

python爬虫
作者:小教学发布时间:2023-09-28分类:程序开发学习浏览:251
导读:文章目录python爬虫内容爬取图片视频爬取反爬1.UA限制2.cookie限制get请求post请求3.登录限制默认跳转登录从而改变编码格式报错代理爬虫pyt...
文章目录
- python爬虫
- 内容爬取
- 图片视频爬取
- 反爬
- 1.UA限制
- 2.cookie限制
- get请求
- post请求
- 3.登录限制
- 默认跳转登录从而改变编码格式报错
- 代理爬虫
python爬虫
内容爬取
# 使用urllib获取百度首页的源码
import urllib.request
# 定义一个url 就是你要访问的地址
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
res = urllib.request.urlopen(url)
# content = res.read().decode('UTF-8') # 字节读取
# content = res.readline() # 一行读取
# content = res.readlines() # 一行读取
# content = res.getcode() # 获取状态码
# content = res.geturl() # 获取url地址
content = res.getheaders() # 获取状态信息
print(content)
图片视频爬取
# 使用urllib获取百度首页的源码
import urllib.request
# 定义一个url 就是你要访问的地址
url = 'https://pgcvideo-cdn.xiaodutv.com/836196053_1223069277_20230809121211.mp4?Cache-Control%3Dmax-age-8640000%26responseExpires%3DFri%2C_17_Nov_2023_12%3A12%3A17_GMT=&xcode=dd2ab39d66fa138ab8491471cb346773b64113c4b03ef0dc&time=1692603730&sign=1692517330-7367210-0-881eb771dc237543a8dbe7750b3f3308&_=1692518165830'
# 模拟浏览器向服务器发送请求
res = urllib.request.urlretrieve(url,'test1.mp4') # urlretrieve文件读取写入
反爬
1.UA限制
因为https安全协议的问题浏览器是需要识别请求的ua里面包括主机的一些版本浏览器型号等等信息,因此我们需要自己定制ua对象
# 使用urllib获取百度首页的源码
import urllib.request
# 定义一个url 就是你要访问的地址
url = 'https://www.baidu.com'
# 模拟浏览器向服务器发送请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
# 请求对象的定制 参数顺序问题 所以要关键字传参
resquset=urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(resquset)
content = res.read().decode('UTF-8') # 字节读取
print(content)
2.cookie限制
如果没有cookie就会返回安全限制
- parse.quote get请求 可以进行urlcode编码解析
- parse.urlencode 可以进行多参数解析
get请求
# 使用urllib获取百度首页的源码
from urllib import request,parse
# 定义一个url 就是你要访问的地址
url = 'https://www.baidu.com/s?wd='
# 模拟浏览器向服务器发送请求
headers = {
'cookie':'找到网页的cookie'
, 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
name =parse.quote('周杰伦')
data ={
'wd':'周杰伦',
'sex':'男'
}
data= parse.urlencode(data)
print(data) # wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7
# 请求对象的定制 参数顺序问题 所以要关键字传参
resquset=request.Request(url=url+name,headers=headers)
#
#
res =request.urlopen(resquset)
content = res.read().decode('UTF-8') # 字节读取
#
print(content)
post请求
# 使用urllib获取百度首页的源码
from urllib import request,parse
import json
# 定义一个url 就是你要访问的地址
url = 'https://fanyi.baidu.com/sug'
# 模拟浏览器向服务器发送请求
headers = {
'cookie':'自己找cookie'
, 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
data ={
'kw':'spider'
}
# post请求的参数 必须要进行编码
data= parse.urlencode(data).encode('utf8')
# post 请求参数是不会拼接在url后面的,二十需要放在请i求对象定制的参数中
resquset=request.Request(url=url,data=data,headers=headers)
res =request.urlopen(resquset)
content = res.read().decode('UTF-8') # 字节读取
# #
content =json.loads(content)
print(content)
3.登录限制
默认跳转登录从而改变编码格式报错
因为请求头信息不够所以默认跳转登录页,但是你使用查看原代码发现登录页的编码格式是gb2312,而其他页面是utf-8,从而在爬取错误的时候报错
import urllib.request
url ='https://weibo.cn/2729916174/info'
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
request=urllib.request.Request(url=url,headers=headers)
res =urllib.request.urlopen(request)
content =res.read().decode('gb2312')
with open('weibo.html','w',encoding='gb2312') as fp:
fp.write(content)
解决爬虫的编码格式问题
import urllib.request
import gzip
url ='https://weibo.cn/2729916174/info'
headers={
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "max-age=0",
"cookie": "_T_WM=76caf7ab034b9dba07601b3736024a7b; MLOGIN=1; SUB=_2A25J5lXwDeRhGeRJ6VsY8SjNzDiIHXVrKXu4rDV6PUJbktCOLVPakW1NUqR0rBdaF-2YB0D2HAdRv13oOnOQiFjV; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFiz3dyyc0uRYM1g_5vvCZc5NHD95QES0z41K2ceKMXWs4DqcjMi--NiK.Xi-2Ri--ciKnRi-zNdoyEU0.RIGi497tt; SSOLoginState=1692542368",
"referer": "https://passport.weibo.cn/",
"sec-ch-ua": '"Chromium";v="110", "Not A(Brand";v="24", "Google Chrome";v="110"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "Windows",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-site",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}
request=urllib.request.Request(url=url,headers=headers)
res =urllib.request.urlopen(request)
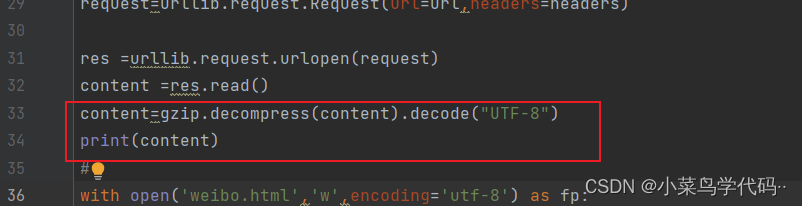
content =res.read()
content=gzip.decompress(content).decode("UTF-8")
#
with open('weibo.html','w',encoding='utf-8') as fp:
fp.write(content)
这里解释两点
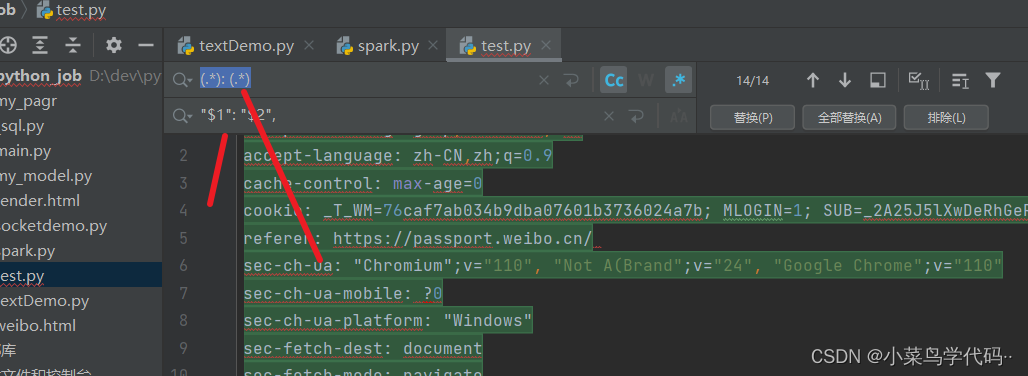
- 1.借助python内部给请求头加双引号跟逗号,随便创建一个文件 ctrl+r (.): (.),“$1”: “$2”,,全部替换
- 由于编码格式问题我这边请求一直请求不成功有的甚至跳转到令牌那页,然后我这边借助gzip 压缩包进行解压重新编码
代理爬虫
解决问题:解决的是防止一个ip多次访问被禁了
遇到问题:刚访问的时候发现可能是返回百度安全验证,这大部分都是因为cookie没带,所以在请求头中把cookie带上问题就基本解决了
import urllib.request
url = 'http://www.baidu.com/s?wd=ip'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
# 'Cookie': 'cookie'
}
# auth = urllib.request.HTTPBasicAuthHandler() # 生成作者
proxies={
# 'auth':auth,
'http':'125.125.224.215:17507'
}
request = urllib.request.Request(url=url, headers=headers)
handler=urllib.request.ProxyHandler(proxies=proxies)
opener=urllib.request.build_opener(handler)
res=opener.open(request)
content = res.read().decode("utf-8")
with open('daili.html', 'w', encoding='utf-8') as fp:
fp.write(content)
未完待续。。。。。。。。
- 程序开发学习排行
- 最近发表