

使用LDA(线性判别公式)进行iris鸢尾花的分类
作者:小教学发布时间:2023-09-30分类:程序开发学习浏览:303
导读: 线性判别分析((LinearDiscriminantAnalysis,简称LDA)是一种经典的线性学习方法,在二分类问题上因为最早由[Fisher,193...
线性判别分析((Linear Discriminant Analysis ,简称 LDA)是一种经典的线性学习方法,在二分类问题上因为最早由 [Fisher,1936] 提出,亦称 ”Fisher 判别分析“。并且LDA也是一种监督学习的降维技术,也就是说它的数据集的每个样本都有类别输出。这点与主成分和因子分析不同,因为它们是不考虑样本类别的无监督降维技术。
LDA 的思想非常朴素:给定训练样例集,设法将样例投影到一条直线上,使得同样样例的投影尽可能接近、异样样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。其实可以用一句话概括:就是“投影后类内方差最小,类间方差最大”。
鸢尾花简介
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表。
通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。
iris的每个样本都包含了品种信息,即目标属性(第5列,也叫target或label)。
代码
#首先导入相关库
import sklearn
from sklearn.datasets import load_iris
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt#再进行数据的划分
data = load_iris(return_X_y=True)
x,y = data
#print(x)
#print(y)
#分割训练集和测试集
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.3)
print(train_x.shape)
print(test_x.shape)#进行训练
LDA = LinearDiscriminantAnalysis()
LDA.fit(train_x,train_y)
y_predict = LDA.predict(test_x)
print(test_y)
print(y_predict)相关输出如下
[2 1 2 1 0 2 2 0 2 0 1 2 1 0 1 0 0 0 0 2 2 1 2 1 0 1 1 2 2 0 2 1 2 0 2 1 2 1 0 2 0 0 1 0 2] [2 1 2 1 0 2 2 0 2 0 1 2 1 0 1 0 0 0 0 2 2 1 2 1 0 1 1 2 2 0 2 1 2 0 2 1 2 1 0 2 0 0 1 0 2]
#计算预测正确率
j = 0
for i in range(len(test_y)):
if test_y[i] == y_predict[i]:
j = j + 1
print(j)
print(j/len(y_predict))画图部分
#由于是按照萼片长度宽度计算,所以将萼片长宽与相应的类别组合成新的列表
total_sepal = []
for i in range(x.shape[0]):
sepal = []
sepal.append(x[i][0])
sepal.append(x[i][1])
sepal.append(y[i])
total_sepal.append(sepal)
print(total_sepal)#画图
for i in range(x.shape[0]):
if(total_sepal[i][2] == 0):
plt.scatter(total_sepal[i][0], total_sepal[i][1], color='blue')
if(total_sepal[i][2] == 1):
plt.scatter(total_sepal[i][0], total_sepal[i][1], color='red')
if(total_sepal[i][2] == 2):
plt.scatter(total_sepal[i][0], total_sepal[i][1], color='green')
plt.show()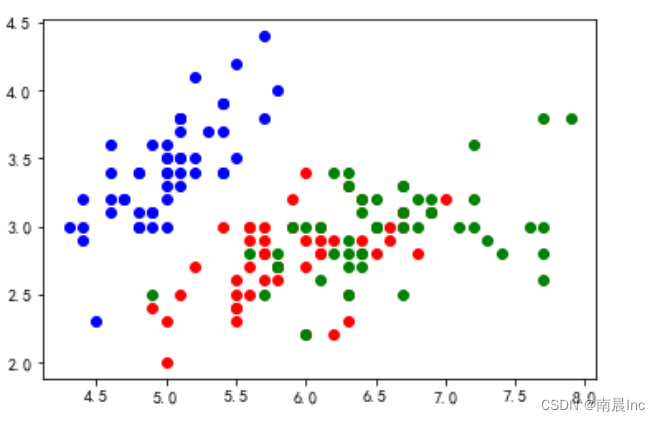
- 上一篇:(自学)黑客技术——网络安全
- 下一篇:有趣的HTML实例(二) 404页面
- 程序开发学习排行
- 最近发表