

【无标题】
作者:小教学发布时间:2023-09-25分类:程序开发学习浏览:267
文章目录
- 1 测定预测精度的方法
- 2 组合模型
-
- 2.1 模式一:线性组合模型
- 2.2 模式二:最优线性组合模型
- 2.3 模式三:贝叶斯组合模型
\[ M E = \frac{\sum\limits_{i=1}^n (y_i - \hat{y}_i)}{n} \]
1 测定预测精度的方法
- 平均误差
M E = ∑ i = 1 n ( y i − y ^ i ) n ME=\frac{\sum\limits_{i=1}^n{\left( y_i-\hat{y}_i \right)}}{n}ME=ni=1∑n(yi−y^i)
-
平均绝对误差
M A D = ∑ i = 1 n ∣ y i − y ^ i ∣ n MAD=\frac{\sum\limits_{i=1}^n{\left| y_i-\hat{y}_i \right|}}{n}MAD=ni=1∑n∣yi−y^i∣ -
平均相对误差
M P E = 1 n ∑ i = 1 n y i − y ^ i y i MPE=\frac{1}{n}\sum\limits_{i=1}^n{\frac{y_i-\hat{y}_i}{y_i}}MPE=n1i=1∑nyiyi−y^i -
平均相对误差绝对值
M A P E = 1 n ∑ i = 1 n ∣ y i − y ^ i y i ∣ MAPE=\frac{1}{n}\sum\limits_{i=1}^n{\left| \frac{y_i-\hat{y}_i}{y_i} \right|}MAPE=n1i=1∑n∣∣∣∣yiyi−y^i∣∣∣∣ -
预测误差的方差(均方误差)
均方误差MSE(Mean Squared Error)又被称为 L2范数损失 。
M S E = ∑ i = 1 n e i 2 n = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE=\frac{\sum\limits_{i=1}^n{e_i^2}}{n}=\frac{1}{n}\sum\limits_{i=1}^n{\text{(}y_i-\hat{y}_i}\text{)}^2MSE=ni=1∑nei2=n1i=1∑n(yi−y^i)2
由于MSE与我们的目标变量的量纲不一致,为了保证量纲一致性,我们需要对MSE进行开方 。 -
预测误差的标准差(均方根误差,又叫标准误差)
R M S E = ∑ i = 1 n e i 2 n = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 RMSE=\sqrt{\frac{\sum\limits_{i=1}^n{e_i^2}}{n}}=\sqrt{\frac{1}{n}\sum\limits_{i=1}^n{\text{(}y_i-\hat{y}_i}\text{)}^2}RMSE=ni=1∑nei2=n1i=1∑n(yi−y^i)2
2 组合模型
组合预测就是设法把不同的预测模型组合起来,综合利用各种预测方法所提供的信息,以适当的加权平均形式得出组合预测模型。
虽然单项经济预测方法在经济预测中仍占据主导地位,但是各种单项预测模型都有自己的假设前提、特点和适用场合。
例如
- 经典线性回归模型要求变量之间线性关系显著,对于出现数据序列相关、异方差性、多重共线性等要进一步讨论。
- 灰色系统模型虽然要求的数据序列较短,但是用于GM(1,1)建模的原始序列 X 0 X^0X0 需要一定的前提条件:一是非负序列,二是等时距,同时生成数据序列满足指数规律。
鉴于不同的单项预测模型利用的样本数据不尽相同,它们从不同的角度提供各个方面有用的信息,各有优点和缺点。
在得到多个独立预测模型的研究结果后,寻找既基于这些单项预测模型的结果,又能够博采众长,从而得到更好效果的组合预测模型。
单项预测模型
-
线性回归模型(以前记过的笔记)
-
灰色预测模型(以前记过的笔记)
-
时间序列模型(以前记过的笔记)
-
BP神经网络(以前记过的笔记)
-
参考文献中的GABP神经网络模型
2.1 模式一:线性组合模型
预测的关键是建立合理的预测模型。不同的预测模型各有长处,通过对不同预测模型的线性组合可以得到效果更好的线性组合预测模型。
形式如下:
y ^ t = ω 1 y 1 ( t ) + ω 2 y 2 ( t ) + . . . + ω m y m ( t ) \hat{y}_t=\omega _1y_{1\left( t \right)}+\omega _2y_{2\left( t \right)}+...+\omega _my_{m\left( t \right)}y^t=ω1y1(t)+ω2y2(t)+...+ωmym(t)
式中,i = 1 , 2 , ⋯ , m ; t = 1 , 2 , ⋯ , n i=1,2,\cdots ,m\text{ ;}t=1,2,\cdots ,ni=1,2,⋯,m ;t=1,2,⋯,n
-
y ^ t \hat{y}_ty^t 为 t 时刻的组合预测值;
-
y i ( t ) y_{i(t)}yi(t) 为第 i 个预测模型在 t 时刻的预测值;
-
y ( t ) y_{(t)}y(t) 为一预测对象某个指标实际值序列
-
e i t = y ( t ) − y i ( t ) e_{it}=y_{\left( t \right)}-y_{i\left( t \right)}eit=y(t)−yi(t) 第 i 个预测模型在第 t 时刻的预测误差;
-
e t = y ( t ) − y ^ t , t = 1 , 2 , ⋯ , n e_t=y_{\left( t \right)}-\hat{y}_t\ \text{,}t=1,2,\cdots ,net=y(t)−y^t ,t=1,2,⋯,n 在 t 时刻线性组合模型的预测误差;
-
W = ( ω 1 , ω 2 , ⋯ , ω m ) T W=\left( \omega _1,\omega _2,\cdots ,\omega _m \right) ^TW=(ω1,ω2,⋯,ωm)T 为 m 个预测模型线性组合的加权系数,且满足 ω 1 + ω 2 + ⋯ + ω m = 1 \omega _1+\omega _2+\cdots +\omega _m=1ω1+ω2+⋯+ωm=1 和 ω i ≥ 0 \omega _i\ge 0ωi≥0
线性组合预测模型的关键在于确定合理的权数 ω i \omega_iωi,使得预测模型更加有效地提高预测精度。 一种合理的方法是可以依据误差平方和(SSE)最小原则来加以确定。
即
S S E = ∑ t = 1 n e t 2 = ∑ t = 1 n ( ∑ i = 1 m ω i e i t ) 2 = W T E W SSE=\sum_{t=1}^n{e_{t}^{2}}=\sum_{t=1}^n{\left( \sum_{i=1}^m{\omega _ie_{it}} \right) ^2=W^TEW}SSE=t=1∑net2=t=1∑n(i=1∑mωieit)2=WTEW
其中 E EE 为信息误差矩阵,E = ( e i t ) m × n ( e i t ) m × n T E=\left( e_{it} \right) _{m\times n}\left( e_{it} \right) _{m\times n}^TE=(eit)m×n(eit)m×nT,通过求解线性规划问题的最优解,得到最佳权系数 W 0 W_0W0。
即
{ min S S E = W T E W s . t . R m W = 1 , W ≥ 0 \left\{
min\ SSE=WTEWs.t. RmW=1 ,W≥0min\ ���=�����.�. ���=1 ,�≥0
\right.⎩⎨⎧min SSE=WTEWs.t. RmW=1 ,W≥0
⇒ W 0 = E − 1 R m T R m E − 1 R m T \Rightarrow W_0=\frac{E^{-1}R_{m}^{T}}{R_mE^{-1}R_{m}^{T}}⇒W0=RmE−1RmTE−1RmT
其中 R m R_mRm 为元素全为 1 的 m 维行向量,并且保证的非负最优加权系数可使得线性组合模型有效地提高预测精度。
例如,在参考文献中,已经得到每个单项模型的预测值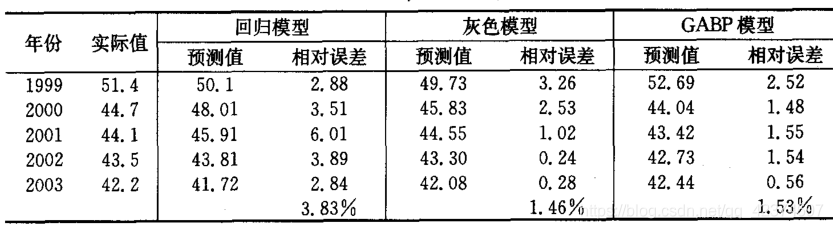
信息误差矩阵

16.2487 = (51.4-50.1)(51.4-50.1)+(44.7-48.01)(44.7-48.01)+…
通过公式
W 0 = E − 1 R m T R m E − 1 R m T W_0=\frac{E^{-1}R_{m}^{T}}{R_mE^{-1}R_{m}^{T}}W0=RmE−1RmTE−1RmT
得到线性组合模型最优加权系数
W 0 = ( 0.0323 , 0.4160 , 0.5517 ) T W_0=\left( 0.0323,0.4160,0.5517 \right) ^TW0=(0.0323,0.4160,0.5517)T
从而得到线性组合模型
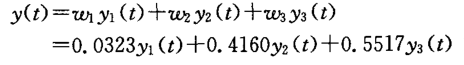
可以得到组合模型预测值
如下表中组合模型第一个预测值
51.37 = 0.032350.1+0.416049.73+0.5517*52.69
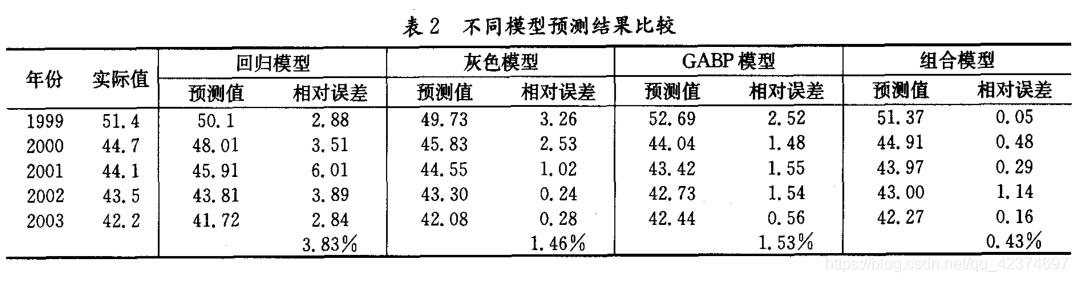
通过比较模型的相对误差,可以判断模型的预测精度。
2.2 模式二:最优线性组合模型
原理:利用样本期的实际值和各单项预测模型的拟合值,进行线性回归,然后利用线性回归模型,以原方案的预测值作为外生变量进行外推预测。
最优线性组合模型的一般形式为:
y t = a + b 1 y 1 t + . . . + b n y n t y_t=a+b_1y_{1t}+...+b_ny_{nt}yt=a+b1y1t+...+bnynt
- y t y_tyt 为样本期实际值;
- y 1 t , y 2 t , . . . , y n t y_{1t},y_{2t},...,y_{nt}y1t,y2t,...,ynt 为样本期n个不同模型得到的预测值。
最优线性模型是广义的线性组合预测模型,其特点在于组合权数由线性回归得到。
2.3 模式三:贝叶斯组合模型
贝叶斯组合模型是线性组合模型的特例
在 n 种单项预测模型中选择一种为主要方案,由这一方案得出的预测值为原预测值。然后,取其他 n-1 种预测方案在某一时点上的预测值分布的均值和方差,代入下面公式,就得到贝叶斯组合模型。
Y ^ t + 1 = ( Y t + 1 / s y , t + 1 2 + Y ˉ t + 1 / s y ˉ , t + 1 2 ) / ( 1 s y , t + 1 2 + 1 s y ˉ , t + 1 2 ) \hat{Y}_{t+1}=\left( Y_{t+1}/s_{_{y,\,t+1}}^{2}+\bar{Y}_{t+1}/s_{_{\bar{y},\,t+1}}^{2} \right) /\left( \frac{1}{s_{_{y,\,t+1}}^{2}}+\frac{1}{s_{_{\bar{y},\,t+1}}^{2}} \right)Y^t+1=(Yt+1/sy,t+12+Yˉt+1/syˉ,t+12)/(sy,t+121+syˉ,t+121)
-
Y ^ t + 1 \hat{Y}_{t+1}Y^t+1 为贝叶斯组合预测值;
-
Y t + 1 Y_{t+1}Yt+1 为原预测值;
-
Y ˉ t + 1 \bar{Y}_{t+1}Yˉt+1 为其他 n-1 种预测值分布的均值;
-
s y ˉ , t + 1 2 s_{_{\bar{y},\,t+1}}^{2}syˉ,t+12 为其他 n-1 种预测值分布的方差;
-
s y , t + 1 2 s_{_{y,\,t+1}}^{2}sy,t+12 为原预测值的方差。
参考文献:
《线性组合预测模型及其应用》
《统计预测与决策》
- 程序开发学习排行
- 最近发表