

AIGC:【LLM(七)】——Baichuan2:真开源可商用的中文大模型
作者:小教学发布时间:2023-09-25分类:程序开发学习浏览:342
文章目录
- 一.模型介绍
- 二.模型部署
- 2.1 CPU部署
- 2.2 GPU部署
- 三.模型推理
- 3.1 Chat 模型推理
- 3.2 Base 模型推理
- 四.模型量化
- 4.1 量化方法
- 4.2 在线量化
- 4.3 离线量化
- 4.4 量化效果
- 五.模型微调
- 5.1 依赖安装
- 5.2 单机训练
- 5.3 多机训练
- 5.4 轻量化微调
一.模型介绍
Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。其在多个权威的中文、英文和多语言的通用、领域 benchmark 上取得同尺寸最佳的效果。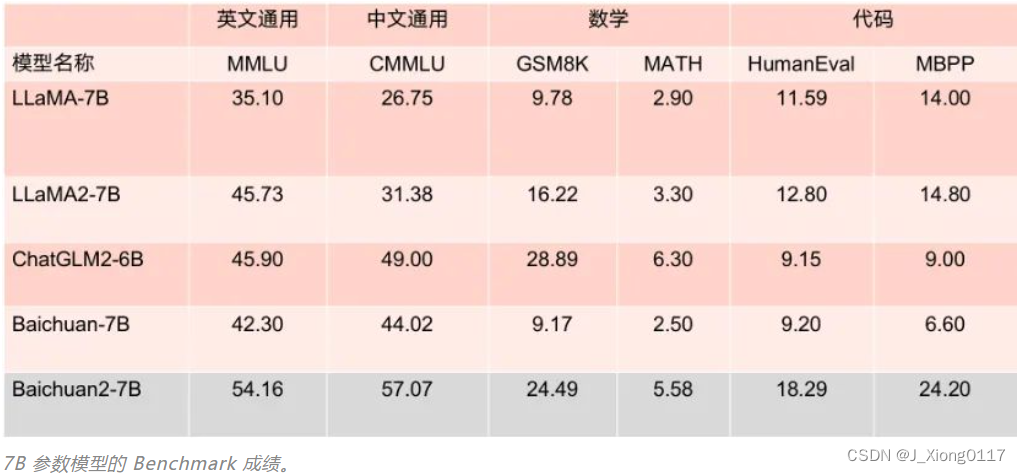
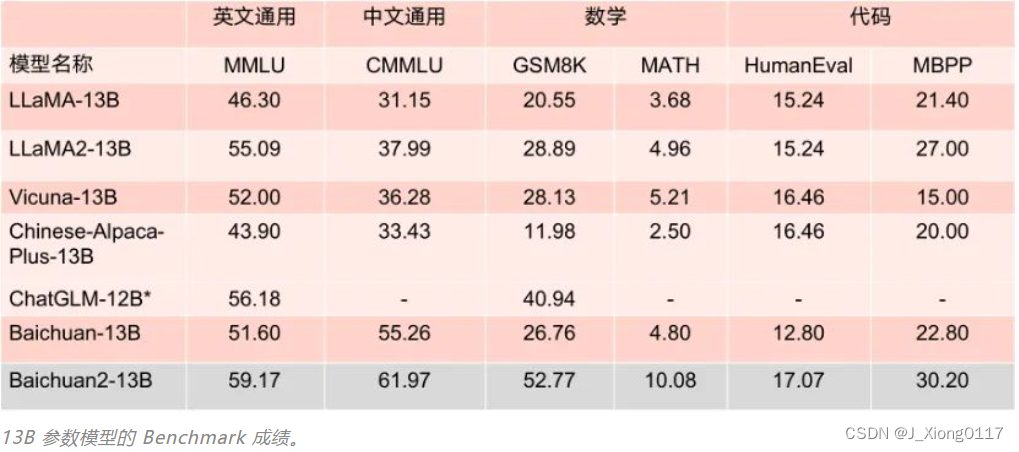
目前开源发布的包含有 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。所有版本对学术研究完全开放。同时,开发者通过邮件申请并获得官方商用许可后,即可免费商用。
下载链接:
【Baichuan2-7B-Base】:https://huggingface.co/baichuan-inc/Baichuan2-7B-Base
【Baichuan2-13B-Base】:https://huggingface.co/baichuan-inc/Baichuan2-13B-Base
【Baichuan2-7B-Chat】:https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat
【Baichuan2-13B-Chat】:https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat
【Baichuan2-7B-Chat-4bits】:https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat-4bits
【Baichuan2-13B-Chat-4bits】:https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits
除了模型的全面公开之外,百川智能还开源了模型训练的 Check Point,并公开了 Baichuan 2 技术报告,详细介绍了模型的训练细节。
【代码仓库】:https://github.com/baichuan-inc/Baichuan2
【技术报告】:https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
二.模型部署
2.1 CPU部署
Baichuan 2 模型支持 CPU 推理,但需要强调的是,CPU 的推理速度相对较慢。需按如下方式修改模型加载的方式。
# Taking Baichuan2-7B-Chat as an example
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float32, trust_remote_code=True)
2.2 GPU部署
依靠 streamlit 运行以下命令,会在本地启动一个 web 服务,把控制台给出的地址放入浏览器即可访问。
streamlit run web_demo.py
三.模型推理
3.1 Chat 模型推理
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> from transformers.generation.utils import GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", use_fast=False, trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
>>> model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan2-13B-Chat")
>>> messages = []
>>> messages.append({"role": "user", "content": "解释一下“温故而知新”"})
>>> response = model.chat(tokenizer, messages)
>>> print(response)
"温故而知新"是一句中国古代的成语,出自《论语·为政》篇。这句话的意思是:通过回顾过去,我们可以发现新的知识和理解。换句话说,学习历史和经验可以让我们更好地理解现在和未来。
这句话鼓励我们在学习和生活中不断地回顾和反思过去的经验,从而获得新的启示和成长。通过重温旧的知识和经历,我们可以发现新的观点和理解,从而更好地应对不断变化的世界和挑战。
3.2 Base 模型推理
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Base", trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Base", device_map="auto", trust_remote_code=True)
>>> inputs = tokenizer('登鹳雀楼->王之涣\n夜雨寄北->', return_tensors='pt')
>>> inputs = inputs.to('cuda:0')
>>> pred = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1)
>>> print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
登鹳雀楼->王之涣
夜雨寄北->李商隐
四.模型量化
为了让不同的用户以及不同的平台都能运行 Baichuan 2 模型,百川智能针对 Baichuan 2 模型做了相应地量化工作(包括 Baichuan2-7B-Chat 和 Baichuan2-13B-Chat),方便用户快速高效地在自己的平台部署 Baichuan 2 模型。
4.1 量化方法
Baichuan 2 的采用社区主流的量化方法:BitsAndBytes。该方法可以保证量化后的效果基本不掉点,目前已经集成到 transformers 库里,并在社区得到了广泛应用。BitsAndBytes 支持 8bits 和 4bits 两种量化,其中 4bits 支持 FP4 和 NF4 两种格式,Baichuan 2 选用 NF4 作为 4bits 量化的数据类型。基于该量化方法,Baichuan 2 支持在线量化和离线量化两种模式。
4.2 在线量化
对于在线量化, Baichuan 2支持 8bits 和 4bits 量化,使用只需要先加载模型到 CPU 的内存里,再调用quantize()接口量化,最后调用 cuda()函数,将量化后的权重拷贝到 GPU 显存中。实现整个模型加载的代码非常简单,以 Baichuan2-7B-Chat 为例:
8bits 在线量化:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(8).cuda()
4bits 在线量化:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(4).cuda()
需要注意的是,在用 from_pretrained 接口的时候,用户一般会加上 device_map=“auto”,在使用在线量化时,需要去掉这个参数,否则会报错。
4.3 离线量化
为了方便用户的使用,Baichuan2提供了离线量化好的 4bits 的版本 Baichuan2-7B-Chat-4bits,供用户下载。 用户加载 Baichuan2-7B-Chat-4bits 模型很简单,只需要执行:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat-4bits", device_map="auto", trust_remote_code=True)
对于 8bits 离线量化,Hugging Face transformers 库提供了相应的 API 接口,可以很方便的实现 8bits 量化模型的保存和加载。用户可以自行按照如下方式实现 8bits 的模型保存和加载:
# Model saving: model_id is the original model directory, and quant8_saved_dir is the directory where the 8bits quantized model is saved.
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_8bit=True, device_map="auto", trust_remote_code=True)
model.save_pretrained(quant8_saved_dir)
model = AutoModelForCausalLM.from_pretrained(quant8_saved_dir, device_map="auto", trust_remote_code=True)
4.4 量化效果
量化前后显存占用对比 (GPU Mem in GB):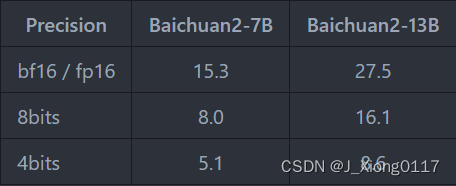
量化后在各个 benchmark 上的结果和原始版本对比如下: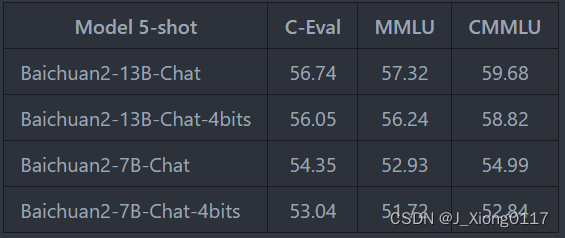
五.模型微调
5.1 依赖安装
git clone https://github.com/baichuan-inc/Baichuan2.git
cd Baichuan2/fine-tune
pip install -r requirements.txt
- 如需使用 LoRA 等轻量级微调方法需额外安装 peft
- 如需使用 xFormers 进行训练加速需额外安装 xFormers
5.2 单机训练
下面是一个微调 Baichuan2-7B-Base 的单机训练例子。
训练数据:data/belle_chat_ramdon_10k.json,该样例数据是从 multiturn_chat_0.8M 采样出 1 万条,并且做了格式转换。主要是展示多轮数据怎么训练,不保证效果。
hostfile=""
deepspeed --hostfile=$hostfile fine-tune.py \
--report_to "none" \
--data_path "data/belle_chat_ramdon_10k.json" \
--model_name_or_path "baichuan-inc/Baichuan2-7B-Base" \
--output_dir "output" \
--model_max_length 512 \
--num_train_epochs 4 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 1 \
--save_strategy epoch \
--learning_rate 2e-5 \
--lr_scheduler_type constant \
--adam_beta1 0.9 \
--adam_beta2 0.98 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--logging_steps 1 \
--gradient_checkpointing True \
--deepspeed ds_config.json \
--bf16 True \
--tf32 True
5.3 多机训练
多机训练只需要给一下 hostfile ,内容类似如下:
ip1 slots=8
ip2 slots=8
ip3 slots=8
ip4 slots=8
....
同时在训练脚本里面指定 hosftfile 的路径:
hostfile="/path/to/hostfile"
deepspeed --hostfile=$hostfile fine-tune.py \
--report_to "none" \
--data_path "data/belle_chat_ramdon_10k.json" \
--model_name_or_path "baichuan-inc/Baichuan2-7B-Base" \
--output_dir "output" \
--model_max_length 512 \
--num_train_epochs 4 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 1 \
--save_strategy epoch \
--learning_rate 2e-5 \
--lr_scheduler_type constant \
--adam_beta1 0.9 \
--adam_beta2 0.98 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--logging_steps 1 \
--gradient_checkpointing True \
--deepspeed ds_config.json \
--bf16 True \
--tf32 True
5.4 轻量化微调
代码已经支持轻量化微调如 LoRA,如需使用仅需在上面的脚本中加入以下参数:
--use_lora True
LoRA 具体的配置可见 fine-tune.py 脚本。使用 LoRA 微调后可以使用下面的命令加载模型:
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained("output", trust_remote_code=True)
- 程序开发学习排行
- 最近发表
-
- WordPress随机显示特色图片插件:Random Post Thumbnails
- KeePass实现Chrome浏览器自动填充密码方法一
- LNMP一键包nginx 301强制跳转到https教程
- KeePass实现Chrome浏览器自动填充密码方法二
- #建站# 免费的VPS管理软件Xshell8/Xftp8中文版下载
- 使用Xshell 8连接VPS教程_电脑登录vps的方法
- WordPress评论界面添加烟花????效果
- 不同浏览器书签同步方案:坚果云+Floccus_详细使用教程
- iOS端KeePassXC客户端APP:Strongbox Password Safe
- 给WordPress评论中的Gravatar头像图片添加ALT属性