

【C++】vector基本接口介绍
作者:小教学发布时间:2023-09-30分类:程序开发学习浏览:289

vector接口目录:
一、vector的初步介绍
1.1vector和string的联系与不同
1.2 vector的源码参数
二、vector的四种构造(缺省+填充元素+迭代器+拷贝构造)
三、vecto的扩容操作与机制
3.1resize(老朋友了,不会就去看string ) && reserve
3.2 reserve的扩容机制
3.3 vector和malloc分别实现动态开辟的二维数组
118. 杨辉三角 - 力扣(LeetCode)
四、三种遍历方式
4.1operator[ ]对于越界访问的检查机制(一段经典的代码错误)
4.2三种遍历方式
五、vector的修改操作
5.1 assign和迭代器的配合使用
5.2 insert和find(vector库中没有find)的配合使用
inset && find例子:
5.3 类外、类内、算法库的3个swap(编译器费心良苦)
六、看源码时需要注意的问题
一、vector的初步介绍
1.1vector和string的联系与不同
1. vector底层也是用动态顺序表实现的,和string是一样的,但是string默认存储的就是字符串,而vector的功能较为强大一些,vector不仅能存字符,理论上所有的内置类型和自定义类型都能存,vector的内容可以是一个自定义类型的对象,也可以是一个内置类型的变量。
2. vector在使用时需要进行类模板的实例化,因为传递的模板参数不同,则vector存储的元素类型就会有变化,所以在使用vector的时候要进行类模板的显式实例化。
类模板的第二个参数是空间配置器,这个学到后面再说,而且这个参数是有缺省值的,我们只用这个缺省值就欧克了,所以在使用vector时,只需要关注第一个参数即可。
1.2 vector的源码参数

二、vector的四种构造(缺省+填充元素+迭代器+拷贝构造)
vector 提供了四种构造方式 – 无参构造、n 个 val 构造、迭代器区间构造以及拷贝构造:
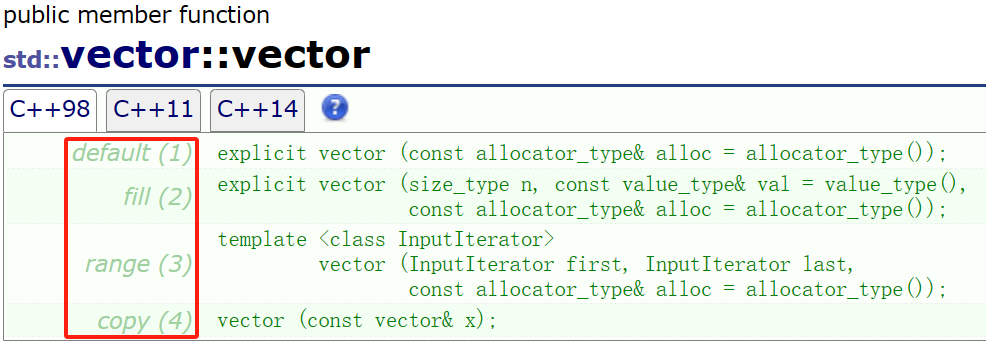

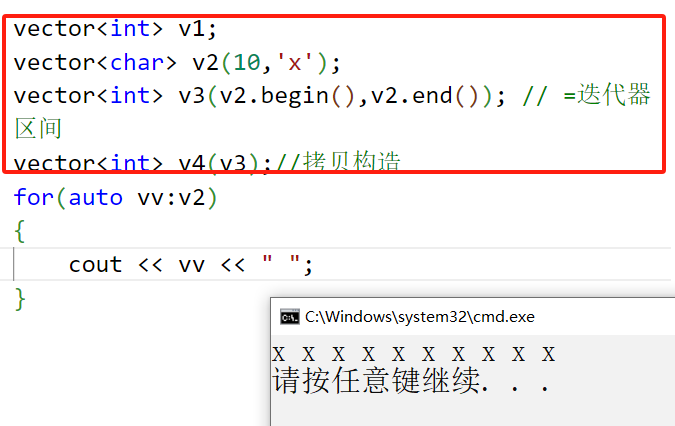
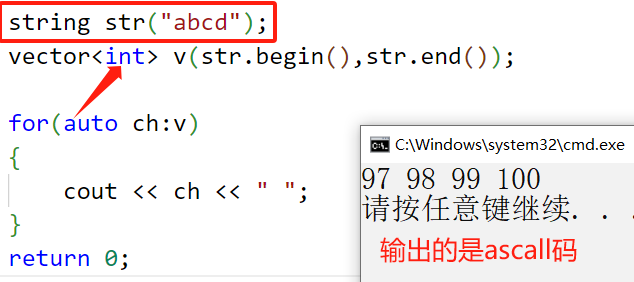
需要注意的是,迭代器区间构造是一个函数模板,即我们可以用其他类来构造 vector 对象:
三、vecto的扩容操作与机制
3.1resize(老朋友了,不会就去看string ) && reserve
1. 对于string和vector,reserve和resize是独有的,因为他们的底层都是动态顺序表实现的,list就没有reserve和resize,因为他底层是链表嘛
2. 对于reserve这个函数来说,官方并没有将其设定为能够兼容实现缩容的功能,明确规定这个函数在其他情况下,例如预留空间要比当前小的情况下,这个函数的调用是不会引起空间的重新分配的,也就是说容器vector的capacity是不会被影响的。
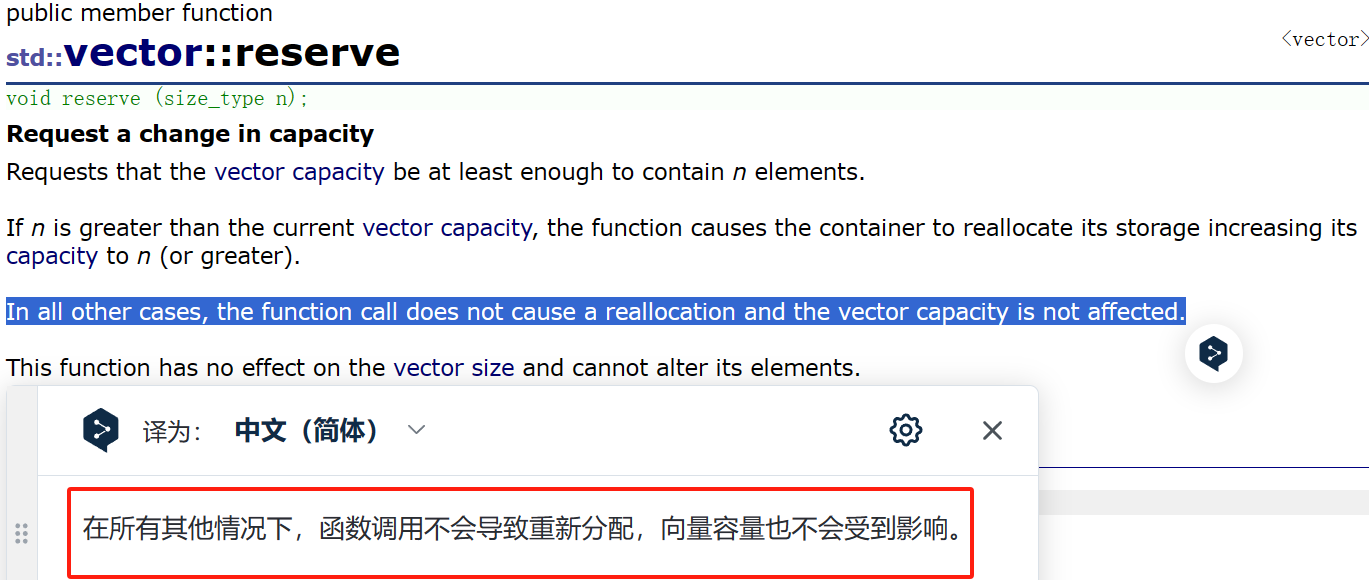
为什么它不会进行缩容?
因为我们在缩容的时候,不是简单的砍一刀后面丢掉,必须重新开辟空间,进行异地缩容。缩容表面看起来是降低了空间的使用率,想要提高程序的效率,但实际上并未提高效率,缩容是需要异地缩容的,需要重新开空间和拷贝数据,代价不小,所以平常不建议对空间进行缩容。reserve不缩容,其实也是一种空间换时间的操作
3. vector的resize和string的resize同样具有三种情况,但vector明显功能比string要更健壮一些,string类型只能针对于字符,而vector在使用resize进行初始化空间数据时,对内置类型和自定义类型均可以调用对应的拷贝构造来初始化,所以其功能更为健壮,默认将整型类型初始化为0,指针类型初始化为空指针。

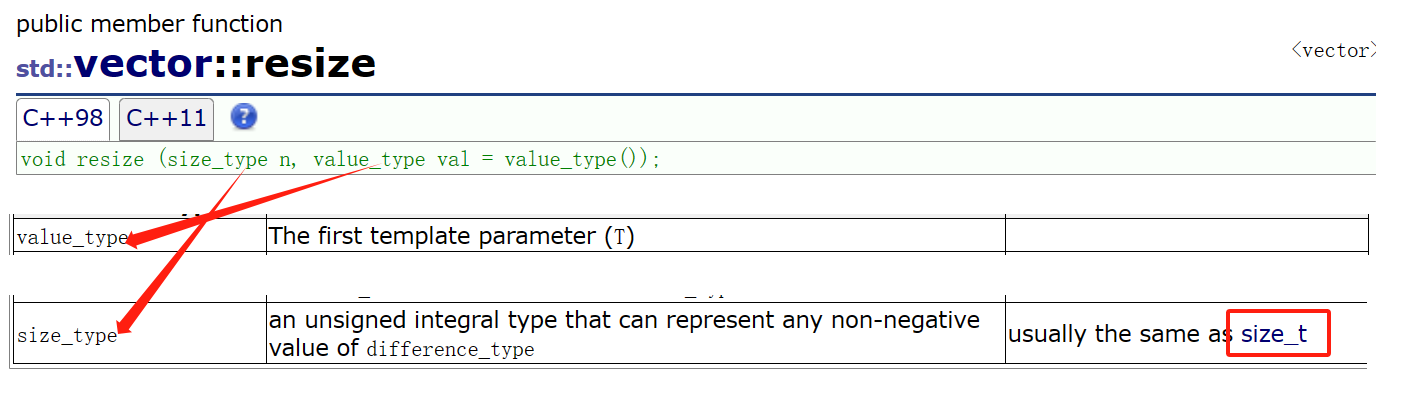
4. 缺省值为T(),T的匿名对象。T有可能是自定义类型或者内质类型,可以认为内置类型有构造函数,编译器会特殊处理
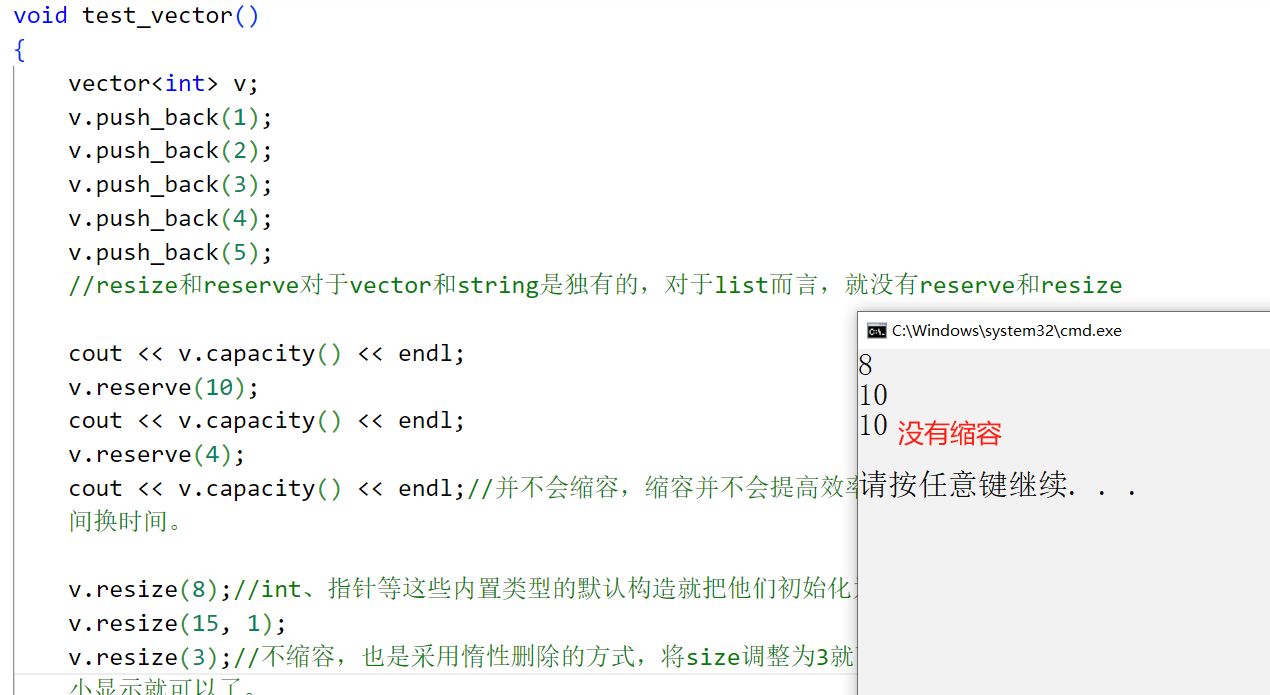
void test_vector()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
//resize和reserve对于vector和string是独有的,对于list而言,就没有reserve和resize
cout << v.capacity() << endl;
v.reserve(10);
cout << v.capacity() << endl;
v.reserve(4);
cout << v.capacity() << endl;//并不会缩容,缩容并不会提高效率,缩容是有代价的,某种程度上就是以空间换时间。
v.resize(8);//int、指针等这些内置类型的默认构造就把他们初始化为0和空指针这些。
v.resize(15, 1);
v.resize(3);//不缩容,也是采用惰性删除的方式,将size调整为3就可以了,显示数组内容的时候按照size大小显示就可以了。
}
3.2 reserve的扩容机制
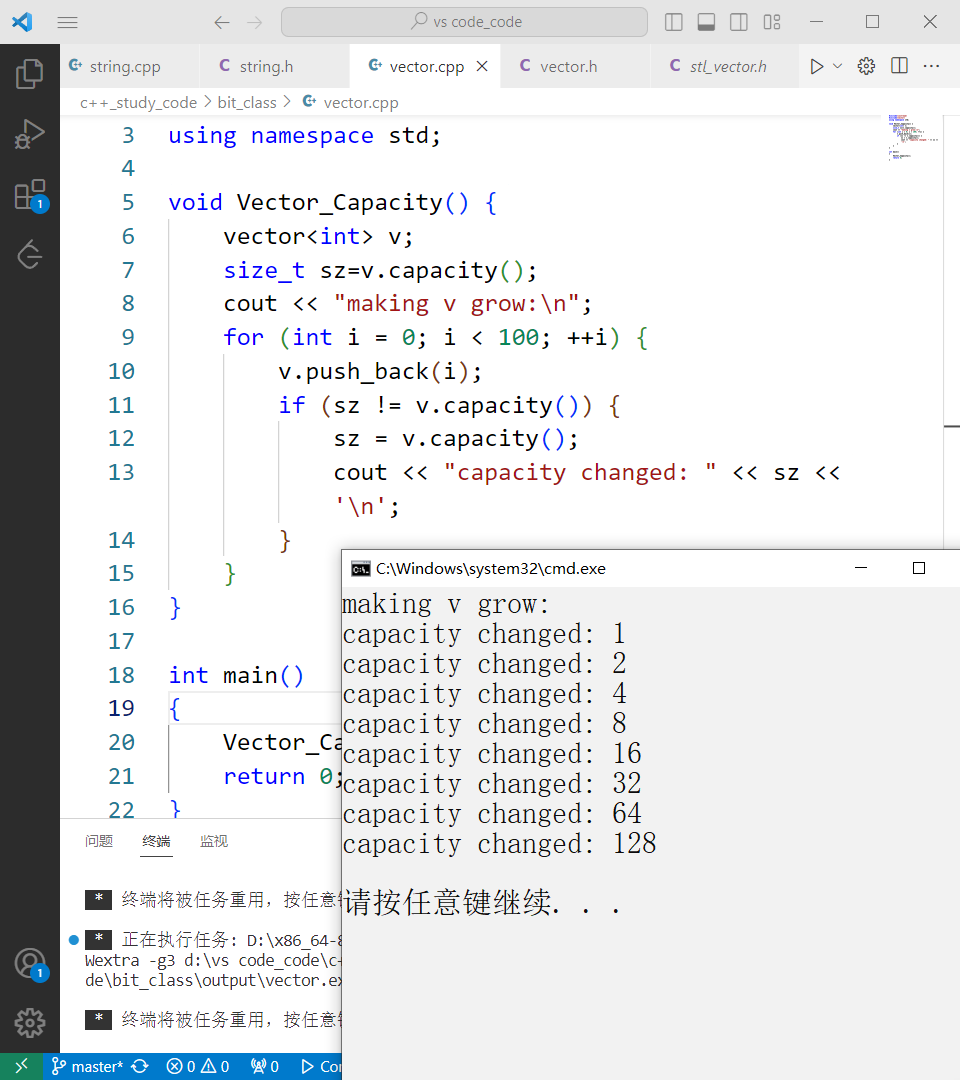
vector 的扩容机制和 string 的扩容机制是一样的,因为它们都是动态增长的数组:我的VSCode 下大概是 2倍扩容 ,Linux g++ 下是标准的二倍扩容,测试用例如下:
void Vector_Capacity() {
vector<int> v;
size_t sz=v.capacity();
cout << "making v grow:\n";
for (int i = 0; i < 100; ++i) {
v.push_back(i);
if (sz != v.capacity()) {
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
3.3 vector和malloc分别实现动态开辟的二维数组
118. 杨辉三角 - 力扣(LeetCode)
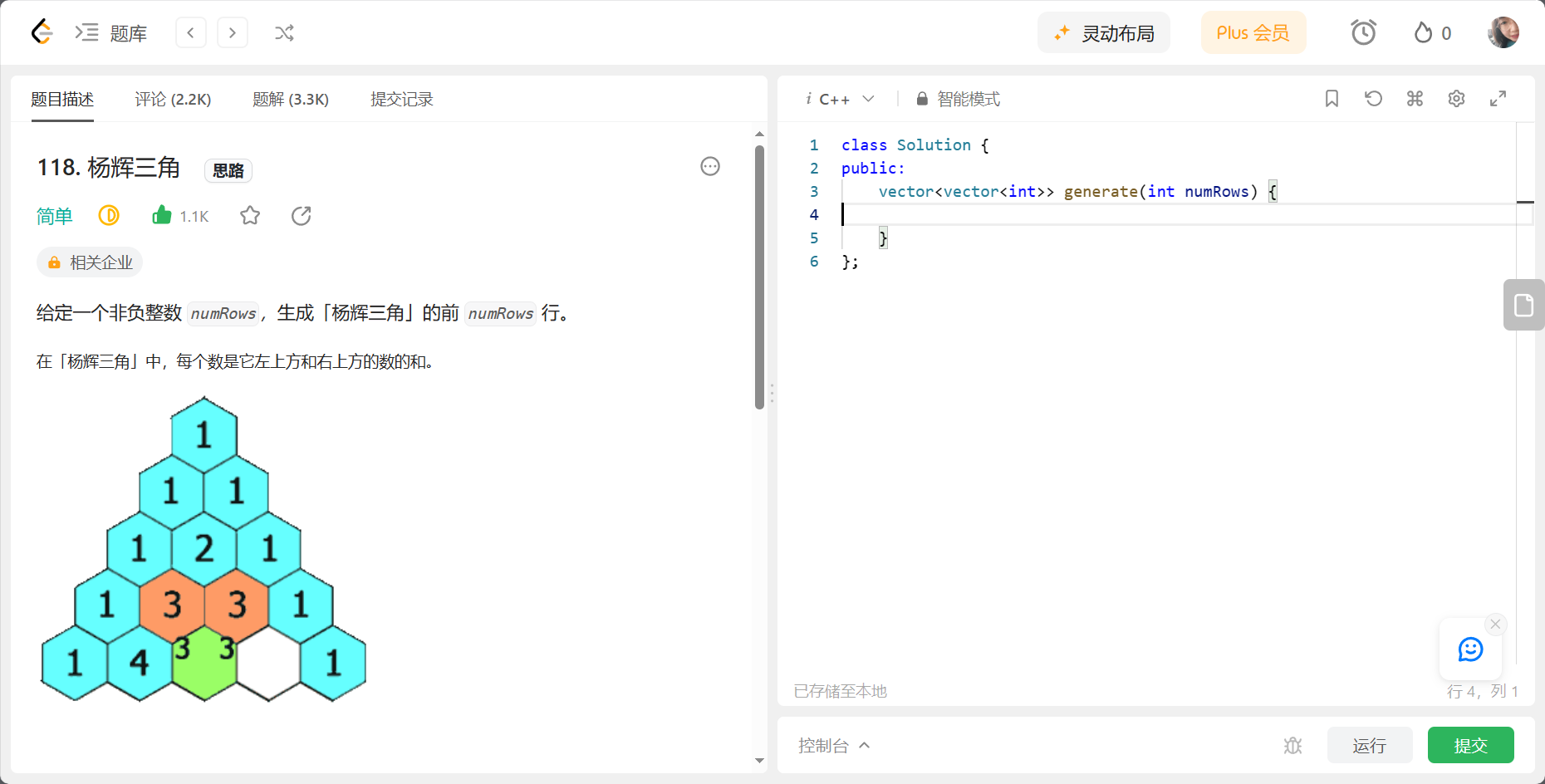
对于vector来讲的话,动态开辟就不需要我们自己做,通过resize就可以控制容器的空间大小,不用malloc动态开辟了,所以对于动态开辟的二维数组来讲,vector实际上要简便许多
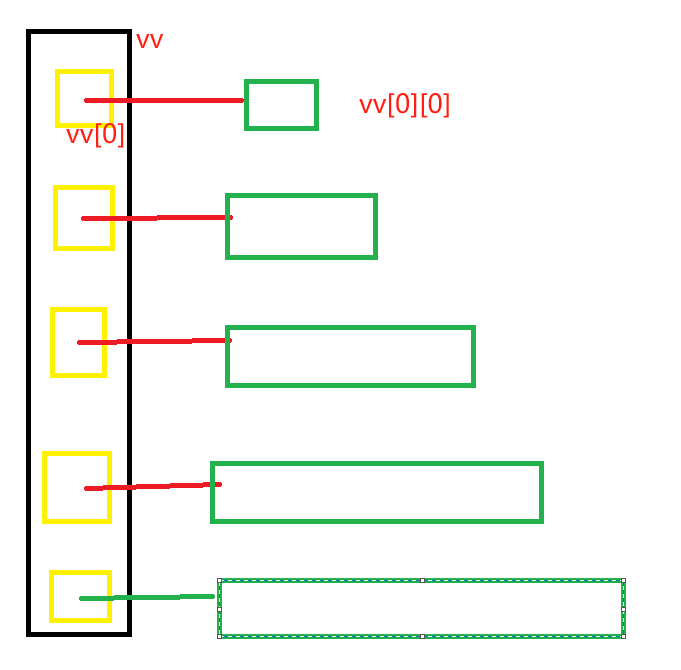
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> vv;
vv.resize(numRows);
//第二个参数不传就是匿名对象,会自动调用容器中元素的构造函数。内置类型或自定义类型的构造。
for(size_t i=0; i<vv.size(); i++)
{
vv[i].resize(i+1, 0);//给每一个vector<int>容器预留好空间并进行初始化
vv[i][0] = vv[i][vv[i].size() - 1] = 1;
}
for(int i=0; i<vv.size(); i++)
{
for(int j=0; j<vv[i].size(); j++)
{
if(vv[i][j]==0)
{
vv[i][j]=vv[i-1][j]+vv[i-1][j-1];
}
}
}
return vv;
}
};
四、三种遍历方式
4.1operator[ ]对于越界访问的检查机制(一段经典的代码错误)
下面所展示的代码是比较经典的错误,就是我们用reserve扩容之后,就利用[ ]和下标来进行容器元素的访问(这是错误的),扩容之后空间的使用权确实属于我们,但是operator[ ]的越界访问检查机制,导致了我们程序的崩溃,assert(pos<size),所以对于元素的访问,是要用resize来进行size的调整的,而reserve的主要作用是用来提前预留空间,在空间不够使用的情况下进行调用,所
以这里使用的情景有些不搭。
4.2三种遍历方式
for (size_t i = 0; i < v.size(); ++i)
{
cout << v[i] << " ";
}
cout << endl; vector<int>::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl; for (auto e : v)
{
cout << e << " ";
}
cout << endl;五、vector的修改操作
5.1 assign和迭代器的配合使用

1. assign有两种使用方式
一种是用n个value来进行容器元素的覆盖
一种是用迭代器区间的元素来进行容器元素的覆盖,这里的迭代器采用模板形式,因为迭代器类型不仅仅可能是vector类型,也有可能是其他容器类型,所以这里采用模板泛型的方式
2. 其实迭代器使用起来实际是非常方便的,由于vector的底层是连续的顺序表,所以我们可以通过指针±整数的方式来控制迭代器赋值的区间,所以采用迭代器作为参数是非常灵活的
void test_vector5()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
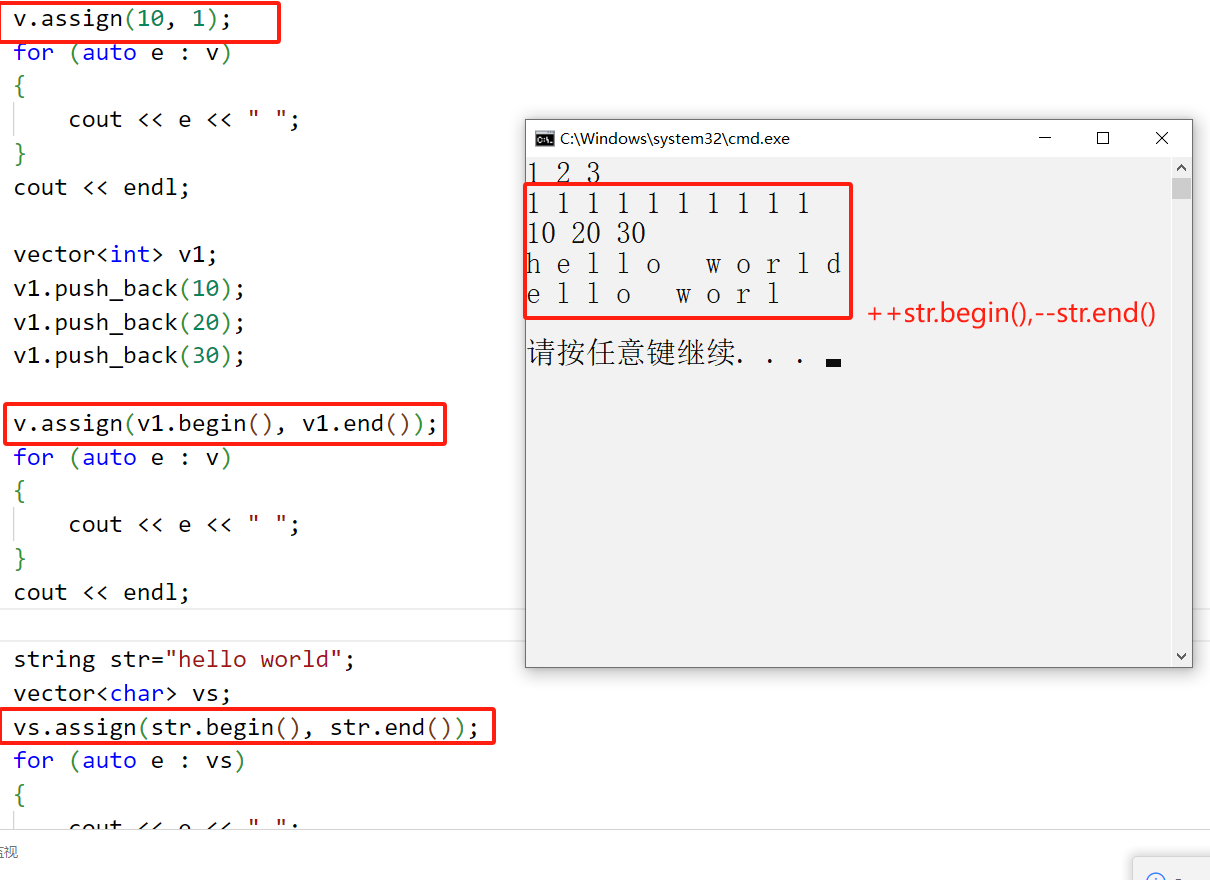
v.assign(10, 1);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
vector<int> v1;
v1.push_back(10);
v1.push_back(20);
v1.push_back(30);
v.assign(v1.begin(), v1.end());
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
string str="hello world";
vector<char> vs;
vs.assign(str.begin(), str.end());
for (auto e : vs)
{
cout << e << " ";
}
cout << endl;
vs.assign(++str.begin(), --str.end());
for (auto e : vs)
{
cout << e << " ";
}
cout << endl;
}
5.2 insert和find(vector库中没有find)的配合使用
const value_type 就是const T

为什么find要使用左闭右开? (我认为有四点原因)

4. 迭代器的end()也是指向最后一个元素的下一个位置,也是左闭右开
好的,我们继续回归正题
1. 对于顺序表这种结构来说,头插和头删的效率是非常低的,所以vector只提供push_back和pop_back,而难免遇到头插和头删的情况时,可以偶尔使用insert和erase来进行头插和头删,并且insert和erase的参数都使用了迭代器类型作为参数,因为迭代器更具有普适性
2. 如果要在vector的某个元素位置(在1,2等等具体位置插入倒也不需要find)进行插入时,肯定是需要使用 find接口 的,但其实vector的默认成员函数并没有find接口,这是为什么呢?因为大多数的容器都会用到查找接口,也就是find,所以C++直接将这个接口放到算法库里面去了,实现一个函数模板,这个函数的实现实际也比较简单,只要遍历一遍迭代器然后返回对应位置的迭代器即可,所以这个函数不单独作为某个类的成员函数,而是直接放到了算法库里面去。所以得加头文件

inset && find例子:
例子一:
使用 iterator insert (iterator position, const value_type& val) 插入单个元素:
#include <iostream>
#include <vector>
int main() {
std::vector<int> myVector = {1, 2, 4, 5};
std::vector<int>::iterator it = myVector.begin() + 2; // 指向位置 4 的迭代器
myVector.insert(it, 3); // 在位置 4 插入元素 3
for (int num : myVector) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
例子二:
使用 void insert (iterator position, size_type n, const value_type& val) 插入多个相同的元素:
#include <iostream>
#include <vector>
int main() {
std::vector<int> myVector = {1, 2, 5};
std::vector<int>::iterator it = myVector.begin() + 2; // 指向位置 5 的迭代器
myVector.insert(it, 3, 4); // 在位置 5 插入 3 个元素值为 4 的元素
for (int num : myVector) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
例子三:
使用 template <class InputIterator> void insert (iterator position, InputIterator first, InputIterator last) 插入一个范围内的元素:
#include <iostream>
#include <vector>
#include <iterator>
int main() {
std::vector<int> myVector = {1, 2, 7};
std::vector<int> newElements = {3, 4, 5};
std::vector<int>::iterator it = myVector.begin() + 2; // 指向位置 7 的迭代器
// 在位置 7 插入 newElements 中的所有元素
myVector.insert(it, newElements.begin(), newElements.end());
for (int num : myVector) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
例子四:(这个是知识点覆盖最多的)
利用 find 找到元素位置 并且插入
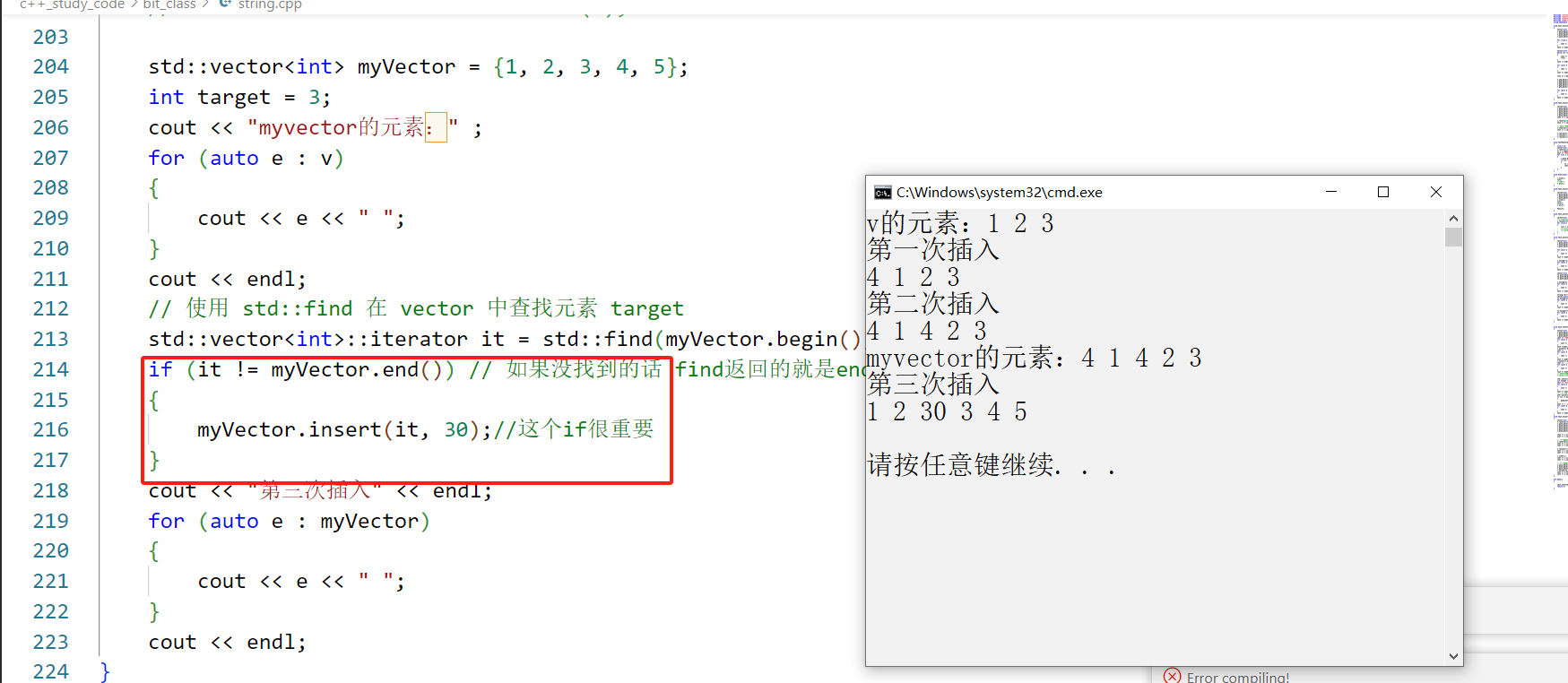
void test_vector6()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
cout << "v的元素:" ;
for (auto e : v)
{
cout << e << " ";
}
cout <<endl;
v.insert(v.begin(), 4);
cout << "第一次插入" << endl;
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
v.insert(v.begin()+2, 4);
cout << "第二次插入" << endl;
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
// 没有find成员
//vector<int>::iterator it = v.find(3);
std::vector<int> myVector = {1, 2, 3, 4, 5};
int target = 3;
cout << "myvector的元素:" ;
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
// 使用 std::find 在 vector 中查找元素 target
std::vector<int>::iterator it = std::find(myVector.begin(), myVector.end(), target);
if (it != myVector.end()) // 如果没找到的话 find返回的就是end 也就是元素的下一个位置
{
myVector.insert(it, 30);//这个if很重要
}
cout << "第三次插入" << endl;
for (auto e : myVector)
{
cout << e << " ";
}
cout << endl;
}
5.3 类外、类内、算法库的3个swap(编译器费心良苦)
vector类内的swap用于两个对象的交换,在swap实现里面再调用std的swap进行内置类型的交换,但C++用心良苦,如果你不小心使用的格式是std里面的swap格式的话,也没有关系,因为类外面有一个匹配vector的swap,所以会优先调用类外的swap,C++极力不想让你调用算法库的swap,就是因为如果交换的类型是自定义类型的情况下,算法库的swap会进行三次深拷贝,代价极大,所以为了极力防止你调用算法库的swap,C++不仅在类内定义了swap,在类外也定义了已经实例化好的swap,调用时会优先调用最匹配的swap。
void test_vector8()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
vector<int> v1;
v1.swap(v);
swap(v1, v);//一不小心这样用呢?那也不会去调用算法库里面的三次深拷贝的swap
//这里会优先匹配vector的类外成员函数,既然有vector作为类型实例化出来的swap函数模板,就没有必要调用算法库里面的模板进行实例化
//template <class T, class Alloc>
//void swap(vector<T, Alloc>&x, vector<T, Alloc>&y);
}
六、看源码时需要注意的问题
1. 看源码框架的方法:将类成员变量先抽出来,看一看成员函数的声明具体都实现了什么功能,如果想要看实现,那就去.c文件抽出来具体函数去看
2. 看某些书籍时的道理和看源码是一样的,要进行抽丝剥茧,不要想着第一遍就把看到的所有东西都弄回,如果你觉得这本书或源码非常不错,你可以多次反复的去看,要循序渐进的去学,一段时间之后,你的知识储备上来之后,可能再去看书籍或者源码又有新的不同的感受,所以不要想着一遍就把所有的东西都搞明白,第一遍弄懂个70%-80%就很不错,如果你想学扎实一点,那就增加遍数。
希望对大家有所帮助!!
祝大家中秋快乐!!
- 程序开发学习排行
- 最近发表