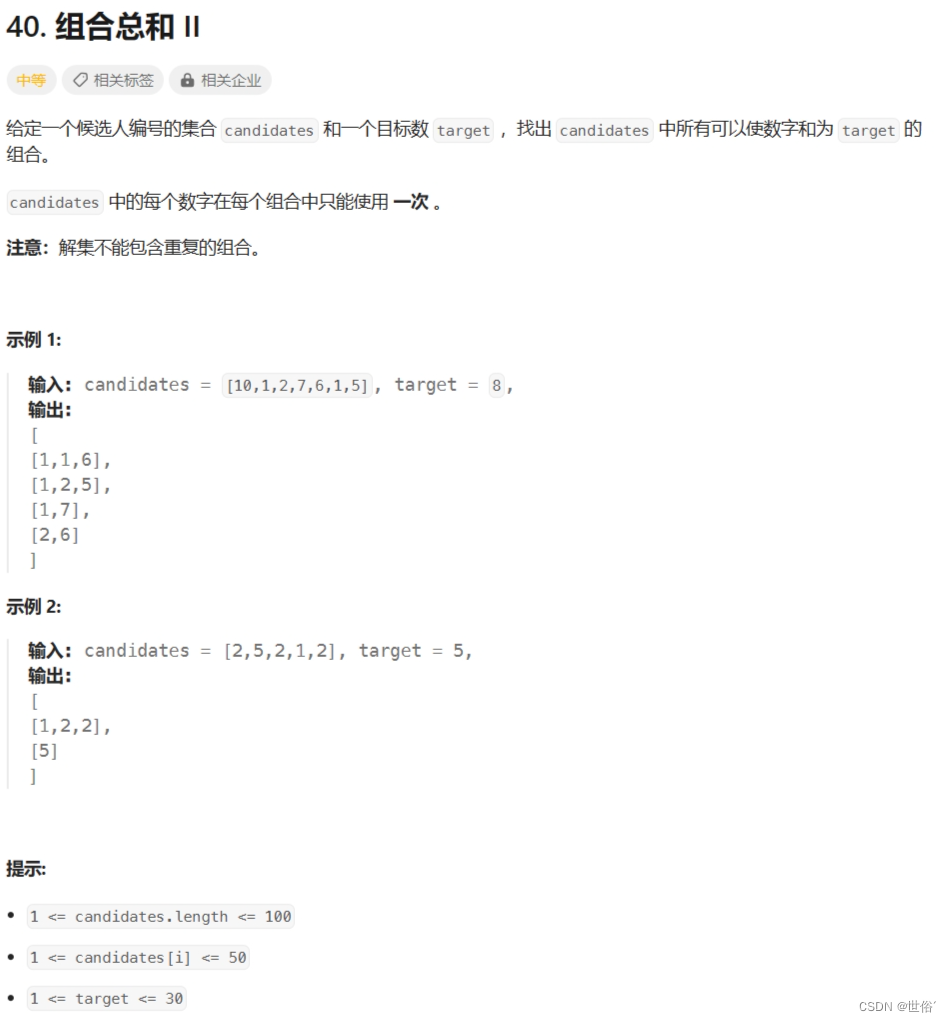
40. 组合总和 II - 力扣(LeetCode)
题目内容
解决方法
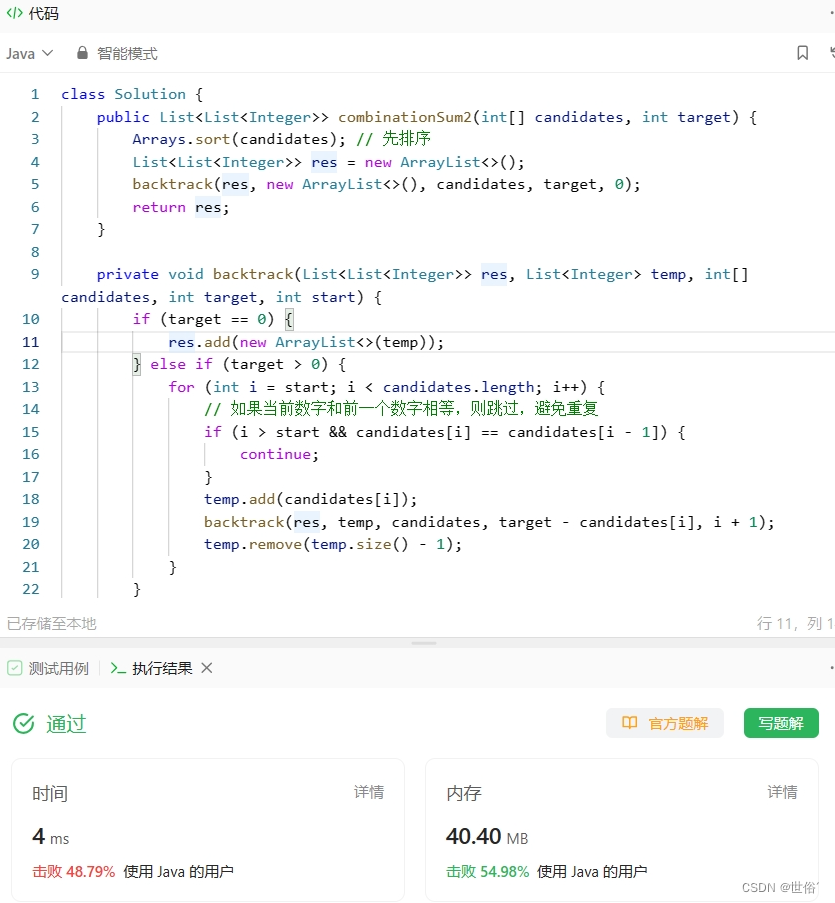
方法一:回溯算法
算法思路:
- 首先将候选数字数组排序。
- 然后使用回溯算法,在搜索过程中维护一个结果列表 res 和一个路径列表 temp。temp 记录当前搜索路径,res 记录符合要求的结果。
- 对于每个位置 i,如果当前数字等于前一个数字,则跳过,避免出现重复的组合。
- 如果当前路径 temp 的元素和刚好等于目标值 target,则将该路径添加到结果列表中。
- 如果当前路径 temp 的元素和小于目标值 target,则在当前位置之后继续搜索,将当前数字添加到路径列表 temp 中。
- 如果当前路径 temp 的元素和大于目标值 target,则直接结束搜索。
class Solution {
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates); // 先排序
List<List<Integer>> res = new ArrayList<>();
backtrack(res, new ArrayList<>(), candidates, target, 0);
return res;
}
private void backtrack(List<List<Integer>> res, List<Integer> temp, int[] candidates, int target, int start) {
if (target == 0) {
res.add(new ArrayList<>(temp));
} else if (target > 0) {
for (int i = start; i < candidates.length; i++) {
// 如果当前数字和前一个数字相等,则跳过,避免重复
if (i > start && candidates[i] == candidates[i - 1]) {
continue;
}
temp.add(candidates[i]);
backtrack(res, temp, candidates, target - candidates[i], i + 1);
temp.remove(temp.size() - 1);
}
}
}
}
复杂度分析:
算法的时间复杂度取决于两个因素,候选数字数组的长度(n)和目标数 target 的大小(m)。
- 排序候选数字数组的时间复杂度为 O(nlogn)。
- 在回溯过程中,在最坏情况下需要遍历所有可能的组合。每次递归时,需要对后面的候选数字进行遍历,时间复杂度为 O(n)。共有 k 个组合,因此总的时间复杂度为 O(kn)。
- 综上所述,算法的总时间复杂度为 O(nlogn + kn)。
空间复杂度主要取决于递归过程中使用的栈空间和结果列表的空间。
- 在回溯过程中,使用一个栈来保存当前路径,空间复杂度为 O(m)。
- 结果列表最多会包含 k 个组合,每个组合的平均长度为 k。因此,结果列表的空间复杂度为 O(k^2)。
- 综上所述,算法的总空间复杂度为 O(m + k^2)。
需要注意的是,排序操作会占用一定的时间和空间,但由于排序只需要进行一次,所以对于整体的时间和空间复杂度影响较小。
LeetCode运行结果:
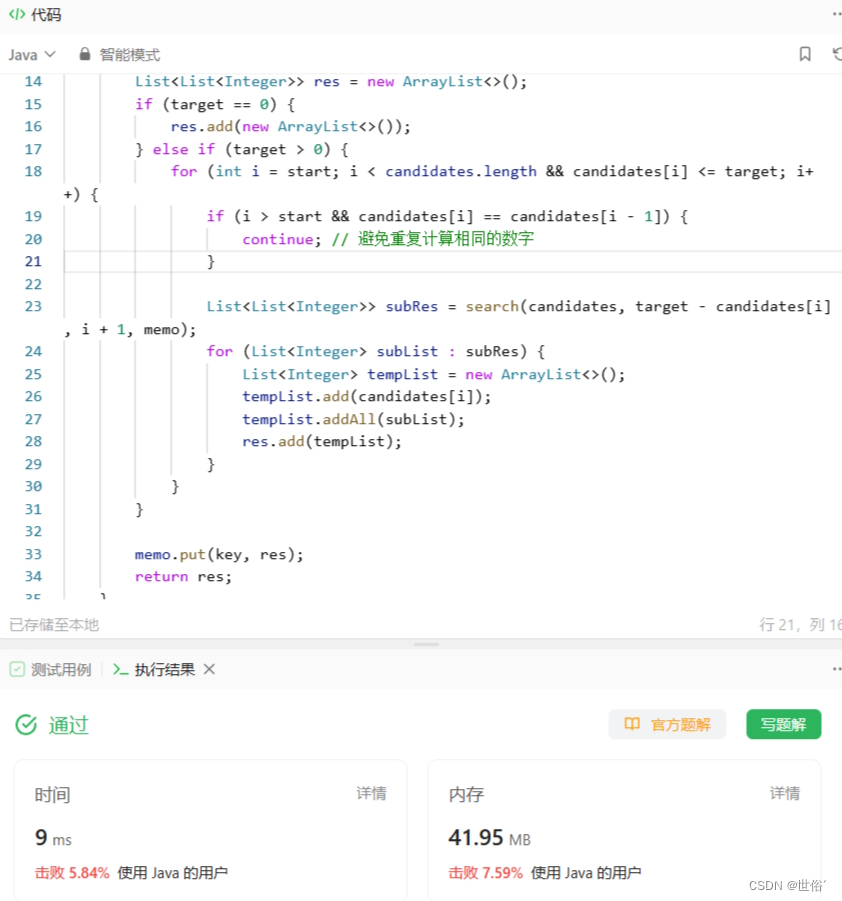
方法二:记忆化搜索
除了回溯算法,还可以使用记忆化搜索(Memoization Search)来解决这个问题。
记忆化搜索的思路类似于回溯算法。在递归过程中,为了避免重复计算某些值,我们可以使用一个记忆化数组 memo,记录每个状态的计算结果。在递归过程中,如果遇到一个已经计算过的状态,则直接返回其对应的计算结果,避免重复计算。
class Solution {
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates);
Map<String, List<List<Integer>>> memo = new HashMap<>();
return search(candidates, target, 0, memo);
}
private List<List<Integer>> search(int[] candidates, int target, int start, Map<String, List<List<Integer>>> memo) {
String key = target + "," + start;
if (memo.containsKey(key)) {
return memo.get(key);
}
List<List<Integer>> res = new ArrayList<>();
if (target == 0) {
res.add(new ArrayList<>());
} else if (target > 0) {
for (int i = start; i < candidates.length && candidates[i] <= target; i++) {
if (i > start && candidates[i] == candidates[i - 1]) {
continue; // 避免重复计算相同的数字
}
List<List<Integer>> subRes = search(candidates, target - candidates[i], i + 1, memo);
for (List<Integer> subList : subRes) {
List<Integer> tempList = new ArrayList<>();
tempList.add(candidates[i]);
tempList.addAll(subList);
res.add(tempList);
}
}
}
memo.put(key, res);
return res;
}
}
复杂度分析:
对于记忆化搜索的复杂度分析,我们可以将其分为两个部分来看:计算每个状态的时间复杂度和总状态数。
- 计算每个状态的时间复杂度: 在记忆化搜索中,每个状态都是通过递归调用得到的。对于每个状态,我们需要遍历候选数字数组(从当前位置开始),并进行递归调用搜索下一个状态。因此,计算每个状态的时间复杂度为 O(n),其中 n 是候选数字数组的长度。
- 总状态数: 记忆化搜索的关键在于避免重复计算。我们使用一个记忆化数组 memo 来记录每个状态的计算结果,以避免重复计算。理想情况下,不同的状态数应该是有限的,并且相对较小。但在最坏情况下,当候选数字数组中的数字都很小且接近目标数 target 时,可能会有较多的状态需要计算。因此,总状态数的上界为 O(2^n),其中 n 是候选数字数组的长度。
综上所述,记忆化搜索的时间复杂度为 O(n * 2^n),其中 n 是候选数字数组的长度。空间复杂度为 O(n * m),其中 n 是候选数字数组的长度,m 是目标数 target 的大小。记忆化数组 memo 的空间复杂度为 O(n * m)。这里的空间复杂度主要取决于 memo 数组的大小。同时,递归调用的栈空间复杂度也为 O(n),因为在最坏情况下,回溯的深度可能达到 n 级别。
LeetCode运行结果:
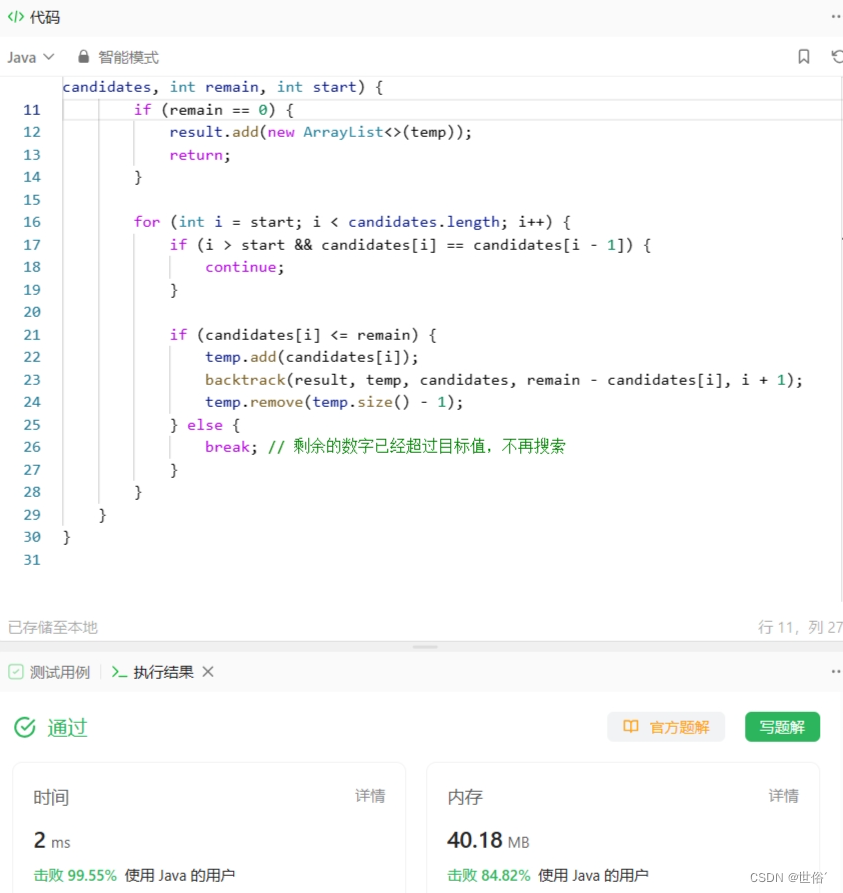
方法三:递归加剪枝
除了回溯算法和记忆化搜索,还可以使用递归加剪枝的方法来解决该问题。这种方法类似于回溯算法,但通过一些条件判断来减少搜索的分支。
在递归加剪枝的方法中,我们首先对候选数字数组 candidates 进行排序。然后,使用回溯的方式从候选数字数组中选择数字,并进行相应的剪枝操作。
在每一轮的选择中,我们从 start 位置开始遍历候选数字数组。如果当前数字和上一个数字相同且不是起始位置,则跳过,以避免重复组合的产生。
对于每个选择,我们有两个分支:
- 如果当前数字小于等于剩余目标值 remain,则将其加入到当前组合 temp 中,并递归调用 backtrack 函数继续选择下一个数字。
- 如果当前数字大于剩余目标值 remain,则说明剩下的数字都已经超过目标值,无需再搜索,直接结束本轮选择。
当 remain 等于 0 时,表示已经找到一个合法的组合,将其加入到结果列表 result 中。
该方法通过剪枝操作,减少了不必要的搜索分支,提高了效率。
class Solution {
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates);
List<List<Integer>> result = new ArrayList<>();
List<Integer> temp = new ArrayList<>();
backtrack(result, temp, candidates, target, 0);
return result;
}
private void backtrack(List<List<Integer>> result, List<Integer> temp, int[] candidates, int remain, int start) {
if (remain == 0) {
result.add(new ArrayList<>(temp));
return;
}
for (int i = start; i < candidates.length; i++) {
if (i > start && candidates[i] == candidates[i - 1]) {
continue;
}
if (candidates[i] <= remain) {
temp.add(candidates[i]);
backtrack(result, temp, candidates, remain - candidates[i], i + 1);
temp.remove(temp.size() - 1);
} else {
break; // 剩余的数字已经超过目标值,不再搜索
}
}
}
}
复杂度分析:
时间复杂度和空间复杂度与回溯算法相同,为 O(n * 2^n) 和 O(n)。
LeetCode运行结果:
- 上一篇:Leetcode 50.Pow(x,n)
- 下一篇:基于SSM的实习管理系统
- 程序开发学习排行
- 最近发表