

【考研数学】概率论与数理统计 —— 第三章 | 二维随机变量及其分布(2,常见的二维随机变量及二维变量的条件分布和独立性)
作者:小教学发布时间:2023-09-30分类:程序开发学习浏览:255
文章目录
- 引言
- 四、常见的二维随机变量
- 4.1 二维均匀分布
- 4.2 二维正态分布
- 五、二维随机变量的条件分布
- 5.1 二维离散型随机变量的条件分布律
- 5.2 二维连续型随机变量的条件分布
- 六、随机变量的独立性
- 6.1 基本概念
- 6.2 随机变量独立的等价条件
- 写在最后
引言
有了上文关于二维随机变量的基本概念与性质后,我们可以往后继续学习更加深入的内容。
四、常见的二维随机变量
4.1 二维均匀分布
设 ( X , Y ) (X,Y) (X,Y) 为二维随机变量, D D D 为 x O y xOy xOy 平面的有限区域,其面积为 A A A ,若 ( X , Y ) (X,Y) (X,Y) 的联合密度函数为 f ( x , y ) = { 1 A , ( x , y ) ∈ D 0 , ( x , y ) ∉ D , f(x,y)=\begin{cases} \frac{1}{A} ,&(x,y)\in D \\ 0,&(x,y) \notin D \end{cases}, f(x,y)={A1,0,(x,y)∈D(x,y)∈/D, 称 ( X , Y ) (X,Y) (X,Y) 为区域 D D D 上的服从均匀分布。
可以回想一下一维的均匀分布,它是长度的倒数。
4.2 二维正态分布
这个我就不手敲了,太长啦,根本记不住。
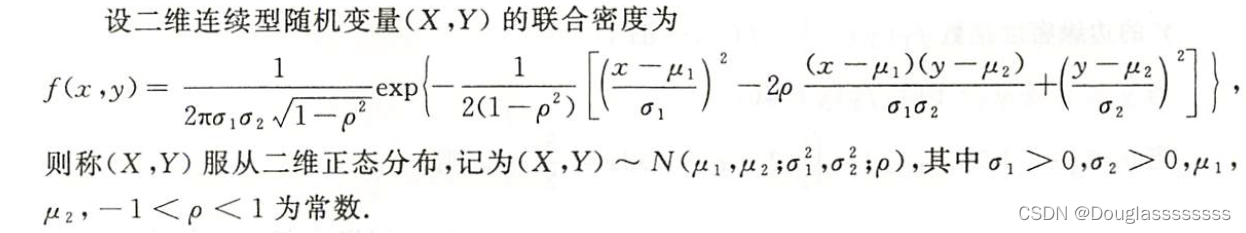
其中,
ρ
\rho
ρ 为两个随机变量的相关系数。
若 ( X , Y ) ∼ N ( μ 1 , μ 2 ; σ 1 2 , σ 2 2 ; ρ ) (X,Y)\sim N(\mu_1,\mu_2;\sigma_1^2,\sigma_2^2;\rho) (X,Y)∼N(μ1,μ2;σ12,σ22;ρ) ,则 X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 2 , σ 2 2 ) . X \sim N(\mu_1,\sigma_1^2),Y \sim N(\mu_2,\sigma_2^2). X∼N(μ1,σ12),Y∼N(μ2,σ22). 当 a 2 + b 2 ≠ 0 a^2+b^2 \ne 0 a2+b2=0 时,有 a X + b Y aX+bY aX+bY 服从一维正态分布。随机变量 X X X 和 Y Y Y 独立的充要条件是两个变量不相关,即 ρ ≠ 0 \rho \ne 0 ρ=0 。
五、二维随机变量的条件分布
5.1 二维离散型随机变量的条件分布律
设 ( X , Y ) (X,Y) (X,Y) 为二维离散型随机变量,其联合分布律为 P { X = x i , Y = y j } = p i j ( i = 1 , 2 , ⋯ , m ; j = 1 , 2 , ⋯ , n ) . P\{X=x_i,Y=y_j\}=p_{ij}(i=1,2,\cdots,m;j=1,2,\cdots,n). P{X=xi,Y=yj}=pij(i=1,2,⋯,m;j=1,2,⋯,n). (1)对某个固定的 i i i ,若 P { X = x i } > 0 P\{X=x_i\}>0 P{X=xi}>0 ,则称 P { Y = y j ∣ X = x i } = P { X = x i , Y = y j } P { X = x i } = p i j p i ⋅ ( j = 1 , 2 , ⋯ , n ) P\{Y=y_j | X=x_i\}=\frac{P\{X=x_i,Y=y_j\}}{P\{X=x_i\}}=\frac{p_{ij}}{p_{i\cdot}}(j=1,2,\cdots,n) P{Y=yj∣X=xi}=P{X=xi}P{X=xi,Y=yj}=pi⋅pij(j=1,2,⋯,n) 为在 X = x i X=x_i X=xi 条件下随机变量 Y Y Y 的条件分布律。
(2)对某个固定的 j j j ,若 P { Y = y j } > 0 P\{Y=y_j\}>0 P{Y=yj}>0 ,则称 P { X = x i ∣ Y = y j } = P { X = x i , Y = y j } P { Y = y j } = p i j p ⋅ j ( i = 1 , 2 , ⋯ , m ) P\{X=x_i | Y=y_j\}=\frac{P\{X=x_i,Y=y_j\}}{P\{Y=y_j\}}=\frac{p_{ij}}{p_{\cdot j}}(i=1,2,\cdots,m) P{X=xi∣Y=yj}=P{Y=yj}P{X=xi,Y=yj}=p⋅jpij(i=1,2,⋯,m) 为在 Y = y i Y=y_i Y=yi 条件下随机变量 X X X 的条件分布律。
5.2 二维连续型随机变量的条件分布
设 ( X , Y ) (X,Y) (X,Y) 为二维连续型随机变量,联合密度函数为 f ( x , y ) f(x,y) f(x,y) ,变量 X , Y X,Y X,Y 的边缘密度函数分别为 f X ( x ) , f Y ( y ) . f_X(x),f_Y(y). fX(x),fY(y).
对固定的 X = x X=x X=x ,若 f X ( x ) > 0 f_X(x)>0 fX(x)>0 ,称 P { Y ≤ y ∣ X = x } = ∫ − ∞ y f ( x , y ) f X ( x ) d y P\{Y\leq y | X=x\}=\int_{-\infty}^y\frac{f(x,y)}{f_X(x)}dy P{Y≤y∣X=x}=∫−∞yfX(x)f(x,y)dy 为在 X = x X=x X=x 条件下 Y Y Y 的条件分布函数, f ( x , y ) f X ( x ) \frac{f(x,y)}{f_X(x)} fX(x)f(x,y) 为条件密度函数。对于固定的 Y = y Y=y Y=y ,可同理得到类似结论。
我看老汤也没给证明,自己也没想明白为什么,就上网搜了下,发现是做了近似处理。

六、随机变量的独立性
6.1 基本概念
设 A , B A,B A,B 为两个随机事件,若 P ( A B ) = P ( A ) P ( B ) P(AB)=P(A)P(B) P(AB)=P(A)P(B) ,称事件 A , B A,B A,B 独立;设 ( X , Y ) (X,Y) (X,Y) 为二维随机变量,令 { X ≤ x } = A , { Y ≤ y } = B \{X\leq x\}=A,\{Y\leq y\}=B {X≤x}=A,{Y≤y}=B ,则 P ( A B ) = P ( A ) P ( B ) P(AB)=P(A)P(B) P(AB)=P(A)P(B) 等价于 F ( x , y ) = P { X ≤ x , Y ≤ y } = P { X ≤ x } P { Y ≤ y } = F X ( x ) F Y ( y ) . F(x,y)=P\{X\leq x,Y\leq y\}=P\{X\leq x\}P\{Y\leq y\}=F_X(x)F_Y(y). F(x,y)=P{X≤x,Y≤y}=P{X≤x}P{Y≤y}=FX(x)FY(y). 于是有如下定义:
设 ( X , Y ) (X,Y) (X,Y) 为二维随机变量, F ( x , y ) F(x,y) F(x,y) 为其联合分布函数, F X ( x ) , F Y ( y ) F_X(x),F_Y(y) FX(x),FY(y) 分别为 X , Y X,Y X,Y 的边缘分布函数,若 F ( x , y ) = F X ( x ) = F Y ( y ) F(x,y)=F_X(x)=F_Y(y) F(x,y)=FX(x)=FY(y) ,称变量 X , Y X,Y X,Y 相互独立。同理可扩展到 n n n 维。
6.2 随机变量独立的等价条件

设
(
X
1
,
X
2
.
⋯
,
X
m
)
(X_1,X_2.\cdots,X_m)
(X1,X2.⋯,Xm) 与
(
Y
1
,
Y
2
,
⋯
,
Y
n
)
(Y_1,Y_2,\cdots,Y_n)
(Y1,Y2,⋯,Yn) 相互独立,则由
(
X
1
,
X
2
.
⋯
,
X
m
)
(X_1,X_2.\cdots,X_m)
(X1,X2.⋯,Xm) 构成的函数
φ
(
X
1
,
X
2
.
⋯
,
X
m
)
\varphi(X_1,X_2.\cdots,X_m)
φ(X1,X2.⋯,Xm) 与
(
Y
1
,
Y
2
,
⋯
,
Y
n
)
(Y_1,Y_2,\cdots,Y_n)
(Y1,Y2,⋯,Yn) 构成的函数
φ
(
Y
1
,
Y
2
,
⋯
,
Y
n
)
\varphi(Y_1,Y_2,\cdots,Y_n)
φ(Y1,Y2,⋯,Yn) 相互独立。
写在最后
其实如果一维的能掌握好一些,二维的可以类比来学,下一篇来说说二维随机变量的最后一个内容 —— 二维随机变量函数的分布。
- 上一篇:关于汽车维修类中译英的英语翻译
- 下一篇:Guava限流器原理浅析
- 程序开发学习排行
- 最近发表