

排序算法:快速排序(三种排序方式、递归和非递归)
作者:小教学发布时间:2023-09-25分类:程序开发学习浏览:419
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关排序算法的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成!
C 语 言 专 栏:C语言:从入门到精通
数据结构专栏:数据结构
个 人 主 页 :stackY、

目录
前言:
1.快速排序
1.1递归版本
1.1.1hoare版本
代码演示:
1.1.2挖坑法
代码演示:
1.1.3前后指针(下标)版本
代码演示:
1.1.4时间复杂度
1.1.5快速排序的优化
优化完整代码:
1.2非递归版本
代码演示:
前言:
在前面的文章我们分别介绍了插入排序和选择排序,那么在本期的学习中我们来了解一下快速排序,以及快速排序的三种实现方式以及递归和非递归的实现,话不多说,正文开始:
快速排序和冒泡排序是属于交换排序这个范畴内的,冒泡排序在前面的文章中非常细致的讲解过,那么在这里就不做赘述,直接开始快速排序即可:
1.快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中 的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
1.1递归版本
首先我们使用递归的方式来实现快速排序,后面再使用非递归来完成,因为递归太深是会有风险的。在递归版本的快速排序下对于排序区间的划分有三种方法:1.hoare版本、2.挖坑法、3.前后指针法。那么我们来一一学习。
1.1.1hoare版本
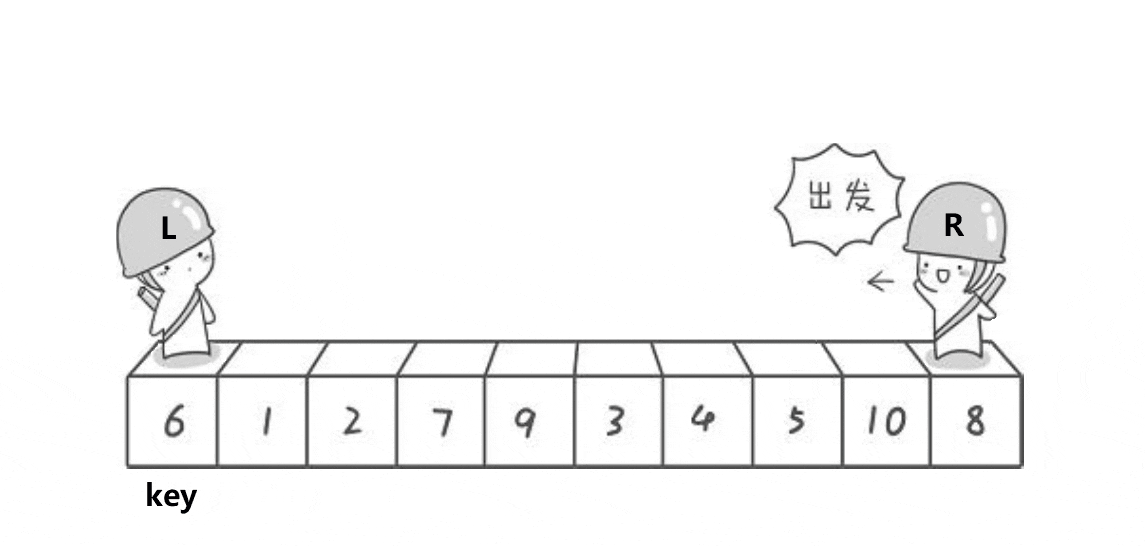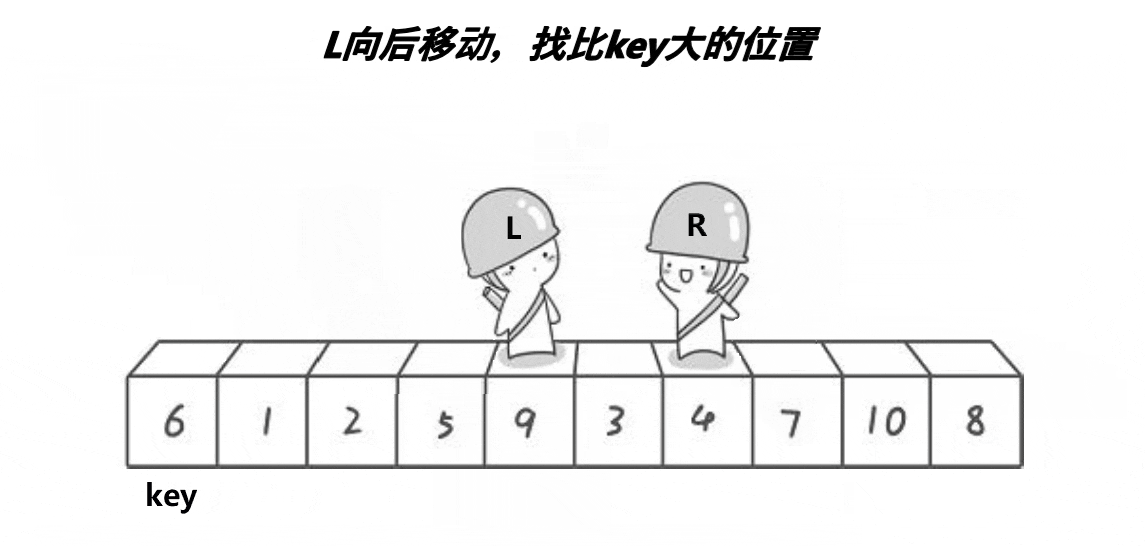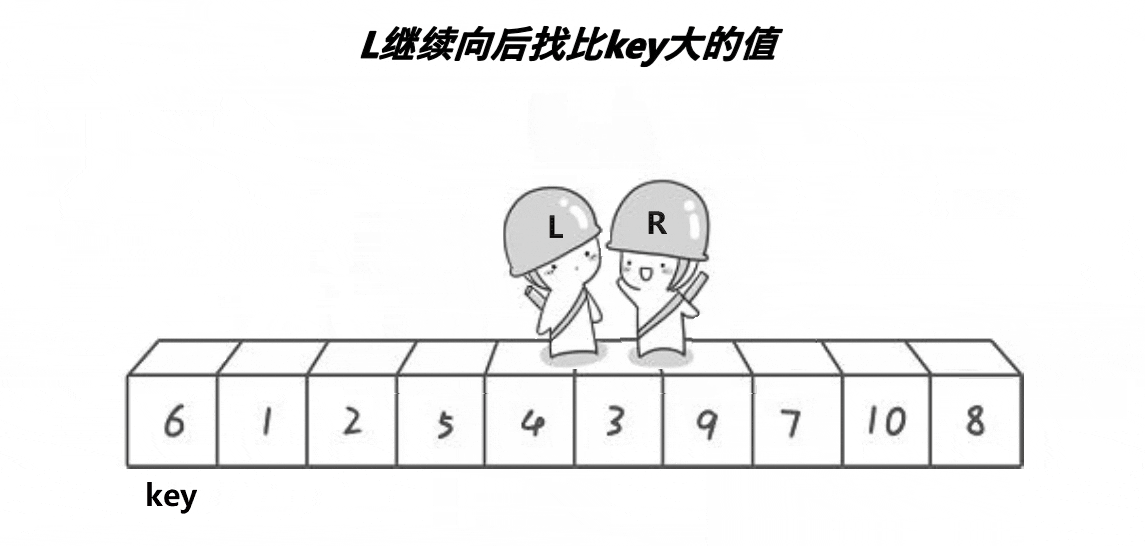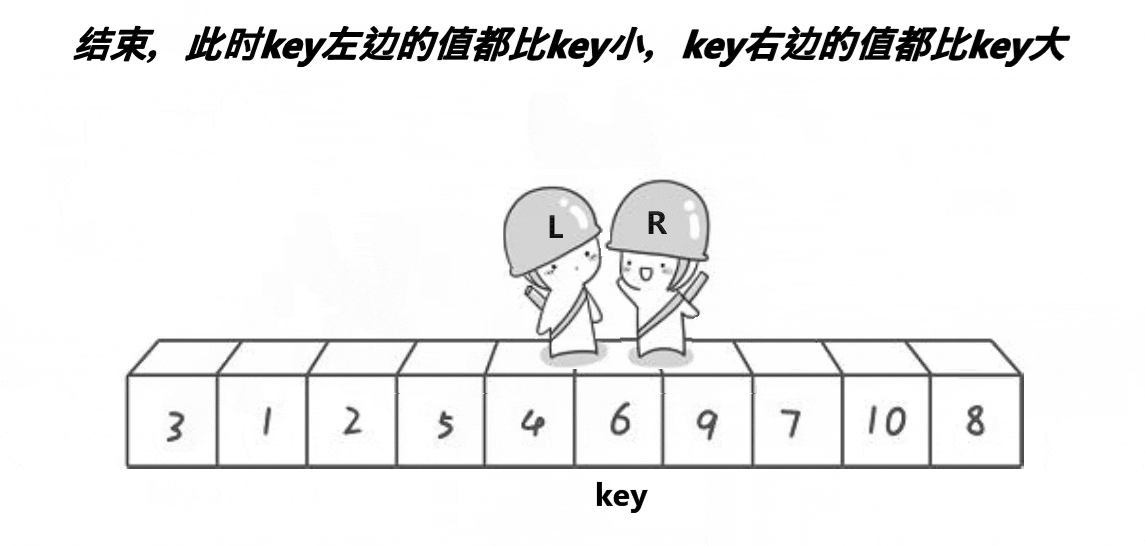
我们要对一段数据进行排升序的处理:首先我们取一个关键值key(基准值),那么我们一般取的是最左边或者最右边的数据,然后设置两个下标:左下标和右下标,左下标,进行一趟排序:左下标从左向右开始找比key大的,右下标从右向左找比key小的,然后左右下标的值交换,然后再重复此过程,当左右下标重叠时,将key与重叠位置的数据进行交换。一趟排序之后得到的结果就是key左边的都比key小,右边的都比key大,但是并不一定是有序,然后使用左右下标重合的位置将数据分为两个区间,然后再重复上述步骤,将这两个区间变为有序,那么左右区间都有序,数据的整体就有序了。
那么在这就存在几个问题:
1.怎么保证重叠位置的值就一定比key小呢?
2.怎么让左右区间变为有序?
1.怎么保证重叠位置的值就一定比key小呢?
我们可以先让右下标开始走,然后让左下标开始走,因为右下标找的是比key小的值,先让右下标找到比key小的值,当左下标找到比key大的值时,两个值交换,当左下标找不到比key大的值时,这时左下标肯定和右下标重合,这时重合的就是右下标找到的比key小的,这时交换即可达到重叠时的数据比key小。


2.怎么让左右区间变为有序?
通过一次排序让数据变为两个区间,那么这两个区间再分别进行一次排序,再将它分为若干个小区间,这若干个小区间再进行排序,直到分出的区间只剩一个值或者分出的区间不存在,这时就达到了有序,那么就需要使用递归来进行左右区间的排序,递归截止的条件就是区间不存在或者区间里面只有一个数据。
代码演示:
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 1. hoare版本
int PartSort1(int* a, int left, int right)
{
//设置关键字
int keyi = left;
while (left < right)
{
//右边先走
//找比key小的
while (left < right && a[keyi] <= a[right]) //先得判断下标是否合理
{
right--;
}
//找比key大的
while (left < right && a[keyi] >= a[left])
{
left++;
}
//交换
Swap(&a[left], &a[right]);
}
//交换重叠位置的数据和key
Swap(&a[keyi], &a[right]);
//将重叠位置返回
return right;
}
void QuickSort(int* a, int begin, int end)
{
//递归截止条件
if (begin >= end)
{
return;
}
//区间的划分
int keyi = PartSort1(a, begin, end);
//将整个数据划分为[begin, keyi-1] keyi [keyi+1, end]
//递归右区间
QuickSort(a, begin, keyi - 1);
//递归左区间
QuickSort(a, keyi + 1, end);
}
void PrintArry(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
void TestQuickSort()
{
int a[] = { 3,2,5,10,6,8,9,7,1,4 };
QuickSort(a, 0, sizeof(a) / sizeof(int) - 1);
PrintArry(a, sizeof(a) / sizeof(int));
}
int main()
{
TestQuickSort();
return 0;
}1.1.2挖坑法
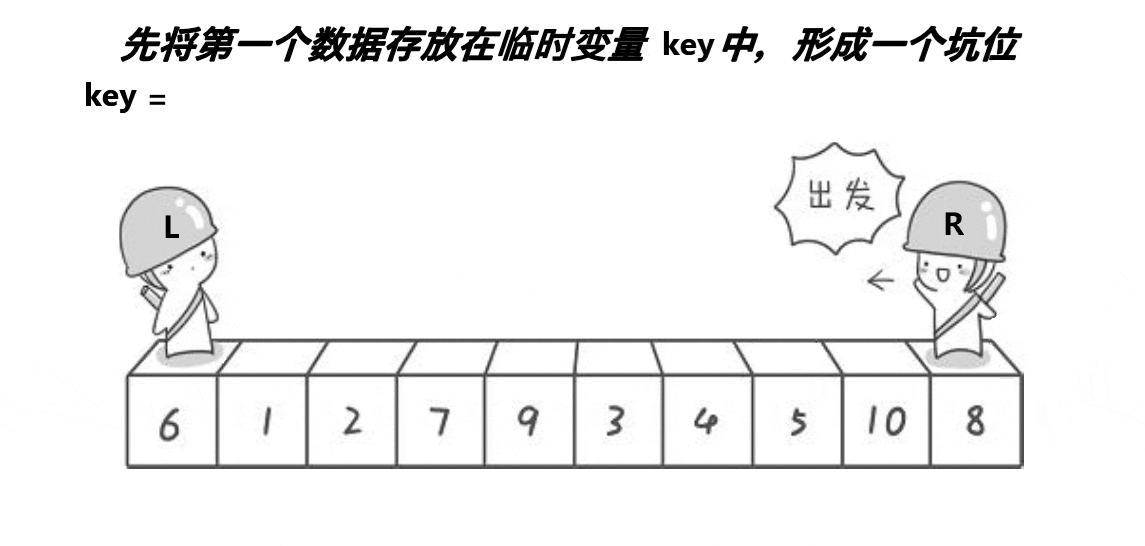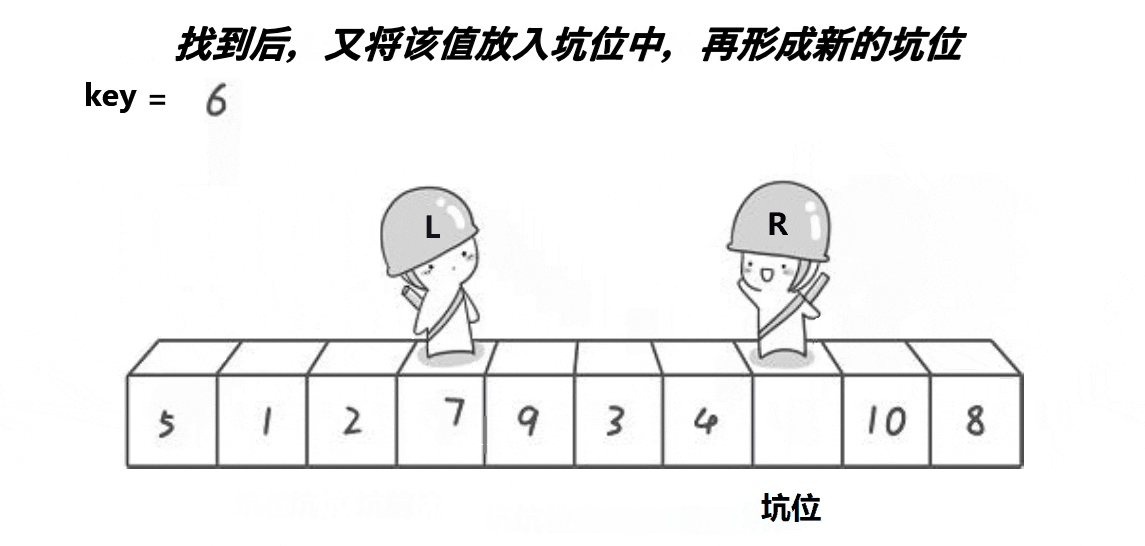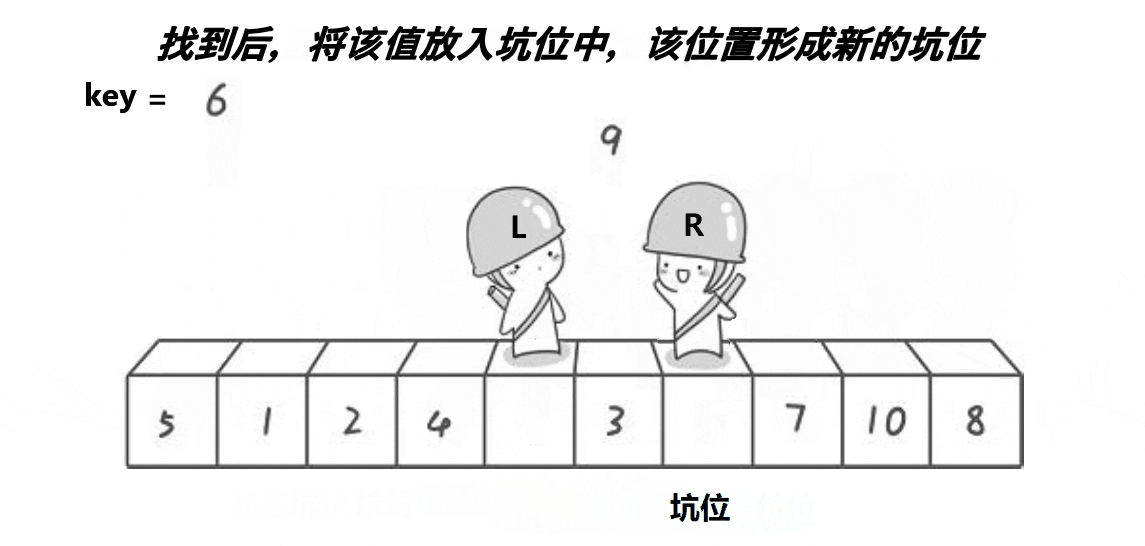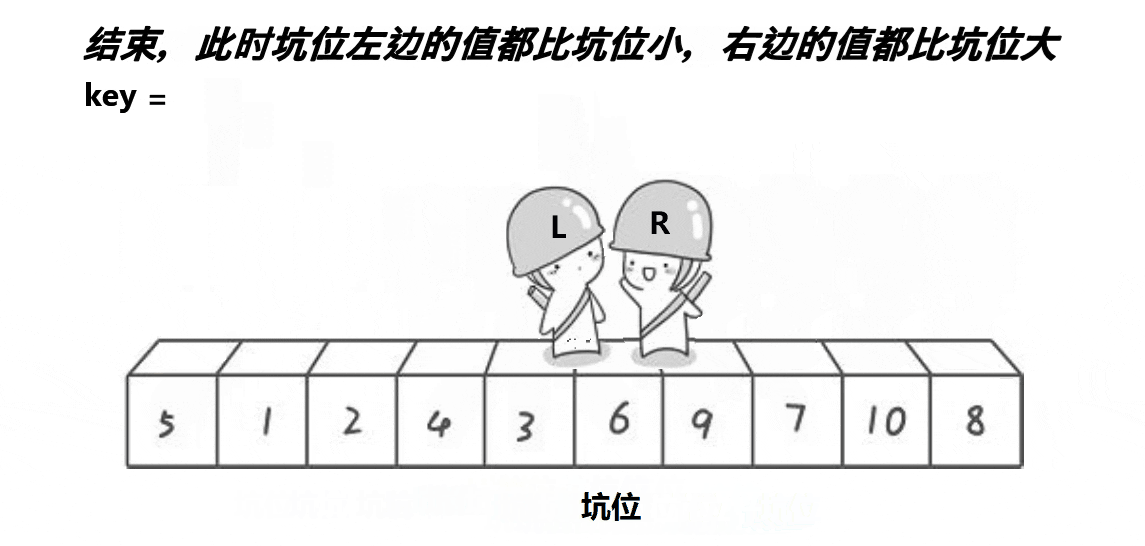
由于hoare版本的方法需要注意左右下标出发的先后顺序,那么就针对这一问题,有了一种新的方法:挖坑法
同样的还是将最左边的数据作为关键数据,并且将它先保存,然后将这个位置设置为坑,然后设置左右两个下标,由于左边有坑,所以右下标先走,向前找比key小的值,找到了之后将这个值放在坑中,然后这个值的位置就形成了新的坑,然后左下标开始向后找比key大的,找到了之后将这个值放在新的坑中,此时又形成了一个坑,继续重复这个过程,当左右下标重叠时,再将刚开始保存的key放在这个坑中,即可完成一次排序,然后关键数据的这个位置又将数据分为两个区间,然后使用递归继续排序左右区间。
代码演示:
// 2. 挖坑法
int PartSort2(int* a, int left, int right)
{
//保存关键值
int key = a[left];
//设置坑
int hole = left;
//一次排序
while (left < right)
{
//右边找小
while (left < right && a[right] > key)
{
right--;
}
//找到了将其放入坑中,然后更新坑的位置
a[hole] = a[right];
hole = right;
//左边找大
while (left < right && a[left] < key)
{
left++;
}
a[hole] = a[left];
hole = left;
}
//最后把关键数据再放到坑中
a[hole] = key;
key = right;
return key;
}
void QuickSort(int* a, int begin, int end)
{
//递归截止条件
if (begin >= end)
{
return;
}
//区间的划分
int keyi = PartSort2(a, begin, end);
//将整个数据划分为[begin, keyi-1] keyi [keyi+1, end]
//递归右区间
QuickSort(a, begin, keyi - 1);
//递归左区间
QuickSort(a, keyi + 1, end);
}1.1.3前后指针(下标)版本

同样的还是取最左边作为关键数据,然后设置两个下标,一个指向起始位置(prev),一个指向起始位置的后一个位置(cur),然后比较cur指向的数据与key的大小,若cur小于key,则prev++,并且prev指向的数据和cur指向的数据进行交换(如果prev和cur指向的时同一个数据那么便不用交换),然后cur++,如果cur指向的数据大于key,则cur++,当cur越界时,将prev指向的数据和key交换,这时prev指向的位置就可以作为新的key将整个数据分为两个区间,这时就可使用递归继续来排序它的左右区间。
代码演示:
// 3.前后指针版本
int PartSort3(int* a, int left, int right)
{
//设置关键数据
int keyi = left;
//前后指针(下标)
int prev = left;
int cur = left + 1;
//判断cur的合法性
while (cur <= right)
{
//如果cur指的数据小于关键数据且prev不等于cur即可完成交换
if (a[cur] < a[keyi] && ++prev != cur)
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
//cur越界之后再次交换prev与key
Swap(&a[keyi], &a[prev]);
keyi = prev;
//返回新的关键位置
return keyi;
}
void QuickSort(int* a, int begin, int end)
{
//递归截止条件
if (begin >= end)
{
return;
}
//区间的划分
int keyi = PartSort3(a, begin, end);
//将整个数据划分为[begin, keyi-1] keyi [keyi+1, end]
//递归右区间
QuickSort(a, begin, keyi - 1);
//递归左区间
QuickSort(a, keyi + 1, end);
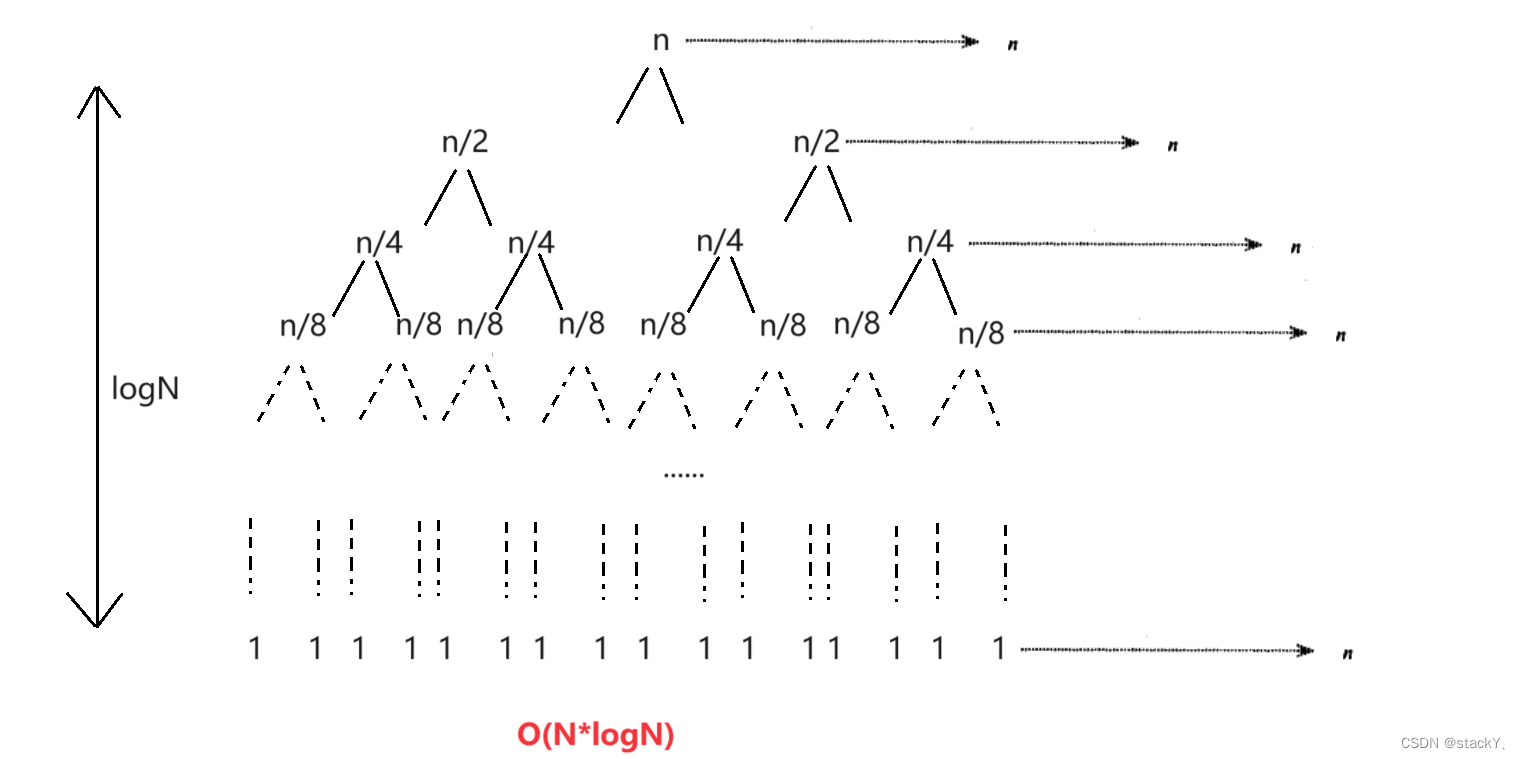
}1.1.4时间复杂度
快速排序的递归版本与二叉树学习中的前序遍历逻辑相似,只需要注意区间的划分,那么根据二叉树的递归,一共需要递归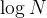 次,每一次进行遍历排序需要N次,那么快速排序的时间复杂度是:O(
次,每一次进行遍历排序需要N次,那么快速排序的时间复杂度是:O(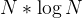 ) ,但是计算时间复杂度是按照最坏情况来考虑,当一组数据是有序的情况再来使用快速排序来排序这时它的时间复杂度就会变为O(N^2),这时递归就需要N次,每一次的遍历也需要N次,所以就是N^2,因为我们每一次取到的关键数据都是左边的数据,那么就需要对如何取关键数据进行改进。
) ,但是计算时间复杂度是按照最坏情况来考虑,当一组数据是有序的情况再来使用快速排序来排序这时它的时间复杂度就会变为O(N^2),这时递归就需要N次,每一次的遍历也需要N次,所以就是N^2,因为我们每一次取到的关键数据都是左边的数据,那么就需要对如何取关键数据进行改进。
1.1.5快速排序的优化
为了优化快速排序最坏情况下的时间复杂度,那么我们需要对快速排序如何选择key做出改进:
我们采用的是三数取中选key:
选出最左边的数(left)、最右边的数(right)、中间数据(mid)这三个数据中大小顺序位于中间的数据作为key,然后与最左边的数进行交换,这样就达到了优化。
优化完整代码:
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//三数取中选key
int GetMidIndex(int* a, int left, int right)
{
int mid = left + (right - left) / 2;
if (a[left] < a[mid])
{
if (a[right] > a[mid])
{
return mid;
}
else if (a[right] < a[left])
{
return left;
}
else
return right;
}
else
{
if (a[right] < a[mid])
{
return mid;
}
else if (a[right] > a[left])
{
return left;
}
else
return right;
}
}
// 1. hoare版本
int PartSort1(int* a, int left, int right)
{
//设置关键字
int midi = GetMidIndex(a, left, right);
Swap(&a[left], &a[midi]);
int keyi = left;
while (left < right)
{
//右边先走
//找比key小的
while (left < right && a[keyi] <= a[right]) //先得判断下标是否合理
{
right--;
}
//找比key大的
while (left < right && a[keyi] >= a[left])
{
left++;
}
//交换
Swap(&a[left], &a[right]);
}
//交换重叠位置的数据和key
Swap(&a[keyi], &a[right]);
//将重叠位置返回
return right;
}
// 2. 挖坑法
int PartSort2(int* a, int left, int right)
{
int midi = GetMidIndex(a, left, right);
Swap(&a[left], &a[midi]);
//保存关键值
int key = a[left];
//设置坑
int hole = left;
//一次排序
while (left < right)
{
//右边找小
while (left < right && a[right] > key)
{
right--;
}
//找到了将其放入坑中,然后更新坑的位置
a[hole] = a[right];
hole = right;
//左边找大
while (left < right && a[left] < key)
{
left++;
}
a[hole] = a[left];
hole = left;
}
//最后把关键数据再放到坑中
a[hole] = key;
key = right;
return key;
}
// 3.前后指针版本
int PartSort3(int* a, int left, int right)
{
int midi = GetMidIndex(a, left, right);
Swap(&a[left], &a[midi]);
//设置关键数据
int keyi = left;
//前后指针(下标)
int prev = left;
int cur = left + 1;
//判断cur的合法性
while (cur <= right)
{
//如果cur指的数据小于关键数据且prev不等于cur即可完成交换
if (a[cur] < a[keyi] && ++prev != cur)
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
//cur越界之后再次交换prev与key
Swap(&a[keyi], &a[prev]);
keyi = prev;
//返回新的关键位置
return keyi;
}
void QuickSort(int* a, int begin, int end)
{
//递归截止条件
if (begin >= end)
{
return;
}
//区间的划分
int keyi = PartSort3(a, begin, end);
//将整个数据划分为[begin, keyi-1] keyi [keyi+1, end]
//递归右区间
QuickSort(a, begin, keyi - 1);
//递归左区间
QuickSort(a, keyi + 1, end);
}优化过后快速排序的时间复杂度最坏的情况下也是O(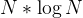 )
)
1.2非递归版本
由于递归存在风险,递归太深会出现问题,所以我们需要写出快速排序的非递归版本,快速排序的递归版本跟二叉树的前序遍历逻辑相似,那么在非递归版本中我们需要借助一个数据结构来完成非递归版本的快速排序。
在之前的数据结构中我们学到了一个叫栈的数据结构,它的特点就是先进后出,因此我们可以借助于栈来实现快速排序的非递归版本。
在递归的版本中我们通过第一次排序整个区间然后取得一个关键值的位置,通过这个关键值将数据再次分为两个区间,然后依次递归继续排序这两个区间,并且在这两个区间内会再次划分区间,直到全部排序完毕。根据这个特点我们也可以根据栈的特性来进行实现,首先我们创建一个栈,然后先将0存放在栈中,再将9存放在栈中,那么就可以通过0和9来访问数据了,如果栈不为空,我们就取栈顶的元素9作为右下标,然后将其移除,再取栈顶元素0作为左下标,然后经过一次排序,得到了新的关键值,那么这个关键值会将区间分为两个部分,前面的部分是[left,keyi-1],后面的部分是[keyi+1,right],这时就需要对区间的合法性做出判断,如果left小于keyi-1,那么区间合理,可以继续将left作为左下标,将keyi-1作为右下标继续排序,如果right>keyi+1,那么区间合理,可以继续将keyi+1作为左下标,将right作为右下标继续排序,如果两个条件都不满足那么表示排序完成。
代码演示:
// 1. hoare版本
int PartSort1(int* a, int left, int right)
{
//设置关键字
int midi = GetMidIndex(a, left, right);
Swap(&a[left], &a[midi]);
int keyi = left;
while (left < right)
{
//右边先走
//找比key小的
while (left < right && a[keyi] <= a[right]) //先得判断下标是否合理
{
right--;
}
//找比key大的
while (left < right && a[keyi] >= a[left])
{
left++;
}
//交换
Swap(&a[left], &a[right]);
}
//交换重叠位置的数据和key
Swap(&a[keyi], &a[right]);
//将重叠位置返回
return right;
}
//快速排序的非递归版本
void QuickSortNonR(int* a, int begin, int end)
{
//创建栈
Stack st;
StackInit(&st);
//先将整个区间放入栈
StackPush(&st, begin);
StackPush(&st, end);
//进行排序
while (!StackEmpty(&st))
{
//取栈顶元素作为右下标
int right = StackTop(&st);
//删除栈顶元素
StackPop(&st);
//取栈顶元素作为左下标
int left = StackTop(&st);
//删除栈顶元素
StackPop(&st);
//进行一次排序
int keyi = PartSort1(a, left, right);
//对获得的keyi是否合理进行判断
if (left < keyi - 1)
{
//重新将新的区间放入栈中
//注意:顺序不能交换
StackPush(&st, left);
StackPush(&st, keyi - 1);
}
if (right > keyi + 1)
{
//重新将新的区间放入栈中
//注意:顺序不能交换
StackPush(&st, keyi + 1);
StackPush(&st, right);
}
}
StackDestroy(&st);
}注意:这里的先放左区间和先放右区间跟后面的代码是要呼应的,顺序不能随便更改。
在这里我就不展示栈接口的代码了,大家可以去栈和队列 这一篇博客找源码。
快速排序的特性总结:
1. 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(logN)
4. 稳定性:不稳定
朋友们、伙计们,美好的时光总是短暂的,我们本期的的分享就到此结束,最后看完别忘了留下你们弥足珍贵的三连喔,感谢大家的支持!
标签:的博客
- 上一篇:一文了解VR全景,VR全景有哪些优势?
- 下一篇:常用排序算法
- 程序开发学习排行
- 最近发表
-
- WordPress随机显示特色图片插件:Random Post Thumbnails
- KeePass实现Chrome浏览器自动填充密码方法一
- LNMP一键包nginx 301强制跳转到https教程
- KeePass实现Chrome浏览器自动填充密码方法二
- #建站# 免费的VPS管理软件Xshell8/Xftp8中文版下载
- 使用Xshell 8连接VPS教程_电脑登录vps的方法
- WordPress评论界面添加烟花????效果
- 不同浏览器书签同步方案:坚果云+Floccus_详细使用教程
- iOS端KeePassXC客户端APP:Strongbox Password Safe
- 给WordPress评论中的Gravatar头像图片添加ALT属性